
by Ross McKitrick
I sat down to write a description of my new paper with John Christy, but when I looked up a reference via Google Scholar something odd cropped up that requires a brief digression.
Google Scholar insists on providing a list of “recommended” articles whenever I sign on to it. Most turn out to be unpublished or non-peer reviewed discussion papers. But at least they are typically current, so I was surprised to see the top rank given to “Consistency of Modelled and Observed Temperature Trends in the Tropical Troposphere,” a decade-old paper by Santer et al. Google was, however, referring to its reappearance as a chapter in a 2018 book called Climate Modelling: Philosophical and Conceptual Issuesedited by Elizabeth Lloyd and Eric Winsberg, two US-based philosophers. Lloyd specifically describes herself as “a philosopher of climate science and evolutionary biology, as well as a scientist studying women’s sexuality” so readers should not expect specialized expertise in climate model evaluation, nor does the book’s editors exhibit any. Yet Google’s algorithm flagged it for me as the best thing out there and positioned two of its chapters as top leads in its “recommended” list.
Much of the first part of the book is an extended attack on a 2007 paper by David Douglass, John Christy, Benjamin Pearson and Fred Singer on the model/observational mismatch in the tropical troposphere. The editors add a diatribe against John Christy in particular for supposedly being impervious to empirical evidence, using flawed statistical methods and refusing to accept the validity of climate model representations of the warming of the tropical troposphere.
By way of contrast, and as an exemplar of research probity, they reproduce the decade-old Santer et al. paper and rely entirely on it for their case. If they are aware of any subsequent literature (which I doubt) they don’t mention it. They fail to mention:
- Santer bitterly foughtreleasing his data
- Despite having data up to 2007 he truncated his sample at 1999
- If he had used the same methodology on the full data set he’d have reached the opposite conclusion, supporting Douglass et al. rather than supposedly refuting them
- Steve McIntyre and I submitteda comment to the journal showing this. It was rejected, in part because the referee considered Santer’s statistical method invalid and didn’t want it perpetuated through further discussion
- We re-cast the article as a more detailed discussion of trend comparison methodology and published it in 2010 in Atmospheric Science Letters. We confirmed, among other things, that based on modern econometric testing methods the gap between models and observations in the tropical troposphere is statistically significant.
McKitrick and Vogelsang (2014)provided a longer model-observational comparison using radiosonde records from 1958 to 2012 while generalizing the trend model to include a possible step change, and reaffirmed the significant discrepancy between models and observations. Similar conclusions were also reached by Fu et al. (2011), Bengtsson and Hodges (2009)and Po-Chedley and Fu (2012).
Needless to say you learn none of this in the Lloyd and Winsburg book.
A related issue is the ratio of tropospheric to surface warming. Klotzbach et al. (2009)found that climate models predict an average amplification ratio of about 1.2 between surface and tropospheric trends, but this far exceeded the observed average, which is typically less than 1.0. Critics said they should have used a different ratio between oceans and land, so Klotzbach et al. (2010)used 1.1 over land and 1.6 over oceans, which didn’t change their conclusions.
Vogelsang and Nawaz (2017)is an important new contribution to this literature since they provide the first formal treatment of the trend ratio problem. They note that there are several seemingly identical ways to write out the trend ratio regression but they each imply different estimators, one of which is systematically biased. They identify a preferred method (which corresponds to the form used by Klotzbach et al.) and they provide a practical method for constructing valid confidence intervals robust to general forms of autocorrelation.
They then use the Klotzbach et al. data sets (original and updated) and test whether the typical amplification ratios in climate models are consistent with observations. In almost all global surface/troposphere data pairings, the amplification ratios in models are too large and are rejected against the observations. When the testing is done separately for land and ocean regions the rejections are unanimous.
So: whether we test the tropospheric trend magnitudes, or the ratio of tropospheric to surface trends, across all kinds of data sets, and across all major trend intervals, models have been shown to exaggerate the amplification rate and the warming rate, globally and in the tropics.
Philosophers Elizabeth Lloyd and Eric Winsberg sound very smug and confident as they disparage people like John Christy and his coauthors and colleagues. Yet they clearly don’t know the literature, and they instead reveal that they are the ones who are impervious to empirical evidence, enamoured with flawed statistical methods and uncritical in their acceptance of biased climate model outputs.
Moving on.
John and I have published a new paper in Earth and Space Sciencethat adds to the climate model evaluation literature, using tropical mid-troposphere trend comparisons (models versus observations) as a basis to make a more general point about models. For a model to be scientific it ought to have an underlying testable hypothesis. Large, complex models like GCMs embed countless minor hypotheses that can be tested and rejected without undermining the major structure of the model. For instance, if a GCM does a lousy job of reproducing rainfall patterns over the Amazon, that component could be modified or removed without the model ceasing to be a GCM. But there must be at least one major component that, in principle, were it to be falsified, would call into question such an essential component of the model structure that you couldn’t simply remove it without changing the overall model type.
The hypothesis we are interested in testing is the representation of moist thermodynamics in the model troposphere that yields amplified warming in response to rising CO2 levels, thereby generating the results of most interest to users of GCMs, namely projections of global warming due to greenhouse gas emissions. We propose four criteria that a valid test must meet and we argue that the air temperature trend in the tropical 200-300 mb layer satisfies all four, pretty much uniquely as far as we know. That layer is where models exhibit the clearest and strongest response to greenhouse warming, on a rapid timetable, so it makes sense to focus on it as a test target. The four specific criteria are as follows.
- Measurability: The target must be well-measured over a long interval. Many surface regions like the Arctic and oceans are poorly sampled. Homogenized radiosonde records for the tropical troposphere are now available from more than one independent source over a 60 year span, which is long enough to identify relevant trends without undue influence of short-term events arising from internal variability or volcanic activity.
- Specificity: The phenomenon must reliably emerge in all models on a known time scale. It should not be possible to shield models endlessly from testing by appealing to pattern ambiguity or fuzzy time scales in model outputs. We looked at 102 CMIP5 runs of the tropical 200-300mb layer temperature series over 1958-2017 and they are very coherent on their prediction. 94 percent of the cross correlations exceed 0.5 and 77 percent exceed 0.6. The first principal component explains 73 percent of the variance and the remaining PCs each explain only minute amounts of variance. Also models project on average that about 2C warming should have happened by now, a magnitude well within observational capability. Hence models all predict one specific thing on a specific timetable.
- Independence: The target of the prediction must not be an input to the empirical tuning of the model. This rules out using the global average surface temperature record. Satellite-based lower- and mid-troposphere composites are also somewhat contaminated since they include the near-surface layer in their weighting functions. Radiosondes measure each layer of the atmosphere independently, so they are not inputs to tuning against the surface.
- Uniqueness: The causality behind the observed change should be uniquely tied to the measured phenomenon. If the model predicts that many things could cause the target to warm, an observed warming would be consistent both with a successful prediction and with a failed prediction coupled with the coincidental action of other causes. But the IPCC states that only greenhouse forcing would explain a strong historical warming trend in the target region. The presence of such a trend would thus have only one explanation; likewise, its absence would conflict with only one major hypothesis of the model, namely the set of parameterizations that yield amplified GHG-induced warming.
We took the annual 1958-2017 tropical 200-300mb layer average temperatures from three radiosonde data sets: RATPAC, RICH and RAOBCORE, and from all 102 runs in the CMIP5 archive. The model runs followed the RCP4.5 concentrations pathway, which follows observed GHG levels and other forcings up to the early part of the last decade then projections thereafter. We estimated linear trends using ordinary least squares and computed robust confidence intervals using the Vogelsang-Franses method. We generated results both for a simple trend and for one allowing a possible break in 1979 following the method outlined in McKitrick and Vogelsang (2014).
The trends (circles) and confidence intervals (whiskers) are shown here (models-red, observations-blue):
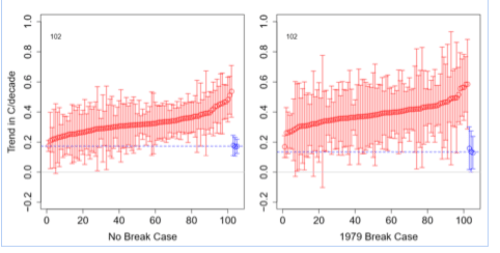
The mean restricted trend (without a break term) is C/decade in the models and C/decade in the observations. With a break term included they are, respectively, C/decade (models) and C/decade (observed).
In both cases, all 102 model trends exceed the average observed trend. In the restricted case (no break term), 62 of the discrepancies are significant, while in the general case 87 are. In both cases the model ensemble mean also rejects against observations.
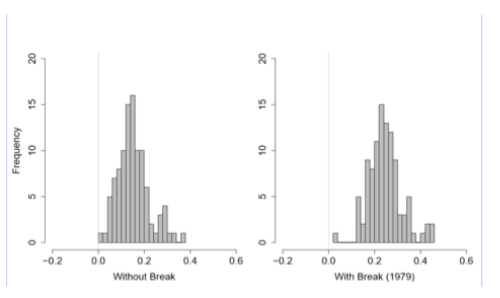
We also constructed divergence terms consisting of each model run minus the average balloon record. The histograms of trends in these measures ought to be centered on zero if the model errors were mere noise. Instead the distributions are entirely positive, indicating a systematic positive bias:
Conclusion
Summarizing, all 102 CMIP5 model runs warm faster than observations, in most individual cases the discrepancy is significant, and on average the discrepancy is significant. The test of trend equivalence rejects whether or not we include a break at 1979, though the rejections are stronger when we control for its influence. Measures of series divergence are centered at a positive mean and the entire distribution is above zero. While the observed analogue exhibits a warming trend over the test interval it is significantly smaller than that shown in models, and the difference is large enough to reject the null hypothesis that models represent it correctly.
To the extent GCMs are getting some features of the surface climate correct as a result of their current tuning, they are doing so with a flawed structure. If tuning to the surface added empirical precision to a valid physical representation, we would expect to see a good fit between models and observations at the point where the models predict the clearest and strongest thermodynamic response to greenhouse gases. Instead we observe a discrepancy across all runs of all models, taking the form of a warming bias at a sufficiently strong rate as to reject the hypothesis that the models are realistic. Our interpretation of the results is that the major hypothesis in contemporary climate models, namely the theoretically-based negative lapse rate feedback response to increasing greenhouse gases in the tropical troposphere, is flawed.
Paper:
- Ross McKitrick and John Christy (2018) A Test of the Tropical 200-300MB Warming Rate in Climate Models. Earth and Space Science1029/2018EA000401. Data/code archive available at rossmckitrick.com
Moderation note: As with all guest posts, please keep your comments civil and relevant.

There are some trend numbers missing 3 paragraphs above the conclusion.
Yes this is the statement:
The mean restricted trend (without a break term) is C/decade in the models and C/decade in the observations. With a break term included they are, respectively, C/decade (models) and C/decade (observed).
The trend numbers should have been: 0.33 +/- 0.13 C/decade in the models and 0.17 +/- 0.06 C/decade in the observations. With a break term included they are, respectively, 0.39 +/- 0.17 C/decade (models) and 0.14 +/- 0.12 C/decade (observed).
I note that the trends overlap. So your observed discrepancy is lacking.
Mr. McKitrick, will these sorts of studies affect development of CMIP6 models and/or the IPCC’s AR6 climate model discussions? Will you be allowed to review and constructively comment on CMIP6 models prior to their publication in AR6? Will you be allowed to submit your model vs. observation studies to the development of AR6 section(s) on model discussions?
Our new paper won’t affect existing AR6 drafts since it only just came out, but I hope the earlier papers in this literature are surveyed for the model evaluation chapter. MM&H2010 was cited in AR5 in the tropical troposphere section. I’ve been asked to sign up as a reviewer for AR6 but haven’t done so yet.
Please do sign up as an AR6 reviewer! IPCC downplaying the models’ inaccuracies is concerning.
Yes, I also hope you sign on as reviewer for AR6. Incremental progress!
The observations on Google’s algorithms are very troubling to the point of Orwellian.
Google is no longer an acceptable search engine. Over the years Ive used a certain search wording to find articles or papers I would show friends. In recent times they no longer appear and instead I’m shown items such as fluff from Vox, MSNBC, Scientific American, and other publications I know are controlled by a leftist political agenda. The same happens with Youtube. By the way, i just found out that Facebook is actively interfering in Brazil’s presidential campaign.
According to this paper, the surface warming pattern in the tropics has a big effect on the negative lapse rate feedback.
https://journals.ametsoc.org/doi/abs/10.1175/JCLI-D-17-0087.1
Note that if the models are overestimating the negative lapse rate feedback, they are underestimating the climate sensitivity.
Note that if the models are overestimating the negative lapse rate feedback, they are underestimating the climate sensitivity.
It’s probably true that reality has less lapse rate feedback than the models do.
But the lack of an upper warming maxima probably also means reduced water vapor feedback.
So models are probably still overestimating sensitivity.
The water vapor feedback depends most on the surface temperature and that is not a varying factor in this study. That is, for a given surface temperature change a reduced lapse rate feedback means more sensitivity. They have not said the surface temperature change differs.
The water vapor feedback depends most on the surface temperature and that is not a varying factor in this study.
No, I beleive that is incorrect.
Imagine water vapor increases, even by a huge amount, but all at the lowest 2 meters of the atmosphere and the levels above remain as they are.
In this case, more energy radiates upward from the lowest layer but little change in downward radiation from the upper layers, leading to a deficit of the net.
For such a case, increasing water vapor for just the surface actually causes a negative feedback!
In contrast, if water vapor increases, but mostly aloft, then less surface radiance makes it past the increased water vapor aloft, and more downward radiance from aloft shines down on the surface.
So the lack of the hot spot probably means reduced water vapor feedback though dynamics are obviously also a factor.
In the paper I linked (paywalled) the lapse rate effect exceeds the water vapor effect when the SST warming pattern is changed, so less lapse rate effect is more sensitivity.
Here’s the graphic that crazy Atom guy likes:
https://pbs.twimg.com/media/DgoC1w4X4AEdwdl.jpg
Water vapor feedback is mostly an upper tropospheric phenomenon.
No hot spot, no water vapor feedback, no wonder warming is moderate.
Not sure what you’re saying. The hot spot is related to the lapse rate feedback not the water vapor feedback. The water vapor feedback goes as the surface temperature, not the temperature profile.
“We force an Atmospheric General Circulation Model (AGCM) with patterns of observed sea surface-temperature (SST) change and those output from Atmosphere-Ocean GCM (AOGCM) climate change simulations to demonstrate a strong dependence of climate feedback on the spatial structure of surface temperature change. Cloud and lapse-rate feedbacks are found to vary the most, depending strongly on the pattern of tropical Pacific SST change.”
I never know what Jiminy is on about – but the patterns of Pacific SST are not nearly exclusively anthropogenic.
For a different approach. “Finally, we note that the Green’s function approach is potentially useful for other fields beyond the cloud feedback and low‐cloud cover. The Green’s function approach may be used to explain the dependence of tropical upper tropospheric temperature, global precipitation, and global noncloud feedbacks in response to SST anomaly patterns. The utility of the Green’s function approach for these fields could be topics of future research.” https://agupubs.onlinelibrary.wiley.com/doi/full/10.1002/2017MS001096
Re: “Here’s the graphic that crazy Atom guy likes:”
Another good illustration of the evidence-free nonsense that’s allowed on this website, as long as you’re a contrarian on mainstream climate science.
Re: “Water vapor feedback is mostly an upper tropospheric phenomenon.”
Water vapor feedback also occurs at the near-surface. And the image you cited does nothing to support your point. It’s an image for the troposphere, not the near-surface. I would know this, since I actually read the paper that image comes from, while you clearly did not. I suggest you actually read the sources I cite, before abusing those citations.
If you were going to access the near-surface, then you’d look at other papers, which show water vapor feedback at the near-surface. For example:
“Anthropogenic greenhouse forcing and strong water vapor feedback increase temperature in Europe”
Re: “No hot spot, no water vapor feedback,”
Wrong again, and you’ve corrected on this many times. The hot spot is a sign of the lapse rate feedback, not the water vapor feedback. The former is a negative feedback, and the latter is a positive one. That point is not that hard to grasp. For example, there’s lots of CO2-induced near-surface warming in deserts, with strong water vapor feedback yet no hot spot (since there’s relatively little tropospheric warming). I suggest you go do your homework on this:
“Observational evidence for desert amplification using multiple satellite datasets”
“Detection and analysis of an amplified warming of the Sahara Desert”
“Desert amplification in a warming climate”
“Mechanisms for stronger warming over drier ecoregions observed since 1979”
“Stronger warming amplification over drier ecoregions observed since 1979”
Hi, crazy atom guy.
Water vapor feedback also occurs at the near-surface. And the image you cited does nothing to support your point.
Look at the image. Do you know what feature is near 1000 mb?
Re: “Hi, crazy atom guy.”
*sigh*
More evidence-free nonsense that’s allowed on this website, as long as it comes from contrarian on mainstream climate science.
Re: “Do you know what feature is near 1000 mb?”
And it’s clear you still haven’t read the paper that image came from. You’re simply abusing an image you saw me post (here: https://judithcurry.com/2018/09/01/the-lure-of-incredible-certitude/#comment-879854), even though you didn’t bother to read the original paper.
When I cited that paper, I gave you it’s title, which is:
“An assessment of tropospheric water vapor feedback using radiative kernels”
So as I told you, the image is looking at the troposphere using satellites, not the near surface. Thus you were wrong when you used the paper to claim that:
“Water vapor feedback is mostly an upper tropospheric phenomenon.”
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-880977
I already cited a paper for you covering the near-surface. And if you’d bothered to read the paper you cited, then you’d know the caption for that figure says:
“Vertical profile of global-mean water vapor feedbacks (in units of W m–2 K–1) for AIRS-MLS observations from August 2004 to July 2016”
That, combined with the figure, indicates positive water vapor feedback in the upper troposphere. It’s amazing how you can cite that figure, and then contradict it by denying the positive vapor feedback in the upper troposphere.
Re: “Look at the image. Do you know what feature is near 1000 mb?”
You were already shown that the image covers water vapor feedback is the troposphere.
Next time, actually read the papers you cite, instead of misusing sources you never read.
“For decades, researchers have investigated the spatial and temporal characteristics of decadal variability in the Pacific over the past century and its influence on the ocean and atmospheric circulation, regional climate, and marine ecosystems. Using surface observations and differing metrics, several authors identified several “regime shifts” in the Pacific over the past century occurring in the mid-1920s, the mid-1940s, and in the late 1970s [Trenberth and Hurrell, 1994; Mantua et al., 1997; Zhang et al., 1997; Power et al., 1999]. The SST structure of Pacific decadal variability (PDV) is characterized by a broad triangular pattern in the tropical Pacific surrounded by opposite anomalies in the midlatitudes of the central and western Pacific Basin. In the late 1990s and early 2000s the Pacific transitioned to the cool La Niña-like phase of the oscillation [Chen et al., 2008; Burgman et al., 2008b;Jo et al., 2013]. This cool PDV pattern persisted until very recently, when a large pattern of warming expanded throughout much of the Northeast Pacific, indicating a possible shift back to the positive phase.” Model evidence for low-level cloud feedback driving persistent changes in atmospheric circulation and regional hydroclimate –
https://agupubs.onlinelibrary.wiley.com/doi/pdf/10.1002/2016GL071978
Yes of course it does Jiminy – in multidecadal patterns. Although I expect a ‘dragon-king’ rather than a simple transition between periodic regimes.
Seems irrelevant, but please yourself.
I did access Jiminy’s paper. “The Dependence of Global Cloud and Lapse Rate Feedbacks on the Spatial Structure of Tropical Pacific Warming’
Tropical Pacific SST has spatial and temporal structures. Jiminy certainly didn’t read the Burgmann et al 2017 paper – I doubt that he read his own reference. He likes to keep things in his own little patch.
This thread is about lapse rate changes over long periods. Not sure where your reference comes in on that.
The paucity of Jiminy’s understanding is not in question. We do know something about the spatial – and especially temporal – patterns of SST in the Pacific. Both instrumentally and in proxies.
https://agupubs.onlinelibrary.wiley.com/doi/full/10.1029/2009GL042239
https://journals.ametsoc.org/doi/10.1175/JCLI-D-12-00003.1
https://journals.ametsoc.org/doi/10.1175/JCLI-D-12-00003.1
https://www.nature.com/articles/nature01194
Or how about this for extremes.
https://www.clim-past.net/6/525/2010/
O)r instrumental over a number of variables.
https://www.esrl.noaa.gov/psd/enso/mei/
If you are other than tribally obtuse – you can eyeball Pacific regimes.
And if he had read his own reference he would know that they “force HadGEM2-A with monthly observed SST and sea-ice variations and all forcing agents (e.g. GHGs, aerosols etc.) for the 30yr period 1979-2008.”
SST in the tropical Pacific is a key climate parameter. And it varies over millennia.
Tell the post authors that, not me. They have completely neglected the tropical Pacific SST pattern which was the point of the paper I linked. The only important part for them is that it affects the lapse rate response.
The old tell it to the authors ploy. They are the ones with the gridded oceans and the Greens (?) function with the Taylor series expansion? Yes they are looking for AGW feedback – cloud and lapse rate. And find conflicting results depending on where on the planet you are and where the warm surface water is. But the eastern and central Pacific is where you get dramatic surface temperature variations over a good part of the tropics with upwelling water that has been hidden away in the turbulent abyss for a 1000 years.
I know, I know.
Re: “I would say that you regularly mistake “your” focus for “the” issue.”
No, it was literally what Geoff Sherrington said, as has been repeatedly said to you. No need for you to pretend otherwise, nor act as if it was just my focus:
“What observations reject zero, in the real atmosphere setting not in vitro. References.”
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881105
Re: “Reminding you […]”
That’s nice.
To repeat myself (https://judithcurry.com/2018/09/01/the-lure-of-incredible-certitude/#comment-880196):
I’ll ask you a direct question that pertains to what you’re supposed to be responding to; I’ll be more than happy to repeat the question as many times as it takes you to address it, no matter how many times you move the goalposts. The question is:
Question: Did the satellite-based tropospheric warming analysis I cited reject a zero trend?
And if you’re curious, the following source provides a useful explanation of why I’m responding to you in the way I am:
“Do not introduce new arguments while another argument has yet to be resolved.”
http://twentytwowords.com/a-flowchart-to-help-you-determine-if-youre-having-a-rational-discussion/
Jim D,
Not in the case where climate sensitivity is zero. Clearly, the models cited lack the ability to reject zero. Geoff.
The observations do reject zero, so you can’t complain if the models do too.
New to me. What observations reject zero, in the real atmosphere setting not in vitro. References.? Geoff
The temperature observations reject zero trend. Why would you reject a model where the forcing change explains that non-zero trend? A climate sensitivity of zero would be rejected based on observations.
Re: “New to me. What observations reject zero, in the real atmosphere setting not in vitro. References.”
It’s covered in peer-reviewed scientific papers that we both know you won’t read. For example:
https://media.springernature.com/m685/springer-static/image/art%3A10.1038%2Fs41598-017-02520-7/MediaObjects/41598_2017_2520_Fig1_HTML.jpg
[from: “Tropospheric warming over the past two decades”]
As is not uncommon, your references, though copious at times, have bugger all to do with the topic.
To ascribe warming to GHG requires an ability to discern between natural and anthropogenic effects. Can’t have ECS without subtracting natural from recent temperature series. Nobody can do this yet, so why do you claim observational evidence? Geoff.
Geoff, the energy imbalance is positive meaning that the forcing exceeds all the warming so far. The forcing is dominated by the GHG change, so the attribution of warming to anthropogenic factors is all of it and more in the pipeline. This much is not in doubt.
Re: “As is not uncommon, your references, though copious at times, have bugger all to do with the topic. To ascribe warming to GHG requires an ability to discern between natural and anthropogenic effects.”
Oh look, you’re moving the goal-posts in order to pretend that the evidence I cited has nothing to do with the topic. Sad.
You’re pretending that the issue was “discern[ing] between natural and anthropogenic effects”. That is not the case. The actual issue was whether the observations were sufficient for rejecting the claim that the trend was zero. You clearly said this:
“What observations reject zero, in the real atmosphere setting not in vitro. References.”
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881105
My source was clearly relevant, since it used the observations to reject the claim of a non-zero trend. So the source detected a non-zero trend. Since you didn’t want to own up to that fact, you shifted the topic from detection of a trend, to attribution of the trend. How sneaky. Did you actually think you were going to fool anyone with that?
Now, how about you actually address the cited evidence this time, instead of moving the goalposts in your failed attempts to dodge the evidence?
Atomsk’s Sanakan: You’re pretending that the issue was “discern[ing] between natural and anthropogenic effects”. That is not the case.
When has accurately accounting for multiple effects not been the issue?
Re: “When has accurately accounting for multiple effects not been the issue?”
The actual issue was whether the observations showed a non-zero trend (i.e. rejected a zero trend), not whether the trend was anthropogenic vs. natural. I clearly showed this with a direct quote, so there’s no need for you to pretend otherwise:
“What observations reject zero, in the real atmosphere setting not in vitro. References.”
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881105
I’m not interested in your usual tactic moving the goalposts to avoid addressing evidence on the topic at hand, as I’ve repeatedly told you:
https://judithcurry.com/2018/09/01/the-lure-of-incredible-certitude/#comment-880207
“Do not introduce new arguments while another argument has yet to be resolved.”
http://twentytwowords.com/a-flowchart-to-help-you-determine-if-youre-having-a-rational-discussion/
Atomsk’s Sanakan: The actual issue was whether the observations showed a non-zero trend (i.e. rejected a zero trend), not whether the trend was anthropogenic vs. natural. I clearly showed this with a direct quote, so there’s no need for you to pretend otherwise:
I would say that you regularly mistake “your” focus for “the” issue.
Reminding you that there are always multiple issues, might be something you think is “bad faith”, but I think it may be “bad faith” to pretend that regulating CO2 is not the main issue. Without that main issue, all this climate science would attract no more debate than the absorption and emission spectra of Xenon, or the question of whether Avogadro’s Number ought to be fixed and used in the definition of mass (as the speed of light has been fixed and used in the definition of length).
Jim, Atom,
For ECS to be non-zero, one has to observe and preferably replicate a temperate change that is driven by CO2 or GHG, under real atmospheric conditions.
There has been a temperature change. Show that it has been driven by CO2 and was not natural variation. You cannot, yet.
It is sad that the main plank of global warming has not been shown to exist. tt might exist, but that certainty that good science requires is absent.
You both seem complicit in spreading fairy stories about a matter with severe consequences from premature regulation and law. You should be ashamed, because you fail basic tests of scientific competence. What comfort do you derive from taking part in the latest bubble, joining the lst of people who rooted for the historic failures like the tulip mania, the heretic theory of witchcraft, the South seas bubble, the nuclear winter scare, the global cooling scare, the chemicals/cancer scare, the nuclear waste management scare, the GMO scare, Etc.
It takes suckers as participants to let these scares grow. Not a good scene to look back upon in retirement.
Hey, Grandad, what did you do to stop the latest trendy bubble?
Geoff
Re: “For ECS to be non-zero […]”
That’s nice.
You said:
“What observations reject zero, in the real atmosphere setting not in vitro. References.”
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881105
I’ll ask you 2 direct questions that pertain to what you’re supposed to be responding to; I’ll be more than happy to repeat the questions as many times as it takes you to address them, no matter how many times you move the goalposts. The questions are:
1) Question: Do admit that the satellite-based tropospheric warming analysis I cited reject a zero trend?
If you’re confused, then here’s where I cited the analysis:
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881346
2Question: Do you admit that my reference was pertinent to what I quoted you saying above, and thus you were wrong when you said this?:
“As is not uncommon, your references, though copious at times, have bugger all to do with the topic.”
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881365
And if you’re curious, the following source provides a useful explanation of why I’m responding to you in the way I am:
“Do not introduce new arguments while another argument has yet to be resolved.”
http://twentytwowords.com/a-flowchart-to-help-you-determine-if-youre-having-a-rational-discussion/
Reblogged this on Quaerere Propter Vērum.
I can never get past the lack of any justifiable rationale for choosing any of the 102 model runs in the CMIP ensemble of opportunity . A posteriori solution behavior seems to hit the nail on the head.
“Lorenz was able to show that even for a simple set of nonlinear equations (1.1), the evolution of the solution could be changed by minute perturbations to the initial conditions, in other words, beyond a certain forecast lead time, there is no longer a single, deterministic solution and hence all forecasts must be treated as probabilistic.”
http://rsta.royalsocietypublishing.org/content/369/1956/4751
“The bases for judging are a priori formulation, representing the relevant natural processes and choosing the discrete algorithms, and a posteriori solution behavior.” http://www.pnas.org/content/104/21/8709
This purports to show the potential for greater warming than in CMIP ensembles of opportunity inferred from a perturbed physics ensemble.
https://watertechbyrie.files.wordpress.com/2018/05/rowlands-2012-add.png
https://www.nature.com/articles/ngeo1430
Problem is what solution of 1000’s generated from different initial conditions do you send to the CMIP? The thick black line is my choice.
“For a model to be scientific it ought to have an underlying testable hypothesis. …But there must be at least one major component that, in principle, were it to be falsified, would call into question such an essential component of the model structure that you couldn’t simply remove it without changing the overall model type.”
That would change the game. Hence the efforts to dismiss the significance of Karl Popper’s insight about falsification. Discussions about core principles are complex, hence your natural frustration (“I’m considering putting ‘Popper’ on my list of proscribed words.”)
https://climateaudit.org/2016/01/05/update-of-model-observation-comparisons/#comment-765766
A solution to the deadlocked debate about models is to test them: run models used in TAR and AR4 using observed emissions data from after their date of creation (i.e., out of sample data, so no possibility of tuning). Match the predicted global temps vs. actuals. Details: https://fabiusmaximus.com/2015/09/24/scientists-restart-climate-change-debate-89635/
Predictions are the gold standard of science. The cost would be significant but trivial compared to the value of the result.
Doing this for the model used in Hansen 1988 would be helpful. But Hargreaves 2010 said “efforts to reproduce the original model runs have not yet been successful.”
The problem may be that there is no deterministic, unique solution yet people continue to waffle on as if they believe there is.
The problem is that while there probably is a deterministic, unique solution; it is currently, and for the foreseeable future, beyond the bandwidth of naked apes.
Well the planet will do what it wants – and the models have a hard time even following.
Re: “That explanation was disputed by Hausfather. He might be right. I am eager to see a long series of clearly identified predictions that are accurate.”
Nope. The explanation was rebutted by Hausfather. For example, he showed that Hansen’s model correctly projected the amount of warming observed per unit of forcing. That’s an accurate prediction, since the antecedent (the requisite forcing) of that projection was met, and the projected warming (the consequent) occurred. But you’re just continuing your usual practice of acting as if no accurate prediction was made, no matter how many times it’s cited to you:
https://twitter.com/hausfath/status/1010240656004927491
Re: “I get that, but Hansen was calling for a policy change, and warning of dire consequences if the change was not enacted. He was not doing an abstract projection as in a graduate seminar or in a science journal.”
Irrelevant. What you think of Hansen’s policy position is irrelevant to the veracity of his projections/predictions. To say otherwise is a fallacious appeal to consequences, where you object to science because you think the science might lead to political consequences you dislike. It’s on par with objecting to scientific projections of smoking-induced cancer, because you dislike policies on cigarette taxes.
You’ve been told this many times: please learn the difference between “science” and “policy”.
Re: “The action he advocated was not taken, and the dire consequences he warned of did not occur.”
Let me know when you finally actually cite evidence for the claims you make.
Hansen was wrong because he neglected CRE.
https://watertechbyrie.files.wordpress.com/2014/12/wong2006figure7-e1520585725503.png
https://journals.ametsoc.org/doi/10.1175/JCLI3838.1
Re: “Hansen was wrong because he neglected CRE.”
https://journals.ametsoc.org/doi/10.1175/JCLI3838.1
Why are you abusing a paper from 2006? Is it because more recent papers with updated data rebut the point you’re trying to make?
https://journals.ametsoc.org/na101/home/literatum/publisher/ams/journals/content/clim/2016/15200442-29.20/jcli-d-16-0339.1/20161004/images/medium/jcli-d-16-0339.1-f3.gif
[figure 3 of: “Insights into Earth’s energy imbalance from multiple sources”]
The Wong et al (2006) paper was the final report on the cobbled together ERB Experiment. It clearly shows a CRE component – consistent with ISCCP data and – in the graph shown – with Josh Willis’ xbt annual series ocean heat possible from the 1990’s.
Whatever CO2 warming there is adds up slowly and is swamped by intrinsic variability. Modern data is much more certain of vigorous intrinsic variability.
Re: “The Wong et al (2006) paper was the final report on the cobbled together ERB Experiment. It clearly shows a CRE component – consistent with ISCCP data and – in the graph shown – with Josh Willis’ xbt annual series ocean heat possible from the 1990’s. Whatever CO2 warming there is adds up slowly and is swamped by intrinsic variability. Modern data is much more certain of vigorous intrinsic variability.”
Once again, please stay up to date on the relevant literature. I already addressed your out-of-date claims on CERES. In response, you’ve now shifted to ISCCP. Well, ISCCP was known to be inhomogenous/heterogenous (containing artifacts) pre-2007:
“Here we show that trends observed in the ISCCP data are satellite viewing geometry artifacts and are not related to physical changes in the atmosphere. Our results suggest that in its current form, the ISCCP data may not be appropriate for certain long‐term global studies, especially those focused on trends.”
https://agupubs.onlinelibrary.wiley.com/doi/full/10.1029/2006GL028083
This was addressed by homogenization in more recent work (post-2014) with “[m]odern data” (as you call it), arguing against your claim that these results show that CO2-induced warming is swamped by intrinsic variability. Instead increased greenhouse gases are resulting in positive feedback from clouds, as predicted by climate models. See:
“Empirical removal of artifacts from the ISCCP and PATMOS-x satellite cloud records”
https://journals.ametsoc.org/doi/pdf/10.1175/JTECH-D-14-00058.1
“Here we show that several independent, empirically corrected satellite records exhibit large-scale patterns of cloud change between the 1980s and the 2000s that are similar to those produced by model simulations of climate with recent historical external radiative forcing. […] The primary drivers of these cloud changes appear to be increasing greenhouse gas concentrations and a recovery from volcanic radiative cooling. These results indicate that the cloud changes most consistently predicted by global climate models are currently occurring in nature.
[…]
Our results suggest that radiative forcing by a combination of anthropogenic greenhouse gases and volcanic aerosol has produced observed cloud changes during the past several decades that exert positive feedbacks on the climate system. We expect increasing greenhouse gases will cause these cloud trends to continue in the future unless offset by unpredictable large volcanic eruptions.”
https://www.nature.com/articles/nature18273
“In summary, although there is independent evidence for decadal changes in TOA radiative fluxes over the last two decades, the evidence is equivocal. Changes in the planetary and tropical TOA radiative fluxes are consistent with independent global ocean heat-storage data, and are expected to be dominated by changes in cloud radiative forcing. To the extent that they are real, they may simply reflect natural low-frequency variability of the climate system.” https://www.ipcc.ch/publications_and_data/ar4/wg1/en/ch3s3-4-4-1.html
CERES data is showing that low frequency climate variation is very real.
Atomsk’s Sanakan: You’ve been told this many times: please learn the difference between “science” and “policy”.
Atomsk’s Sanakan: Atomsk’s Sanakan: You’ve been told this many times: please learn the difference between “science” and “policy”.
I think you are mistaken about who confounds science with policy. It is no confusion to point out that Dr Hansen was advocating policy changes.
MM, you can make projections without advocating for policy changes. Projections themselves are on the science side of the debate. I can estimate from several emission scenarios that for every 2000 GtCO2 we emit by 2100, it is worth an extra degree C of warming. That would be a scientific statement in units of warming per emissions. Policy comes in only after you define how much warming you can stand.
RIE, you insist on using old references. That quote was from AR4 where the most recent thing they had was Wong et al. (2006) that you have already been called out on. Use newer references if you want to even pretend to be up to date on the science.
There are different sources for satellite data – the Wong et 2006 paper is the final ERBE version. We should be so lucky if #jiminy should reference any science and here he is whining about data – and consistent sets of data at that. As if that was not last recourse of the scientific scoundrel. Inconvenient data is always ‘refuted’ – if on shaky ground.
And the modern data I refer to ‘ad nauseum’ he says counts for nothing in being up to date? We know that there is large variability in the TOA record linked to ocean and atmospheric regimes. The available data suggests that late 20th century warming was cloud radiative effect mediated – as the IPCC said – in the warm Pacific mode.
It was well after 2006 that Trenberth said it was a travesty that the energy budget could not explain the pause. More recent data has closed that budget much better. This is revised ocean surface and a further decade of ARGO data. The IPCC status now is much better than it was in 2007 when AR4 came out, so you should be using at least AR5 if you are going to quote things.
Re: https://www.ipcc.ch/publications_and_data/ar4/wg1/en/ch3s3-4-4-1.html
“CERES data is showing that low frequency climate variation is very real.”
Once again, Robert, you’re citing older material (in this case, IPCC AR4 from 2007, using pre-2007 analyses) to avoid the more recent evidence cited to you, since that more recent evidence undermines your claims. Actually try to stay up-to-date. You’re not fooling any sensible person.
Anyway, here is a 2017 analysis with the CERES:
https://archive.is/rM0n0/85bbcb79fdc9876a32b523958c0ae8011804bbb1.jpg
[A portion of figure 1 of: “Constraining the global ocean heat content through assimilation of CERES‐derived TOA energy imbalance estimates”]
That goes along with the 2016 CERES analysis I cited to you before:
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881564
I think Atomski mistakes ERBS data for CERES. It is the only explanation. Here’s the CERES anomaly (deseasonalized) data.
This is SW out.
https://watertechbyrie.files.wordpress.com/2018/09/ceres_ebaf-toa_ed4-0_anom_toa_shortwave_flux-all-sky_march-2000tomarch-2018.png
This is IR out.
https://watertechbyrie.files.wordpress.com/2018/09/ceres_ebaf-toa_ed4-0_anom_toa_longwave_flux-all-sky_march-2000tomarch-20181-e1537054841922.png
This is SW plus IR. Warming is up by convention.
https://watertechbyrie.files.wordpress.com/2018/09/ceres_ebaf-toa_ed4-0_anom_toa_net_flux-all-sky_march-2000tomarch-20181.png
Cooling in IR, warming in SW – warming net. A low level marine-strato cumulus pattern associated with eastern and central Pacific sea surface temperature. With a 1E-10 W/m2 instantaneous impetus from increasing greenhouse gases. Something that can’t be seen against intrinsic variation many orders of magnitude greater.
Just what is it do you think these people are trying to prove?
They seem to be proving a positive albedo feedback.
Re: “I think Atomski mistakes ERBS data for CERES. It is the only explanation.”
No, it’s CERES, as you would have known if you actually read what I cited to you. For example, this paper I cited:
“Constraining the global ocean heat content through assimilation of CERES‐derived TOA energy imbalance estimates
[…]
We use in this study CERES Energy Balanced and Filled Top-of Atmosphere (EBAF-TOA) Edition 4.0 (Loeb et al., 2016), released during early 2017”
Reading comprehension is important. Please actually try to display it.
Re: “A low level marine-strato cumulus pattern associated with eastern and central Pacific sea surface temperature. With a 1E-10 W/m2 instantaneous impetus from increasing greenhouse gases. Something that can’t be seen against intrinsic variation many orders of magnitude greater.”
Congratulations on having your own personal, non-expert interpretation of the data. Don’t conflate that with what the researchers actually concluded, or what the research actually showed.
The late 20th century data from the Wong et al 2006 ERBS edition 3 – the final – study was under discussion. Not the CERES mission that has been operating since March 2000. Hence my confusion.
But as for CERES – interpreting the NASA data products is the easy part. Just remember:
SW – up is out
IR – up is out
Net = -SW – IR – up trend is warming
But the real global energy budget must include the sun and dynamic planetary responses.
They are a positive albedo feedback for which an athropogenic or Pacific Ocean oscillation explanation can be given – or both. The computer derived cloud feedback to AGW is some 0.18 to 1.18 W/m2/K.
http://images.remss.com/data/msu/graphics/TLT_v40/plots/RSS_TS_channel_TLT_Global_Land_And_Sea_v04_0.png
Warming was strongest from 1976 to 1998 – a warm Pacific regime – including recoveries from El Chichón and Mount Pinatubo. Atmospheric temperatures this century have plateaued – although Argo says that the oceans are warming at long last after a still controversial start. CERES says that Argo is wrong at the start of its record. They were always warming. OMG – ring the interweb. It’s OK now. So how much warming and thus cloud feedback in the atmosphere? Not near enough at the outside to cover all change.
And in the first instance related to the Pacific state. A 20th century peak in El Nino intensity and frequency. To be followed and when by a reversion to a centuries long more La Nina like state?
https://www.esrl.noaa.gov/psd/enso/mei/ts.gif
‘El Niño/Southern Oscillation (ENSO) is the most important coupled ocean-atmosphere phenomenon to cause global climate variability on interannual time scales. Here we attempt to monitor ENSO by basing the Multivariate ENSO Index (MEI) on the six main observed variables over the tropical Pacific. These six variables are: sea-level pressure (P), zonal (U) and meridional (V) components of the surface wind, sea surface temperature (S), surface air temperature (A), and total cloudiness fraction of the sky (C).’ https://www.esrl.noaa.gov/psd/enso/mei/
Six variables to define the Pacific state and 2 polar rings to control them.
No, the only increasing forcing going on during this period is CO2. That steadily increased by 0.5 W/m2 and contributes to LW warming. That is largely offset by the warming response which gives LW cooling, but it is reinforced by the SW feedback too. The response is why you see the LW not changing much despite the large forcing change. This increase in forcing has been persistently accelerating for a century, especially the last 30 years, but so has the warming.
http://woodfortrees.org/plot/gistemp/from:1950/mean:12/plot/esrl-co2/scale:0.01/offset:-3.25
These correlate at 93% over the last 60 years. Note that they both have the upward curve. That is not a coincidence. Temperature correlates with CO2 (or log CO2) at a higher value than it correlates with the year (91%). The acceleration of both rates with time is why.
Does this mean he has finally done an impossible correlation? But tell me – what leads you to think that emissions won’t peak within decades?
But note how neatly narrative wraps it up in a bow.
You can see how correlated they are from the plot too. If that doesn’t look like 93%, what does? Nor is anyone at all surprised by this, except perhaps you. This correlation implies a fairly well defined gradient with a sensitivity close to 2.3 C per doubling.
deadlocked debate? what debate?
1. Popper is wrong, as is Ross here.
2. Even IF models worked perfectly Skeptics would refuse to believe C02 causes warming.
3. Models are themselves representations of the theory and not the theory and not the theory itself.
SM
You are the one that’s wrong. It’s all about the history and observational data. If there was not a hint of a MWP or Roman Warm Period or LIA or warming in early last century and no SLR until 1950 and Antarctica was not cooling and West Antarctica was not inherently unstable and subsidence was not a significant part of relative SLR and there was no uncountable stacked oscillations and all the physical changes were easily shown to be unprecedented, then the skeptics would have no choice but to be warmists. But that is not the case, so skeptics have no choice but to be skeptical. At a minimum, anyone with modicum critical thinking skills would be questioning the unwarranted absolute certainty that is so pervasive in the establishment.
Weak sauce here.
1. Popper is wrong, as is Ross here.
The implication of hysterics is that climate is predictable.
The evidence pointed out here indicates that models fail to accurately predict distribution of thermal energy in the atmosphere. Now, some aspects, even with the erroneous thermal energy distributions, are captured: cooling stratosphere, Arctic maxima, general warming. But the errors of the upper troposphere indicate that the motions are not predicted nor predictable. We knew this already, it’s been a lie implicit in climate ‘modeling’.
2. Even IF models worked perfectly Skeptics would refuse to believe C02 causes warming.
Straw man? Which skeptics? The reason to even try to model in 4d was that radiative-convective models imply motions in three dimensions. The lack of a hot spot means the 4d model of convection still fails. Yes is warming that will likely continue. But the model failure means:
1. there’s no evidence for the high end warming pushed by hysterics
2. there’s not evidence to support climate change in association with warming.
3. Models are themselves representations of the theory and not the theory and not the theory itself.
Right – that’s a problem, because hysterics believe, without evidence, that there’s settled science theory that means warming is associated with fires, storms, floods, droughts and other imaginary climate change.
“SM
“You are the one that’s wrong. It’s all about the history and observational data. If there was not a hint of a MWP or Roman Warm Period or LIA or warming in early last century and no SLR until 1950 and Antarctica was not cooling and West Antarctica was not inherently unstable and subsidence was not a significant part of relative SLR and there was no uncountable stacked oscillations and all the physical changes were easily shown to be unprecedented, then the skeptics would have no choice but to be warmists.”
Err no, Skepticism can question any evidence whatsoever.
FFS there are skeptics who dont believe in GHE, who dont
believe it has warmed, who believe Pressure determines temperature
of planets. It could warm 10C and skeptics would still argue there is no PROOF it wsa c02 because it could be something else, because there is no controlled experiment
“But that is not the case, so skeptics have no choice but to be skeptical. At a minimum, anyone with modicum critical thinking skills would be questioning the unwarranted absolute certainty that is so pervasive in the establishment.”
Are you so certain people assert absoluet certainty? where?
AGW happens to be the best imperfect explanation.
It will hold until some skeptic replaces it with another explanation
Suggesting that your skepticism is not a free choice is interesting
but you are responsible for what you choose to believe.
Weak sauce here.
1. Popper is wrong, as is Ross here.
The implication of hysterics is that climate is predictable.
The evidence pointed out here indicates that models fail to accurately predict distribution of thermal energy in the atmosphere. Now, some aspects, even with the erroneous thermal energy distributions, are captured: cooling stratosphere, Arctic maxima, general warming. But the errors of the upper troposphere indicate that the motions are not predicted nor predictable. We knew this already, it’s been a lie implicit in climate ‘modeling’.
########################
climate is predictable, hansen did quite well with his predictions.
Formally Proving that it is unpredictable would be a neat Godellian
trick that you are not up to. Prediction is ALWAYS possible.
Skillful prediction is an open question answered by metrics not
your bombast. The hotspot has been predicted. Whether or not
that is skillfull or not is a difficult question ( not answered by Ross)
and the implications of low skill are likewise uncertain.
2. Even IF models worked perfectly Skeptics would refuse to believe C02 causes warming.
Straw man? Which skeptics?
1. You really want names? pick any sky dragon
2. How about you? does c02 cause warming? how much?
how do you know?
“The reason to even try to model in 4d was that radiative-convective models imply motions in three dimensions. The lack of a hot spot means the 4d model of convection still fails. Yes is warming that will likely continue. But the model failure means:
1. there’s no evidence for the high end warming pushed by hysterics
2. there’s not evidence to support climate change in association with warming.”
Are you certain that A) the model fails B) that this failure
says anything about high end warming predictions?
Seems to me you are just claiming things, not showing anything.
Now of course, answer this. A radiosond measures the temperature
a point in space and point in time. How did Ross account for this
when comparing a point measurement against a spatial feild?
Question: Ross do not actually get his data from the models. he
got it from a secondary source that supposedly collates the data.
Ever check whether that was done correctly? I look at his
data and his code. There a half a dozen things to check before
I would even BEGIN to render judgement on his paper, because..
I am skeptical. I have caught him making data input errors before.
especially with spatial data. So I suspend judgement. You merely
believe. you merely believe what you have always believed and
dont even think to check the stuff.
3. Models are themselves representations of the theory and not the theory and not the theory itself.
Right – that’s a problem, because hysterics believe, without evidence, that there’s settled science theory that means warming is associated with fires, storms, floods, droughts and other imaginary climate change.
Your hysterics are a straw man. You have nothing new to contribute.
you do no orginal science. you never question your own beliefs.
your mind is settled.
“you never question your own beliefs.”
Are we not something like 1 ky overdue for then end of this interglacial? Well, in terms of average length, at any rate. In viewing proxies for these times, it is apparent that the bifurcation is chaotic – many almosts, many reversals and takes a while to settle out. Of course, from an objective human lifetime, it’s probably “we’re all gonna freeze/burn if this keeps up”.
So geologically speaking, we’re already on the way down – it’s really a case of when, not if.
Which means I hope you warmists are right, despite the evidence (or lack thereof) to date – your grandkids might thank you for creating all that CO2 and saving them from the ice!
Steven Mosher: 2. Even IF models worked perfectly Skeptics would refuse to believe C02 causes warming.
Depending on which model(s) worked perfectly, that might be perfectly justifiable.
“hansen did quite well with his predictions.”
Sure, except for the part where he predicted way too much warming based on “business as usual” emissions in the actual graph he presented to Congress as a basis for setting the nation’s emissions policy.
http://image.guardian.co.uk/sys-files/Environment/documents/2008/06/23/ClimateChangeHearing1988.pdf
The argument that he “did quite well” when you re-run the models with new inputs is interesting in an academic sense, but his actual prediction was clearly falsified by observation, and as an input for policy clearly wrong.
The conflation of Hansen’s actual 1988 predictions with new runs of the 1988 model using data not available in 1988 is deliberately misleading and constitutes one of the worst examples of the too-common “three-card monte” attitude in the policy debate. Policymakers don’t care if component X of your failed prediction Y does well, they need to work with actual predictions of real physical phenomena in the real world.
Re: “Sure, except for the part where he predicted way too much warming based on “business as usual” emissions in the actual graph he presented to Congress as a basis for setting the nation’s emissions policy.”
No, his prediction did relatively well, as Hausfather and others have explained multiple times:
https://twitter.com/hausfath/status/1010240647960264705/photo/1
Re: “The argument that he “did quite well” when you re-run the models with new inputs is interesting in an academic sense, but his actual prediction was clearly falsified by observation, and as an input for policy clearly wrong.
The conflation of Hansen’s actual 1988 predictions with new runs of the 1988 model using data not available in 1988 is deliberately misleading and constitutes one of the worst examples of the too-common “three-card monte” attitude in the policy debate. Policymakers don’t care if component X of your failed prediction Y does well, they need to work with actual predictions of real physical phenomena in the real world.”
No, you’re messing up badly, especially on the distinction between a “prediction” vs. a “projection”. In climate science, a projection states what will likely happen, given a set of initial/antecedent conditions. A prediction states what will actually happen.
For example, take the following two simple projections from a different field:
1) If 100,000 people smoke this year, then there will be 5000 cases of cancer this year.
2) If 10,000 people smoke this year, then there will be 500 cases of cancer this year.
Now, suppose that past epidemiological trends suggested that 100,000 people would smoke this year. So the epidemiologists predicted 5000 cases of cancer, based on there being 100,000 people smoking. But it turns out that government public health interventions were wildly successful, so only 10,000 people smoked that year, leading to only 500 cases of cancer that year.
Does that mean the epidemidologists’ projections and predictions were wrong? No, because the initial/antecedent condition (“100,000 people smoke this year”) for the epidemiologist’s “5000 cases of cancer” prediction were not met.
Will policy-makers think the epidemiologists’ projections are useless and “three-card monte”? No, because the epidemiologist’s projections allow policy-makers to make predictions, given initial conditions. Intelligent policy-makers have the brains need to adjust to new information and changing conditions.
Parallel point for Hansen’s predictions and projections. When you check his projections for the antecedent conditions that actually occurred (as Hausfather and other’s have done), Hansen’s predictions were fairly accurate. And policy-makers with brains will know that said projections will be useful, as long as one takes into account the relevant initial/antecedent conditions.
Atomsk’s Sanakan: No, you’re messing up badly, especially on the distinction between a “prediction” vs. a “projection”. In climate science, a projection states what will likely happen, given a set of initial/antecedent conditions. A prediction states what will actually happen.
In climate science, “predictions” become “projections” after they have been shown to be inaccurate. Hanson spoke and wrote as it what he “projected” would really come to pass if the course CO2 was not changed. It was a “warning”, not an abstract projection.
from Hausfather: While its true that Hansen’s “most plausible” Scenario B modestly overestimates recent warming, the reason has nothing to do with the accuracy of Hansen’s model.
There are multiple possibilities for the inaccuracy of Hansen’s projection, one of which is that the model was inaccurate. But the projection was inaccurate. Until there is a long series of accurate temperature projections, there will be multiple reasons for their inaccuracies, and they should not be thought to be accurate.
If rerun now, what would Hansen’s model project for the future scenarios? Has anybody done this re-running? Has his model been retuned? Has it been abandoned by people calculating projections?
“There are multiple possibilities for the inaccuracy of Hansen’s projection,”
Yes indeed, and as Nick Stokes has commented – one of them is that GHG’s other than CO2 did not, in eventuality, match his projections.
It’s not all CO2 and models.
https://moyhu.blogspot.com/2018/07/hansens-1988-prediction-scenarios.html
Re: “In climate science, “predictions” become “projections” after they have been shown to be inaccurate.”
No, that is not the case, as you would know if you’d bothered to read the comment you were responding to before you responded. A projection does not yield a prediction for what actually occurred, if the projection’s antecedent conditions did not actually occur. This doesn’t just apply to projections in climate science; it applies to projections in every field of science, as illustrated by the epidemiology/smoking example I gave.
Re: “There are multiple possibilities for the inaccuracy of Hansen’s projection, one of which is that the model was inaccurate.”
That explanation was already rebutted by Hausfather.
Re: “But the projection was inaccurate. Until there is a long series of accurate temperature projections, there will be multiple reasons for their inaccuracies, and they should not be thought to be accurate.”
No, the projection was not inaccurate for the reasons already explained to you. Once again:
A projection involves a conditional statement, with antecedent conditions. If you know basic logic, then you know that in order to show a conditional is false, then you need to show that the conditional’s consequent is false when the conditional’s antecedent is true. Your problem is you seem to accept the false (and illogical) idea that you can show a conditional is false, simply by showing it’s consequent is false, regardless of whether the conditional’s antecedent was true.
Another problem you have is that you continue to act as if no out-of-sample comparisons were done for Hansen’s 1988 projections, even though it was already explained to you that Hausfather’s comparison was an out-of-sample comparison since the relevant data for the comparison was not available to Hansen in 1988:
https://judithcurry.com/2018/07/03/the-hansen-forecasts-30-years-later/#comment-877503
This thread is somewhat cold, but there is some importance here.
Stripping away the ad homs and insults ( from all ) …
The implication is that climate is predictable.
The evidence pointed out here indicates that models fail to accurately predict distribution of thermal energy in the atmosphere. Now, some aspects, even with the erroneous thermal energy distributions, are captured: cooling stratosphere, Arctic maxima, general warming. But the errors of the upper troposphere indicate that the motions are not predicted nor predictable. We knew this already, it’s been a lie implicit in climate ‘modeling’.
“climate is predictable, hansen did quite well with his predictions.”
As I wrote ‘some aspects are captured, including general warming’.
However, ‘hansen did quite well’ is not representative.
Since his testimony, observed surface trends are closest to Scenario C.
https://turbulenteddies.files.wordpress.com/2018/06/hansen_2017.png
This was the scenario in which all co2 emissions ceased in 2000.
Now, to be sure, emissions were less than, though closest to Scenario B.
Hansen was incorrect both with emissions and response.
Further, the GISS Model, like most others, includes the upper tropospheric hot spot which is contra-indicated by satellite and reliable raobs.
“Formally Proving that it is unpredictable would be a neat Godellian
trick that you are not up to. Prediction is ALWAYS possible.
Skillful prediction is an open question answered by metrics not
your bombast.”
All you need to grasp this is to understand that linearizations of nonlinear physical formulae governing the atmosphere imply an infinite array of equally valid solutions. So the physics, or rather the mathematical solutions to the physics do not have a unique future solution for any given state.
Now, there are some limits to this which have enabled some successful prediction. In the stratosphere, the relative importance of radiance over motion means that the stratospheric cooling, predicted by increased CO2, has largely verified. The top of the atmosphere radiance imbalance allows the prediction of increased global temperature. And the increased heat capacity of the atmosphere explains the successful prediction of the so called arctic amplification.
Droughts, floods, storms, etc. are dynamic events much more constrained and determined by the unpredictable motions than by radiance or global temperature.
This is hardly novel or unique to me. Even the IPCC knows this:
https://wattsupwiththat.files.wordpress.com/2015/02/ipcc-models-predict-future.png
‘The Physics of Climate’ ( Peixoto and Oort ) should be on your bookshelf.
In it, you will find:
“Thus, the whole climate system must be regarded as continuously evolving with parts of the system leading and others lagging in time. The highly nonlinear interactions between the subsystems tend to occur on many time and space scales. Therefore, the subsystems of the climate system are not always in equilibrium with each other, and not even in internal equilibrium.”
ps://i.imgur.com/8Ny3ZyY.png
https://i.imgur.com/8Ny3ZyY.png
Atomsk’s Sanakan: That explanation was already rebutted by Hausfather.
That explanation was disputed by Hausfather. He might be right.
I am eager to see a long series of clearly identified predictions that are accurate. Until then, the warnings are not to be relied upon for anything other than designing the next research.
Regarding ENSO and the CFAN forecast, I’m watching like you and JC for the result, but still reflect that was a less than one year forecast and of a statistical nature, not a long term forecast. And it involved leading indicators. Further, roughly a quarter of all years are El Nino, a quarter La Nina, so the blind squirrel forecast to beat is 25% chance of El Nino every year.
If CFAN can consistently beat the blind squirrel every year, we rejoice at something that the GCMs currently have no skill at.
And it might matter a lot.
https://turbulenteddies.files.wordpress.com/2018/05/extended_mei_change_2017.png
If CFAN can consistently beat the blind squirrel every year, we rejoice at something that the GCMs currently have no skill at.
Utterly ridiculous. GCM make no attempt to next years predict weather so skill at it is not even on the table.
DM Smith’s decadal forecasting model, especially if an El Niño happens late 18/ early 19, is looking good. In the teeth of PAWS, when scientists like Tsonis were suggesting PAWS conditions might last for a few decades, Smith forecast a lot of warming in the coming years because his model was showing a flip to positive conditions in the Eastern Pacific.
Jut about everybody was forecasting an El Niño.
It won’t be an El Niño until it is an El Niño.
“Utterly ridiculous. GCM make no attempt to next years predict weather so skill at it is not even on the table.”
Yes.
That’s very consistent with the unpredictability of climate.
Atomsk’s Sanakan: A projection involves a conditional statement, with antecedent conditions.
I get that, but Hansen was calling for a policy change, and warning of dire consequences if the change was not enacted. He was not doing an abstract projection as in a graduate seminar or in a science journal.
Possibly the scientific understanding of the CO2 effects of “business as usual” is limited.
The action he advocated was not taken, and the dire consequences he warned of did not occur.
Re: “Hansen was incorrect both with emissions and response.”
No, he was right on the response, as shown in Hausfather’s previously cited analysis. And saying Hansen wasn’t right in his predictions on emissions, is as ridiculous as blaming epidemiologists for not accurately predicting how many people will actually smoke when they do their projections for future cancer cases. All of this was explained before:
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881481
Re: “Further, the GISS Model, like most others, includes the upper tropospheric hot spot which is contra-indicated by satellite and reliable raobs.”
You’ve been repeatedly cited evidence showing that the hot spot exists, in both radiosonde-based analyses (such as RAOB) and satellite-based MSU analyses. For instance:
https://judithcurry.com/2018/07/22/the-perils-of-near-tabloid-science/#comment-877599
https://judithcurry.com/2018/07/22/the-perils-of-near-tabloid-science/#comment-877182
https://judithcurry.com/2018/07/22/the-perils-of-near-tabloid-science/#comment-877429
In response, you simply brushed off the evidence (from the peer-reviewed papers I cited to you), by claiming that citing peer-reviewed evidence is just “motivated parrotry”:
https://judithcurry.com/2018/07/22/the-perils-of-near-tabloid-science/#comment-877614
Re: “This is hardly novel or unique to me. Even the IPCC knows this:”
Don’t quote-mine. You left out the portions in which the IPCC explains that climate models should be used in predicting the probability of a range of future states. You also left out how the IPCC made clear that “non-linear chaos” does not mean the same thing as “unpredictable”. Maybe you left these points out because doing so makes it easier for you to make it look like the IPCC agrees with you on unpredictability?:
“The climate system is a coupled non-linear chaotic system, and therefore the long-term prediction of future climate states is not possible. Rather the focus must be upon the prediction of the probability distribution of the system’s future possible states by the generation of ensembles of model solutions. Addressing adequately the statistical nature of climate is computationally intensive and requires the application of new methods of model diagnosis, but such statistical information is essential.”
https://www.ipcc.ch/ipccreports/tar/wg1/501.htm#pq=XCHQ8R
“Many processes and interactions in the climate system are non-linear. That means that there is no simple proportional relation between cause and effect. A complex, non-linear system may display what is technically called chaotic behaviour. This means that the behaviour of the system is critically dependent on very small changes of the initial conditions. This does not imply, however, that the behaviour of non-linear chaotic systems is entirely unpredictable, contrary to what is meant by “chaotic” in colloquial language. It has, however, consequences for the nature of its variability and the predictability of its variations. The daily weather is a good example. The evolution of weather systems responsible for the daily weather is governed by such non-linear chaotic dynamics. This does not preclude successful weather prediction, but its predictability is limited to a period of at most two weeks. Similarly, although the climate system is highly non-linear, the quasi-linear response of many models to present and predicted levels of external radiative forcing suggests that the large-scale aspects of human-induced climate change may be predictable, although as discussed in Section 1.3.2 below, unpredictable behaviour of non-linear systems can never be ruled out.”
https://www.ipcc.ch/ipccreports/tar/wg1/042.htm
Atomsk’s Sanakan ,
Thank you for demonstrating exactly what I was referring to. Read the linked Senate testimony, it is quite clear that Hansen is predicting (“with high confidence” no less) that Series A temperatures will be the result of a “business as usual” emissions policy.
Zeke is just flat-out wrong, what policy scenario Hansen thought was “most likely” is irrelevant: we know what the policy was, and it was business as usual. And we didn’t get anything like Scenario A temps out of it.
“When you check his projections for the antecedent conditions”
Again, policymakers don’t care how well component X of failed prediction Y has done. This is useless to policymakers and the deception and quibbling over words just makes it worse.
matthewrmarler | September 28, 2018 at 7:48 pm |
“Hansen was calling for a policy change, and warning of dire consequences if the change was not enacted. He was not doing an abstract projection as in a graduate seminar or in a science journal.”
Precisely. This is a huge disconnect and (I think) related to what Curry means when she talks about Gavin living in model world while she lives in the real world. Policymakers need useful inputs from scientists, not just models that can look good when run with different number 30 years after the fact. If you don’t have useful inputs, that’s probably not your fault, but you should be honest about it. Congress is not merely a debating club, and whatever the number of excess deaths and increased human misery the higher energy prices of draconian worldwide emissions cuts would have produced from 1988 to 201, those human lives are not mere footnotes in a journal.
Re: “Thank you for demonstrating exactly what I was referring to. Read the linked Senate testimony, it is quite clear that Hansen is predicting (“with high confidence” no less) that Series A temperatures will be the result of a “business as usual” emissions policy.”
I already explained your error to you:
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881481
Once again:
Hansen made projections, where those projections can be rendered as conditionals (“if X, then Y”). Those conditionals have antecedent conditions (“X”), and a consequent (“Y”) that follows from those antecedent conditions. This results in a prediction for what actually occurred (“Y occurred in reality”), only if the antecedent conditions actually occurred (“X actually occurred in reality”).
So no, you cannot show a projection fails, just because its consequent did not occur. You need to show that its antecedent occurred, but the consequent did not. This is basic logic; conditionals are false only if there antecedent is true when their consequent is false. This applies to conditionals and projections in any branch of science, as in the smoking/epidemiology example I mentioned to you.
When you look at Hansen’s projection for which the antecedent conditions actually occurred, the consequent occurred. That’s what Hausfather showed.
Re: “Zeke is just flat-out wrong, what policy scenario Hansen thought was “most likely” is irrelevant”
The policy scenarios are relevant because they are part of the antecedent conditions for the projection. If you don’t grasp the concept of “antecedent conditions”, then you don’t grasp how to evaluate conditional statements and projections. You basically don’t grasp propositional logic.
Re: “Again, policymakers don’t care how well component X of failed prediction Y has done.”
Once again, you miss the point. You failed to show any failed prediction since, as I already explained to you, you only get a prediction for what actually occurred if the antecedent conditions for the conditional actually occurred. And I already explained to you how projections can be useful for policy-makers, when policy-makers focus on the projections for which antecedent conditions actually occurred.
Atom,
“I already explained your error to you”
No, you have simply repeated the exact errors I pointed out in my first comment, nor do you seem to understand such basic logical propositions as why Hansen’s “most likely” guess at a policy scenario is irrelevant when we know the actual emissions policy against which his three-forked prediction can be judged. As such, I do not think further replies to you are a good use of my time.
I will add that I don’t think Hansen’s failed auguries have any particular relevance to today’s models, which are quite a bit better, and the modern literature in 2018 is probably closing in on the true ECS number — emissions estimates and our understanding of carbon sinks has certainly advanced.
The correct response on Hansen’s testimony is “he was wrong, but models are better now.” Because that’s true. It’s unfortunate for climate science that the siege mentality has developed to the point such an admission is apparently impossible for many.
Correction: that quote was said by Steve McIntyre at Climate Audit, not Ross McKitrick.
Re: “Predictions are the gold standard of science.”
There have been plenty of confirmed, model-based predictions in climate science. You simply refuse to look into them (doing so would get in the way of a politically-motivated narrative regarding climate science). For example:
1) Post-1950s tropospheric warming + stratospheric cooling + mesospheric cooling + thermospheric cooling.
2) Post-1970s increase in radiation absorption at a wavenumber of ~666 cycles per cm.
3) More warming of land surface than the ocean surface.
4) Polar amplification, where the Arctic warms more than much of the rest of the world (including warming more than Antarctica).
5) Arctic ice loss (both land ice and sea ice).
6) Antarctic ice loss (land ice, and total ice levels)
7) Tropical hot spot, where the tropical troposphere warms more than the tropical ocean surface.
8) Ocean acidification, due to ocean uptake of anthropogenic CO2.
9) Decreased atmospheric ratios of C14 and C13 isotopes of CO2.
10) Specific changes in precipitation patterns. (ex: “Observed heavy precipitation increase confirms theory and early models”)
11) Sea level rise
12) Increased hurricane intensity.
13) Increased water vapor levels in response to warming; also, water vapor acting as a positive feedback on warming.
14) Clouds acting as a net positive feedback on warming.
Please finally do your homework on this subject. The following source will provide a useful, beginners-level introduction to this for you:
“Tyndall Lecture: GC43I. Successful Predictions – 2012 AGU Fall Meeting”
https://www.youtube.com/watch?v=RICBu_P8JWI&t=
Re: “Doing this for the model used in Hansen 1988 would be helpful. But Hargreaves 2010 said “efforts to reproduce the original model runs have not yet been successful.””
You were already addressed on your misrepresentations on this topic:
https://judithcurry.com/2018/07/03/the-hansen-forecasts-30-years-later/#comment-876222
It’s quite telling that you continue to repeat said misrepresentations anyway.
Please finally do your homework on this subject.
You’re not in any position to advise this until you’ve actually analyzed the MSU and RAOB data sets for yourself.
Byt the way, how’s that coming?
Re: “You’re not in any position to advise this until you’ve actually analyzed the MSU and RAOB data sets for yourself. Byt the way, how’s that coming?”
You’ve been repeatedly cited evidence showing that the hot spot exists, in both radiosonde-based analyes (such as RAOB) and satellite-based MSU analyses. For instance:
https://judithcurry.com/2018/07/22/the-perils-of-near-tabloid-science/#comment-877599
https://judithcurry.com/2018/07/22/the-perils-of-near-tabloid-science/#comment-877182
https://judithcurry.com/2018/07/22/the-perils-of-near-tabloid-science/#comment-877429
In response, you simply brushed off the evidence (from the peer-reviewed papers I cited to you), by claiming that citing peer-reviewed evidence is just “motivated parrotry”:
https://judithcurry.com/2018/07/22/the-perils-of-near-tabloid-science/#comment-877614
By your logic, a flat Earther can brush off all the peer-reviewed studies that present evidence that Earth is round, by claiming that citing those studies is just “motivated parrotry”. In fact, by your logic, Judith Curry and [every other scientist who cites references in their peer-reviewed papers that provide evidence supporting a point they made] is engaged in “motivated parrotry”. It’s as if you have no clue how evidence is cited in science.
Reblogged this on Climate Collections.
I think the fundamental flaw in the IPCC view, and consequent models, lies in the assumption that radiated energy absorbed by GHGs in the lower atmosphere is “trapped”. The reality is that it is delayed. There is a net upward flow of energy via IR. The key question is how long does this flow delay heat transfer to the upper troposphere and how much heating is caused by this delay. I estimate it at 0.14C, so trivial.
This result has been public for over a year now and accessed from over 60 countries with no rebuttal.
The greenhouse assumption was originally made because no other mechanism was apparent. Now there is an alternative with the Diurnal Smoothing Effect empirically confirmed in DIVINER data for the moon with thermal buffering provided by the rock surface. Various people, including Roy Spencer, have verified with simple calculations that the DSE is capable of producing Earth’s current mean surface temeprature with atmospheric thermal buffering adding to the surface buffering of the moon.
More detail in my RadiativeDelayInContext article at:
http://brindabella.id.au/climarc/
dai davies
In my humble opinion this obsession with radiation physics guarantees a continued supply of wrong answers from settled science. It is really a problem in thermodynamics. The mean free paths of photons in the presence of water vapor or CO2 is so short that the atmosphere is essentially opaque in these wavelengths. An IR photon is either blocked completely or if it happens to be emitted in the “Atmospheric Window” it escapes to space. The latter plus atmospheric convection are the two modes of heat transfer in the troposphere. Trying to model energy transmission through blocked radiation bands while ignoring convection doesn’t work and will never work until atmospheric physicists learn some thermodynamics.
Pochas94, instead you need to learn more on the radiative transfer equation and the absorption lines across the whole band. The absorptivity of CO2 varies by a few orders of magnitude across the band of 12-18um.
https://scienceofdoom.com/2013/01/13/visualizing-atmospheric-radiation-part-seven-co2-increases/
The rotatational sidekicks of the fundamental bend are orders of magnitude weaker, but the “P” rotations, only slightly weaker than the “R”, are destructive. They reduce the overall energy of the molecule, substantially cancelling out energy gained in R rotations.
Ross McKitrick, thank you for this essay.
Seconded. This post and underlying paper goes well beyond Christy’s 29 March 2017 Congressional testimony. For reasons previously stated elsewhere (see a summary with references in guest post Why Models Run Hot at WUWT) I don’t think the problem can be corrected for AR6. Computational intractability (by roughly 6-7 orders of magnitude!) forces parameterization that drags in the attribution problem via the inescapable tuning to best hindcast.
Pingback: Computer simulations just crashed - The Global Warming Policy Forum (GWPF)The Global Warming Policy Forum (GWPF)
Interesting paper, but like so many papers you don’t start with the null hypothesis: that what we see is noise, but instead start from the hypothesis: what we see is signal, and then after quantifying what you see as signal (without ever proving as such) you say it is less than others say it is.
But it is far worse than that! The problem, is that no one would be looking at this unless the temperature had gone up. So, we don’t start from an impartial “null hypothesis”. There is natural variation, we know that is a fact. We also suspect a human contribution. But the fact we have seen warming that triggers an investigation makes substantial underlying warming due to natural variation far more likely than at an arbitrary point in time.
So, yes at an arbitrary point of time in the past, the “null hypothesis” or “zero trend” is zero. But when warming has occurred sufficient to trigger an investigation, there is a much higher chance that underlying natural variation is also warming strongly. Thus in such a situation, the probability is that the average “natural variation” is a warming trend, so we should in fact be comparing trends not, with zero, but with the most likely natural variation that would trigger a warming investigation – so the “zero trend” we compare with is a warming trend.
The result is that (in systems with substantial amounts of natural variation with long term trends) any estimates of sensitivity will be much higher than they should.
Indeed, it is quite possible that the entire warming is natural. This then causes large natural warming, which triggers an investigation into warming and because there is a long term warming trend, you get a positive sensitivity for any rising variable when the sensitivity is zero. The same is also true of a cooling trend. If you don’t include for that effect in your analysis, you ALWAYS GET SENSITIVITIES THAT ARE TOO HIGH (for any system with long term variability).
“..estimates of sensitivity will be much higher than they should..” Scottish Sceptic, I think you have hit the psychological nail on the head. I have never seen your arguments made before, so they are actually “revelationary”, at least to me, in explaining why scientific predictions and scientific observations can be different after going through the “human thought filter” process.
The GWPF take on this, completely wrong.
“Comparing modeled to observed trends over the past 60 years…shows that all models warm more rapidly than observations and in the majority of individual cases the discrepancy is statistically significant. We argue that this provides informative evidence against the major hypothesis in most current climate models.”
The warming is upper warming. This is an indication of too much negative lapse rate feedback and models most likely underestimating the climate sensitivity as a result. GWPF’s readers won’t know this.
This is an indication of too much negative lapse rate feedback and models most likely underestimating the climate sensitivity as a result.
You are ignoring the reduced water vapor feedback as well.
The two largest feedbacks in absolute terms ( negative lapse rate and positive water vapor ) are largely reduced which means low sensitivity.
The negative lapse rate feedback difference is more dominant in the paper I cited. The hot spot radiates more effectively.
The negative lapse rate feedback difference is more dominant in the paper I cited. The hot spot radiates more effectively.
Yes, the argument for water vapor feedback is that the hot spot would also contain more water vapor.
Evidently, neither has happened for the last forty years or so.
Re: “Yes, the argument for water vapor feedback is that the hot spot would also contain more water vapor. Evidently, neither has happened for the last forty years or so.”
You’ve already been cited evidence on the hot spot existing:
https://judithcurry.com/2018/07/22/the-perils-of-near-tabloid-science/#comment-877182
https://judithcurry.com/2018/07/22/the-perils-of-near-tabloid-science/#comment-877599
https://judithcurry.com/2018/07/22/the-perils-of-near-tabloid-science/#comment-877429
You’ve also been cited evidence also positive feedback from water vapor. For example:
https://judithcurry.com/2018/09/01/the-lure-of-incredible-certitude/#comment-879854
“An assessment of tropospheric water vapor feedback using radiative kernels”
“Global water vapor trend from 1988 to 2011 and its diurnal asymmetry based on GPS, radiosonde, and microwave satellite measurements”
“Observations of climate feedbacks over 2000–10 and comparisons to climate models”
“Anthropogenic greenhouse forcing and strong water vapor feedback increase temperature in Europe”
“An analysis of tropospheric humidity trends from radiosondes”
“Enhanced positive water vapor feedback associated with tropical deep convection: New evidence from Aura MLS”
And you’ve also been cited evidence on increasing tropospheric water vapor. For instance:
https://judithcurry.com/2018/09/01/the-lure-of-incredible-certitude/#comment-879854
https://pbs.twimg.com/media/DgbqKNYXUAApALj.jpg
[from: “Construction and uncertainty estimation of a satellite‐derived total precipitable water data record over the world’s ocean”]
“Upper-tropospheric moistening in response to anthropogenic warming”
“The radiative signature of upper tropospheric moistening”
“Three decades of intersatellite-calibrated High-Resolution Infrared Radiation Sounder upper tropospheric water vapor”
You even cited evidence of positive water vapor feedback in the troposphere, without realizing what you had cited (you didn’t realize what you had cited because you simply copied an image you saw me post, even though you hadn’t read the original source the image came from):
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-880977
https://pbs.twimg.com/media/DgoC1w4X4AEdwdl.jpg
[from: “An assessment of tropospheric water vapor feedback using radiative kernels”]
Yet it’s quite telling how you continue to repeat your false, long-debunked claims, when you’ve been repeatedly shown evidence that you’re wrong.
“”Independence: The target of the prediction must not be an input to the empirical tuning of the model. This rules out using the global average surface temperature record.”
Lost me on this.
If you are predicting a temperature of a parcel of air adjacent to the surface and you have a GASTR then that is a legitimate part of where you start from in your prediction. It is not part of the target, just adjacent to it and may well be important to future estimation/prediction.
Perhaps I misunderstand the empirical part of your comment.
Perhaps I misunderstand the actual model dynamic.
Thank you for such a well-written, clear and accessible paper.
I believe that the hotspot divergence between real world and models largelly can be explained by difference in SST temperature trends in the Nino 3.4 area.
I did this comparison a while ago:
https://drive.google.com/open?id=0B_dL1shkWewaTXJJSExKRjBhbVE
Real world has the lowest Nino 3.4 trend and the lowest ” tropospheric rise”.
The relationship seems to be universal. If we for instance pick an observational period with the same Nino 3.4 trend as the model average, 2000-2017, the observed 200 mbar altitude trend will match the model average.
Hence, global warming in the real world seems to have more “la Nina” character than the models. There is probably an increased Walker circulation, stronger trade winds than in the models, that keep temperatures of the central tropical Pacific down ( cf England et al 2014). The heat is instead transported to the Arctic and mixed deeper down in the ocean.
It looks like the Arctic amplification and warming in the 700-2000 m ocean layer is larger in real world compared to the model average, but I have not yet looked into this in detail..
Models that are forced to follow observed ENSO patterns will likely reproduce observed warming trends in the tropical 300-200 mbar layer.
A simple test would be to make a regression of 300-200 mbar temperature vs Nino 3.4 SST and time. I guess that Nino 3.4 SST will explain around 60% of model/obs variance, and the rest is merely noise, just like in my example above..
Another question is of course why models poorly reproduce the observed 3.4 trends. Models may be bad at this, or the satellite era may be a temporary deviation, and the real world will catch up later…
“It is difficult to get a man to understand something, when his salary depends upon his not understanding it!” – Upton Sinclair
When the complexity of this problem is completely understood we are left with natural variability, and that doesn’t pay very well.
.
❶①❶①❶①❶①
❶①❶①❶①❶①
❶①❶①❶①❶①
❶①❶①❶①❶①
.
A simple bar chart, that shows how bad global warming is.
Most pictures are worth 1000 words, but this one is worth 2000.
https://agree-to-disagree.com/it-is-worse-than-we-thought
John and I have published a new paper in Earth and Space Science using tropical mid-troposphere trend comparisons (models versus observations). For a model to be scientific it ought to have an underlying testable hypothesis.
The hypothesis we are interested in testing is the representation of moist thermodynamics in the model troposphere that yields amplified warming in response to rising CO2 levels, thereby generating projections of global warming due to greenhouse gas emissions.
Measurability:
Specificity:
Independence:
Uniqueness:
Conclusion all 102 CMIP5 model runs warm faster than observations,
I don’t find this to be connected thinking. With a given increase in climate forcing, there would be a positive NAO/AO response, and a directly associated negative ENSO response. That would have a hard time driving a tropical hot spot. From an indirect solar forcing frame of reference, stronger solar wind states may have driven slight tropical cooling trend from 1979 to the mid 1990’s, followed by a tropical warming response with the weakening of the solar wind since then. By calling ocean phases internal variability, surface warming arising from negative feedback processes get misconstrued as forced warming.
A few points. You frame a good question. Is there a way to judge something like the GCMs?
“This rules out using the global average surface temperature record.”
Anyone with a brain can see that using the above as the main way to judge a GCM is foolish. Using that to judge, I can out perform ½ of GCMs with a model I made. While global warming has changed to climate change, using GMST as the way to judge GCMs should’ve also changed. They went with the name of it from one thing to all things. The quality of their models should also have expanded from one thing to many things. Look back at their old messages that were simple, usually temperature only, and compare it to now. Everything is caused by climate change. Your Figure 3 from the paper is great. A post centered around it should be made. That would have the potential to be used broadly. It does need more in the way of explanation. Since Christy and you are the source, and since I assume it’s near unimpeachable, it would have traction in my opinion. Your figure 4 from the paper is one that I am still guessing at what its meaning is. I assume blue is observations. Is time part of it? Or is it a distribution? Marketing. Meaning should be conveyed in 30 seconds or less. For instance, a PowerPoint slide. Meeting that test, others may include it in their presentations. Often the target is the middle of the bell curve of the audience. People who challenge you on this whole thing will target your four point definition. As in my opinion, that is the strength of the whole thing.
Casts a needed spotlight on a deserved circumspection of an undisclosed ideology underlying the findings of both Google, data manipulation and mathematical modeling by climate change alarmists.
Review: Climate Modelling: Philosophical and Conceptual Issues 1st ed. 2.0 out of 5 stars
Feynman.
Yes – if he is going to claim the socially authoritative imprimatur of science he should at least get the name right.
Thanks for correcting my memory!
Re: ” But the IPCC states that only greenhouse forcing would explain a strong historical warming trend in the target region. The presence of such a trend would thus have only one explanation; likewise, its absence would conflict with only one major hypothesis of the model, namely the set of parameterizations that yield amplified GHG-induced warming.”
Wrong. You, Christy (your co-author), Curry, etc. have been corrected on this many times. You’ve made this same false claim for years. For instance:
“Climate changes due to solar variability or other natural factors will not yield this pattern: only sustained greenhouse warming will do it.”
http://www.financialpost.com/story.html?id=d84e4100-44e4-4b96-940a-c7861a7e19ad&p=1
I think Santer et al. rebutted your point nicely in one of their recent papers:
“In the tropics, moist thermodynamic processes amplify surface warming […]. Such tropical amplification occurs for any surface warming; it is not a unique signature of greenhouse gas (GHG)-induced warming, as has been incorrectly claimed (Christy 2015) [27, page 383].”
To explain this for the umpteenth time, since so many online contrarians make false claims on this topic:
Tropical tropospheric amplification of warming (what some people call the “hot spot”) is not a GHG-specific effect. It occurs with any strong near-surface warming in the tropics, regardless of whether that warming is caused by CO2, increased TSI, ENSO, etc. The amplification mechanism is not dependent on the cause of the warming; the mechanism is latent heat release by condensing water vapor with increasing tropospheric height in the tropics [resulting in the moist adiabatic lapse rate reduction discussed by the IPCC]. This results in the negative lapse rate feedback, a negative feedback in the tropics that limits near-surface warming by transferring near-surface energy up to the troposphere, where that energy can be more easily radiated away.
Many contrarians try to obscure this point by misrepresenting the figure below from a 2007 IPCC report:
From 2007:
https://www.ipcc.ch/publications_and_data/ar4/wg1/en/fig/figure-9-1-l.png
[Page 675 of: “Climate change 2007: The physical science basis; Chapter 9: Understanding and attributing climate change”]
But that figure does not show that the hot spot is a CO2-specific or GHG-specific fingerprint. Instead the pronounced hot spot appears in the CO2 portion of the figure because CO2 levels increased enough that CO2 caused most of the recent global warming. If instead solar output increased enough to cause most of the recent global warming, then there would be a pronounced hot spot in the solar portion of that figure. This is made clear in the figure below, which comes from an earlier 2001 IPCC report:
From 2001:
https://www.ipcc.ch/ipccreports/tar/wg1/images/fig12-5.gif
(Page 707 of: “Climate change 2001: The scientific basis; Chapter 12: Detection of climate change and attribution of causes”)
So the tropical tropospheric warming doesn’t tell you about the cause of the near-surface warming, let alone that the cause is specifically a GHG like CO2; the IPCC never claimed that it did tell you that. Instead the amplifcation tells you about whether the negative lapse rate feedback is present in the tropics. If there’s not strong amplification of the upper tropical tropospheric warming relative to the near-surface warming, then that implies weaker negative feedback and thus more near-surface warming. For further discussion of this point, interested readers should review sources such as:
“Relationship of tropospheric stability to climate sensitivity and Earth’s observed radiation budget”
Section 2.6.1 on page 90 of “Climate science special report: A sustained assessment activity of the U.S. Global Change Research Program”
Crazy atom guy, it doesn’t matter whether the response is unique or not, it was modeled to have occurred in association with increased ghg warming and so far, has not.
This is not surprising given that turbulent motions of the atmosphere, which are the cause of the hot spot in the models, are not predictable, something long known since before GCMs were applied to global warming.
Re: “Crazy atom guy”
I expect the moderation on this blog to be selective, as usual.
Re: “it doesn’t matter whether the response is unique or not”
Of course it does. That’s why folks like you, Christy, McKitrick, David Evans, etc. go out of their way to claim it’s a response unique to GHG-induced warming. It’s one of the reasons why Christy (falsely) argues that CO2 isn’t significantly impacting atmospheric temperature. See:
“On the Existence of a “Tropical Hot Spot” & The Validity of EPA’s CO2 Endangerment Finding”
“On the Existence of a “Tropical Hot Spot” & The Validity of EPA’s CO2 Endangerment Finding, Abridged Research Report, Second Edition”
Re: “it was modeled to have occurred in association with increased ghg warming and so far, has not.”
You’ve been repeatedly cited evidence showing that the hot spot exists. For instance:
https://judithcurry.com/2018/07/22/the-perils-of-near-tabloid-science/#comment-877599
https://judithcurry.com/2018/07/22/the-perils-of-near-tabloid-science/#comment-877182
https://judithcurry.com/2018/07/22/the-perils-of-near-tabloid-science/#comment-877429
In response, you simply brushed off the evidence (from the peer-reviewed papers I cited to you), by claiming that citing peer-reviewed evidence is just “motivated parrotry”:
https://judithcurry.com/2018/07/22/the-perils-of-near-tabloid-science/#comment-877614
By your logic, a flat Earther can brush off all the peer-reviewed studies that present evidence that Earth is round, by claiming that citing those studies is just “motivated parrotry”. In fact, by your logic, Judith Curry and [every other scientist who cites references in their peer-reviewed papers that provide evidence supporting a point they made] is engaged in “motivated parrotry”. It’s as if you have no clue how evidence is cited in science.
Of course it does. That’s why folks like you, Christy, McKitrick, David Evans, etc. go out of their way to claim it’s a response unique to GHG-induced warming.
No – what’s important is that it ( the hot spot ) does not exist in the observational data.
It doesn’t matter whether it’s specific or general – it doesn’t exist!
Re: “[Of course it does. That’s why folks like you, Christy, McKitrick, David Evans, etc. go out of their way to claim it’s a response unique to GHG-induced warming.]
No”
Actually, it’s true. You’ve already been cited evidence showing that. Get over it.
Another example of a prominent contrarian falsely claiming that the hot spot was unique fingerprint of anthropogenic, GHG-induced warming:
“The paper suggests that stratospheric cooling is a “more suitable” signal of anthropogenic global warming than trying to find a mid-troposphere hot spot (which was previously considered to be the definitive “fingerprint” of man-made global warming, but still has not been found despite millions of weather balloon and satellite observations over the past 60 years)”
https://wattsupwiththat.com/2014/08/04/what-stratospheric-hotspot/
I do apologize for the pejorative.
Whatever faults I may find with your arguments,
ad homs do not serve to point them out.
Re: “I do apologize for the pejorative.
Whatever faults I may find with your arguments,
ad homs do not serve to point them out.”
Whatever. It technically wasn’t an ad hominem, just an an insult. It would have been an ad hominem if you used to insult as a rationale for not accepting the evidence I cited.
Anyway, I’ll leave a link to Twitter with pretty pictures of observations of the tropical tropospheric hot spot, in case people are interested:
https://twitter.com/AtomsksSanakan/status/1013106417170108417
Atom …
As I suggested, you should try and read a bit of Aristotle. If you’re crazy why should we accept anything you say?
Re: “Atom … As I suggested, you should try and read a bit of Aristotle. If you’re crazy why should we accept anything you say?”
If you don’t have anything sensible to say about the evidence I cited, then you really don’t have to say anything at all. Even Turbulent Eddie now knows better than to use the “crazy” insult on me that you’re now exploiting. I suggest you go learn from him:
“I do apologize for the pejorative.
Whatever faults I may find with your arguments,
ad homs do not serve to point them out.”
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881062
And I suggest you actually read the article I explained to you on “appeal to authority”, since you still don’t seem to grasp it, given your “Aristotle” reference:
https://judithcurry.com/2018/09/15/week-in-review-science-edition-86/#comment-880805
Atomski has been shown before to be mistaken – if bombastically prolific, The hot spot is theorized to exist – an is Arctic amplification. Neither is proven to exist in any strictly falsifiable sense. But in the dynamically complex Earth system it is a search for Wally with too little data in time and space.
As I was saying to my imaginary friend just yesterday – climate is not just complex – it is dynamically complex. There is a world of difference between the two with dynamically complex behaviors consistent with the theory of chaotic systems. Great whorls and cascading adiabatic winds in the shifting states of Earth’s flow field.
Re: “The hot spot is theorized to exist – an is Arctic amplification. Neither is proven to exist in any strictly falsifiable sense.”
Evidence of the hot spot has been cited already. For instance, in the comments below:
https://judithcurry.com/2018/07/22/the-perils-of-near-tabloid-science/#comment-877599
https://judithcurry.com/2018/07/22/the-perils-of-near-tabloid-science/#comment-877182
https://judithcurry.com/2018/07/22/the-perils-of-near-tabloid-science/#comment-877429
And you’ve surprised me, Robert: I thought that not even you could object to Arctic amplification. The evidence for it is pretty clear, with the Arctic latitudes warming more than most of the rest of the globe at the near-surface:
https://wol-prod-cdn.literatumonline.com/cms/attachment/31dfb7af-2b20-4dd5-af32-3e24990af7b2/wea3174-fig-0002-m.png
[Figure 2 from: “Recent United Kingdom and global temperature variations”]
As shown in the above figure, Arctic amplification appears in HadCRUT4, even though HadCRUT4 is known to under-estimate Arctic warming. The evidence on that has been cited to you on multiple occasions:
“Coverage bias in the HadCRUT4 temperature series and its impact on recent temperature trends”
“Coverage bias in the HadCRUT4 temperature series and its impact on recent temperature trends. UPDATE COBE-SST2 based land-ocean dataset”
“Recently amplified arctic warming has contributed to a continual global warming trend”
“Arctic warming in ERA‐Interim and other analyses”
“An investigation into the impact of using various techniques to estimate Arctic surface air temperature anomalies”
Evidence of the inconclusiveness of evidence from at least three recognized specialists has been previously given. Same with Arctic temps. How much anthropogenic how much intrinsic due to internal dynamic complexity?
Re: “Evidence of the inconclusiveness of evidence from at least three recognized specialists has been previously given. Same with Arctic temps.”
If you want to know what “recognized specialists” say on this, then you would read the peer-reviewed literature, not contrarian blogposts. And I already cited some of the relevant peer-reviewed literature to you.
“Unlike mainstream climate scientists, who publish primarily in peer reviewed journals, these critics typically employ a range of non-peer-reviewed outlets, ranging from blogs to the books we are examining. […]
The general lack of peer review allows authors or editors of denial books to make inaccurate assertions that misrepresent the current state of climate science. Like the vast range of other non-peer-reviewed material produced by the denial community, book authors can make whatever claims they wish, no matter how scientifically unfounded.”
http://abs.sagepub.com/content/early/2013/05/01/0002764213477096.full.pdf
But if you’re still committed to seeing what “recognized specialists” say about the hot spot and Arctic amplification in non-peer-reviewed sources, then:
http://ocean.dmi.dk/arctic/plus80n/anoplus80N_summer_winter_engelsk.png
“The Arctic region has witnessed a rapid increase in mean temperatures since the beginning of the millennium; Arctic winter temperatures in particular have been up to 8oC above normal during recent years. This temperature increase is much higher than the global average, an effect known as Arctic Amplification, and it is primarily driven by albedo feedbacks caused by changes in snow and ice on land and loss of the Arctic sea ice.”
http://ocean.dmi.dk/arctic/meant80n_anomaly.uk.php
https://twitter.com/MearsCarl/status/940786708152553473
Atomski, read the paper. While increased solar forcing could cause a tropical hotspot in principle, the IPCC says elsewhere that solar forcing hasn’t increased enough to do so. Or, as you say, “… the pronounced hot spot appears in the CO2 portion of the figure because CO2 levels increased enough that CO2 caused most of the recent global warming. If instead solar output increased enough to cause most of the recent global warming, then there would be a pronounced hot spot in the solar portion of that figure.” Precisely. Only CO2 has increased enough to give rise to a prediction of a tropical hotspot. The absence of the hotspot therefore only conflicts with one prediction. It doesn’t conflict with a predicted solar-driven hotspot because solar forcing hasn’t increased enough (at least according to the IPCC) to give rise to such a prediction.
Re: “Atomski, read the paper.”
I already read it. Months ago. I even tweeted about it, with a point-by-point rebuttal:
http://archive.is/TJL5W
So please don’t tell me to read things I already read months ago.
Re: “While increased solar forcing could cause a tropical hotspot in principle”
That contradicts with your previous claim that:
“Climate changes due to solar variability or other natural factors will not yield this pattern: only sustained greenhouse warming will do it.”
http://www.financialpost.com/story.html?id=d84e4100-44e4-4b96-940a-c7861a7e19ad&p=1
Or did you not claim that? If you didn’t, then my mistake.
Re: “Only CO2 has increased enough to give rise to a prediction of a tropical hotspot.”
False. As Santer and others have explained multiple times (and as I did again in my previous comment), the hot spot comes with any significant surface warming in the tropics, regardless of the cause of the warming. So, for example, non-CO2-induced ENSO-induced warming will result in a hot spot.
Please take your advice and read some of the literature on this. The following thread can help in getting you start on this:
https://twitter.com/AtomsksSanakan/status/1041020094678224896
Santer et al. touch on this point as well:
“satellite estimates of tropical amplification on monthly to interannual time scales (Yulaeva and Wallace 1994; Hegerl and Wallace 2002; Santer et al. 2005; Karl et al. 2006)”
https://journals.ametsoc.org/doi/pdf/10.1175/JCLI-D-16-0333.1
Re: “The absence of the hotspot therefore only conflicts with one prediction. It doesn’t conflict with a predicted solar-driven hotspot because solar forcing hasn’t increased enough (at least according to the IPCC) to give rise to such a prediction.”
False, again. For example, a solar-induced surface warming effect occurs when TSI increases during part of the 11-year solar cycle. A hot spot results from this solar-induced surface warming, as one would expect for the latent heat release mechanism behind the negative lapse rate feedback. This is seen in both models and observational analyses (though I’m not a huge fan of the NCEP re-analysis). The following sources offer some more background on this:
https://journals.ametsoc.org/na101/home/literatum/publisher/ams/journals/content/atsc/2013/15200469-70.1/jas-d-12-0214.1/20121225/images/medium/jas-d-12-0214.1-f2.gif
[from: “Observed tropospheric temperature response to 11-yr solar cycle and what it reveals about mechanisms”]
“Patterns of tropospheric response to solar variability”
“Why must a solar forcing be larger than a CO2 forcing to cause the same global mean surface temperature change?”
I’m also interested in your claim that:
“It doesn’t conflict with a predicted solar-driven hotspot because solar forcing hasn’t increased enough (at least according to the IPCC) to give rise to such a prediction.”
I find that interesting, since you’re co-author John Christy makes conflicting claims on this subject. In the source below, he uses a cumulative TSI index (which is nonsense, by the way) to claim that TSI increased enough to account for much of the tropospheric and surface warming:
Pages 18 and 68 of: “On the Existence of a “Tropical Hot Spot” & The Validity of EPA’s CO2 Endangerment Finding”
Yet then he switches to claiming that a cumulative TSI index is arbitrary and should be avoided (I agree with that). Instead, he uses a non-cumulative TSI (which is sensible) to argue that the post-1979, multi-decadal TSI changes won’t affect the tropospheric warming trend much:
Page 514 of: “Satellite bulk tropospheric temperatures as a metric for climate sensitivity”
So I hope you and Christy can work together to resolve his self-contradictory position on solar-induced warming. And if he does think that a cumulative TSI can be used to show multi-decadal, solar-induced warming of the surface and troposphere, then does he think that solar-induced warming results in a hot spot? And by “hot spot” I mean what Christy means by it: warming that amplifies from the near-surface or surface to the upper troposphere in the tropics. To borrow words from a document Christy co-authored:
“Section IV. Tropical Hot Spot Hypothesis Testing
The proper test for the existence of the THS [tropical hot spot] in the real world is very simple. Are the slopes of the three trend lines (upper & lower troposphere and surface) all positive, statistically significant and do they have the proper top down rank order?”
https://thsresearch.files.wordpress.com/2016/09/wwww-ths-rr-091716.pdf
Re: “Our interpretation of the results is that the major hypothesis in contemporary climate models, namely the theoretically-based negative lapse rate feedback response to increasing greenhouse gases in the tropical troposphere, is flawed.”
Which doesn’t make sense as an interpretation. For instance, a number of papers have shown that the models do fairly well when it comes to representing the ratio on near-surface (or surface) warming to tropospheric warming. Parallel point for the ratio of upper tropospheric warming to lower tropospheric warming. And it’s those ratios, not the total amount of tropospheric warming, that would tell you about the negative lapse rate feedback. After all, the negative lapse rate feedback is about transferring near-surface energy up the troposphere, where that energy can be more easily radiated away.
Anyway, some of the papers I was talking about regarding ratios:
“Troposphere-stratosphere temperature trends derived from satellite data compared with ensemble simulations from WACCM”
Figure 1: “Common warming pattern emerges irrespective of forcing location”
Page 2285: “Removing diurnal cycle contamination in satellite-derived tropospheric temperatures: understanding tropical tropospheric trend discrepancies”
Figure 9 and page 384: “Comparing tropospheric warming in climate models and satellite data”
“Revisiting the controversial issue of tropical tropospheric temperature trends”
So if McKitrick’s interpretation fails, then what other interpretation(s) would be more plausible? To put this another way: if the models do fairly well when it comes to representing the ratio of near-surface warming and tropospheric warming, then why would there be a difference between estimates of tropospheric warming and model-based projections of that warming?
There are at least two other plausible explanations:
1) Errors in the inputted forcings: This wouldn’t represent a flaw in the climate models themselves, in contrast to McKitrick’s interpretation that climate models represent the negative lapse rate feedback. Santer et al. argue fairly persuasively for this explanation in:
“Causes of differences in model and satellite tropospheric warming rates”
2) Residual artifacts/heterogeneities in the radiosonde record: There has been a long history of scientists needing to correct heterogeneities in the radiosonde record. For example, there needed to be corrections for changes in radiosonde shielding against direct solar heating, as covered in papers such as:
“Biases in stratospheric and tropospheric temperature trends derived from historical radiosonde data”
“Radiosonde daytime biases and late-20th century warming”
“Toward elimination of the warm bias in historic radiosonde temperature records—Some new results from a comprehensive intercomparison of upper-air data”
There are likely remaining heterogeneities in the radiosonde analyses, as discussed in:
“Internal variability in simulated and observed tropical tropospheric temperature trends”
The aforementioned paper was also more comprehensive than McKitrick’s analysis. For example, that paper includes the IUKv2 radiosonde analysis (from: “Atmospheric changes through 2012 as shown by iteratively homogenized radiosonde temperature and wind data (IUKv2)”) that shows greater tropical tropospheric warming and which McKitrick conveniently left out of his analysis. I get it’s easier to show a discrepancy between model-projections and radiosonde analyses, when one makes sure to exclude a radiosonde analysis that would mitigate the discrepancy.
You say ‘some of the papers I was talking about regarding ratios’ but only mention 1 paper… which deals with 1 model! And it looks like it’s not one of the CMIP5 models (honestly it’s the first time I hear about WACCM).
The Vogelsang and Nawaz paper doesn’t report the amplification ratios for the models, but it’s clear from their table 8 that amplification in the observations is well below that of models for almost all surface/troposphere pairings. In most cases the 95% confidence interval for the amplification ratio is barely above 1.
https://msu.edu/~tjv/Trend-slopes-ratio-final.pdf
Re: “You say ‘some of the papers I was talking about regarding ratios’ but only mention 1 paper… which deals with 1 model! “
No, I mentioned at least 5 papers covering multiple models. Once again, the papers included:
“Troposphere-stratosphere temperature trends derived from satellite data compared with ensemble simulations from WACCM”
Figure 1: “Common warming pattern emerges irrespective of forcing location”
Page 2285: “Removing diurnal cycle contamination in satellite-derived tropospheric temperatures: understanding tropical tropospheric trend discrepancies”
Figure 9 and page 384: “Comparing tropospheric warming in climate models and satellite data”
“Revisiting the controversial issue of tropical tropospheric temperature trends”
You’re acting like I only cited the first paper on that list.
Re: “And it looks like it’s not one of the CMIP5 models (honestly it’s the first time I hear about WACCM).”
If you hear about something for the first time, then look it up, instead of inventing false claims about it.
Why did you claim that WACCM is not one of the CMIP5 models? How do you square your claim with sources such as?:
“Fifteen models with a top above 1 hPa, including CESM1 (WACCM), are participating in CMIP5—a threefold increase from the previous assessment”
https://journals.ametsoc.org/doi/pdf/10.1175/JCLI-D-12-00558.1
“The following table lists the models for which CMIP5 simulation data can be downloaded.
[…]
CESM1(WACCM)”
https://portal.enes.org/data/enes-model-data/cmip5/resolution
Re: “The Vogelsang and Nawaz paper doesn’t report the amplification ratios for the models, but it’s clear from their table 8 that amplification in the observations is well below that of models for almost all surface/troposphere pairings. In most cases the 95% confidence interval for the amplification ratio is barely above 1.”
The article you linked to is from 2015/2016. The table 8 you reference from it uses satellite-based analyses, not the radiosonde-based analyses that McKitrick discussed in his above blogpost. The two satellite-based analyses it uses are UAH and an older version of RSS. That older version of RSS under-estimates tropospheric warming, as admitted by RSS in papers from 2016 and 2017:
“Sensitivity of satellite-derived tropospheric temperature trends to the diurnal cycle adjustment”
“A satellite-derived lower tropospheric atmospheric temperature dataset using an optimized adjustment for diurnal effects”
Obviously, this means the article you linked to under-estimated that amplification ratio, since it used an under-estimate of the tropospheric warming. I already cited papers from you that use the more recent RSS analysis. Here they are again:
“Troposphere-stratosphere temperature trends derived from satellite data compared with ensemble simulations from WACCM”
“Comparing tropospheric warming in climate models and satellite data”
“Causes of differences in model and satellite tropospheric warming rates”
In addition to RSS, there are at least 4 other satellite-based tropical tropospheric warming analyses. These other analyses include UW, NOAA/STAR, UMD, and an analysis Weng+Zou, though I’m not a huge fan of that last one. With the likely exception of UAH, all of the most updated analyses show a hot spot, with tropical amplification ratios greater than 1. For more on these analyses, see:
NOAA/STAR: “Troposphere-stratosphere temperature trends derived from satellite data compared with ensemble simulations from WACCM”
UW, NOAA/STAR: “Removing diurnal cycle contamination in satellite-derived tropospheric temperatures: understanding tropical tropospheric trend discrepancies”
UMD: “Temperature trends at the surface and in the troposphere”
Weng+Zou: “30-year atmospheric temperature record derived by one-dimensional variational data assimilation of MSU/AMSU-A observations”
So to recap, the article you linked to:
1) Uses outdated satellite-based analyses
2) Does not include all the pertinent satellite-based analyses
Thus your linked article doesn’t do much to argue against the evidence I cited for a tropical amplification ratio of greater than 1. There are other lines of evidence supporting tropical amplification ratios of greater than 1, such as radiosonde-based analyses, re-analyses, and indirect tests tropical precipitation patterns. But I think what I covered so far suffices for now.
In addition to RSS, there are at least 4 other satellite-based tropical tropospheric warming analyses. These other analyses include UW, NOAA/STAR, UMD, and an analysis Weng+Zou, though I’m not a huge fan of that last one. With the likely exception of UAH, all of the most updated analyses show a hot spot,
Incorrect.
None of the up to date analyses, neither, UAH, nor RSS, nor NOAA/STAR, nor RATPAC indicate a hot spot!
I challenged you to examine the peer-reviewed data for yourself.
You have not. Nothing in the volumes of filibuster you have exuded changes the fact that no hot spot appears:
https://i0.wp.com/turbulenteddies.files.wordpress.com/2018/07/hot_spot_1979_2017.png
Re: “None of the up to date analyses, neither, UAH, nor RSS, nor NOAA/STAR, nor RATPAC indicate a hot spot!”
False.
You’ve already been cited evidence on the hot spot existing on multiple occasions
https://judithcurry.com/2018/07/22/the-perils-of-near-tabloid-science/#comment-877599
https://judithcurry.com/2018/07/22/the-perils-of-near-tabloid-science/#comment-877182
https://judithcurry.com/2018/07/22/the-perils-of-near-tabloid-science/#comment-877429
In response, you simply brushed off the evidence (from the peer-reviewed papers I cited to you), by claiming that citing peer-reviewed evidence is just “motivated parrotry”:
https://judithcurry.com/2018/07/22/the-perils-of-near-tabloid-science/#comment-877614
By your logic, a flat Earther can brush off all the peer-reviewed studies that present evidence that Earth is round, by claiming that citing those studies is just “motivated parrotry”. In fact, by your logic, Judith Curry and [every other scientist who cites references in their peer-reviewed papers that provide evidence supporting a point they made] is engaged in “motivated parrotry”. It’s as if you have no clue how evidence is cited in science.
Atom, do you have a theory as to why when I plot the trends for the various data sets, no hot spot appears?
Re: “Atom, do you have a theory as to why when I plot the trends for the various data sets, no hot spot appears?”
That depends on the false assumption that the hot spot doesn’t actually appear. It appears for ERA-I, NOAA/STAR (relative to near-surface warming), etc. with a lapse rate reduction where mid-to-upper tropospheric warming is greater than near-surface warming in the tropics.
You also don’t make it clear how you generate your analyses. And also seem to be a non-expert when it comes to these data-sets, unlike the scientists who authored the peer-reviewed research I cited to you. Thus those scientists are more likely to be aware of important issues that you overlook, such as residual artifacts/heterogeneities in the data and how to plot/analyze that data to account for those artifacts/heterogeneities.
I also tend not to trust the non-peer-reviewed analyses you generate, since you previously relied on the following fabricated, non-peer-reviewed image you found on a contrarian blog (like JoAnne Nova’s blog):
http://jonova.s3.amazonaws.com/graphs/hot-spot/hot-spot-model-predicted.gif
https://judithcurry.com/2018/07/03/the-hansen-forecasts-30-years-later/#comment-876316
This is the real, non-fabricated image for the CCSP report:
https://itsnotnova.files.wordpress.com/2013/02/fourmodels.png
[Figure 5.7 on page 116 of: “Temperature trends in the lower atmosphere: Steps for understanding and reconciling differences”]
https://downloads.globalchange.gov/sap/sap1-1/sap1-1-final-all.pdf
But you don’t display CCSP’s 1979 – 1999 model-based projections from the above image. Instead you display an image that removes the 1979 – 1999 model-based projections, and replaces them with model-based projections for 1959 – 1999. How does that make any sense? Why are you comparing a data analysis for a 21-year period, to model-based projections for a 41-year period?
Moreover, the color-scales also differ between the HadAT2 data analysis you showed vs. the model-based projections. For instance, warming of ~0.2°C/decade would appear yellow on the HadAT2 image. In contrast, that same rate of warming would be ~0.8°C on the 1958 – 1999 CCSP model-based image and would appear dark orange (almost red), not yellow.
So you illegitimately exaggerated any model vs. data differences, by manipulating the time-scale and the color-scale. And that’s not even touching on the other errors you made, such as you:
1) evading what the CCSP actually said in their report
2) not addressing the pre-1979 data, since it shows the hot spot that you’re trying to dodge
3) evading subsequent analyses that shows the hot spot
4) not addressing the known errors in post-1979 radiosonde-based trends, that result in an under-estimation of post-1979 tropical tropospheric warming [something the CCSP report itself notes]
And so on.
This has been pointed out to you before, yet you still don’t retract the fabricated image:
https://judithcurry.com/2018/07/22/the-perils-of-near-tabloid-science/#comment-877182
Given your willingness to post fabricated, non-peer-reviewed images without retracting them, I have no reason to trust you when you present your own non-peer-reviewed analyses.
Pingback: Computer climate simulations just crashed | Tallbloke's Talkshop
Thanks for this excellent overview Ross. All your links to papers worked. This, plus all the papers, will keep me reading for ages.
GHGE is one of the most propagandised issues in climate. It’s the foundation for climate alarmism. Yet also something the IPCC and climate establishment put very little effort into attempting to explain. They like to keep at at the slogan level of “us versus them”. “Belief everything we claim we said about GHGE” – you’re a responsible citizen. Disagree over any aspect of GHGE – then you’re a ‘denier’.
Reblogged this on Utopia – you are standing in it!.
Oops, I thought the bunch of figures etc you quoted were from the first paper. (Btw, you don’t cite what in particular in that paper deals with trend ratios – could you specify?).
About the papers:
Figure 1: “Common warming pattern emerges irrespective of forcing location”
No trend for warming rate at different heights is given – are we supposed to eyeball a trend from the chart? Maybe a trend ratio is given somewhere else the paper… since you cited it and the specific figure, I’m not going make the effort.
Page 2285: “Removing diurnal cycle contamination in satellite-derived tropospheric temperatures: understanding tropical tropospheric trend discrepancies”
This one does report amplification ratios for TMT vs surface. (I know this blog post is looking at TMT trends, Vogelsang’s paper was about TLT-to-surface amplication). The models’ ratios are perhaps consistent with the models over the oceans (save for UAH) but they are obviosly inconsistent over land – all the datasets give amplification ratios there well below 1 (taking ‘surface’ as HadCRUT), whereas for the models it’s over 1.
Figure 9 and page 384: “Comparing tropospheric warming in climate models and satellite data”
This is a ratio of TMT to TLT, not of either of those vs surface.
“Revisiting the controversial issue of tropical tropospheric temperature trends”
The amplification is shown in figure 3. This paper only deals with one radiosonde record, and only uses data up to 2008.
In short, among the papers you cited only two discuss troposphere-to-surface amplification in a way that can be quantified (another does not provide trends, at least not in the part you cited, and another does not give data on amplification vs surface – again, in the part you cited). Among the other two, one uses a single radiosonde dataset and has data only up to 2008 (odd – the paper is from 2013). Finally, the paper “Removing diurnal cycle contamination in satellite-derived tropospheric temperatures: understanding tropical tropospheric trend discrepancies” has the most evidence on the issue: amplification ratios of TMT vs surface, over the tropics, are consistent between models and observations over the ocean but inconsistent over land.
‘With the likely exception of UAH, all of the most updated analyses show a hot spot, with tropical amplification ratios greater than 1’
That will depend on what you’re comparing to what, as there are dozens of possible matches between satellite, radiosonde and surface records.
‘The article you linked to is from 2015/2016. The table 8 you reference from it uses satellite-based analyses, not the radiosonde-based analyses that McKitrick discussed in his above blogpost.’
Not sure what point you’re making. McKitrick’s blog post or paper does not attempt to estimate trend ratios, i.e. amplification – it simply mentions past papers on the issue. I brought up Vogelsang’s paper because you were talking about amplification ratios.
You also cite two more papers.
‘Temperature trends at the surface and in the troposphere’
Unless there is a more recent paper with exactly the same name, this one is from 2006.
’30-Year atmospheric temperature record derived by onedimensional
variational data assimilation of MSU/AMSU-A
observations’
This is a satellite-based temperature estimate that ends in 2011. While it does show stronger warming over 700mb than over regions closer to the surface, the paper does not provide any estimate of the amplification ratio, or any comparison with a surface dataset.
‘So to recap, the article you linked to:
1) Uses outdated satellite-based analyses
2) Does not include all the pertinent satellite-based analyses’
Well, look on the bright side: it’s less outdated and incomplete than almost all the studies you cited.
More seriously, should Vogelsang or whoever do another paper now including RSS 4.0, etc? Yes. But they don’t churn out these papers every month. If you’re looking for something specific, not even every year.
Obviously that comment was meant as a response to Atomsk.
You didn’t answer my question. Once again:
Why did you falsely claim that WACCM wasn’t a CMIP5 model?
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881073
Re: “I’m not going make the effort.”
That’s your issue to deal with.
Re: “No trend for warming rate at different heights is given – are we supposed to eyeball a trend from the chart? Maybe a trend ratio is given somewhere else the paper”
Please “make the effort” to read the figure’s legend:
“Hemispherically averaged linear trend of tropospheric temperature between 1979 and 2005 divided by the global mean of the skin temperature”
https://agupubs.onlinelibrary.wiley.com/doi/pdf/10.1002/2017MS001083
So the figure shows trend ratios, by dividing the tropospheric warming rate by the near-surface warming rate. Trends ratio of orange or red are greater than 1, and there are clearly trend ratios above 1 in the tropical upper troposphere based on those colors:
https://pbs.twimg.com/media/Dg-81hSWAAUytWP.jpg
[from: “Common warming pattern emerges irrespective of forcing location”]
By the way, it’s already known ERA-I under-estimates lower tropospheric warming, which helps account for why there isn’t as much orange in the lower troposphere of the top-left ERA-I panel:
“Estimating low-frequency variability and trends in atmospheric temperature using ERA-Interim”
Section 9: “A reassessment of temperature variations and trends from global reanalyses and monthly surface climatological datasets”
Section 2: “Climate variability and relationships between top-of-atmosphere radiation and temperatures on Earth”
Re: “The models’ ratios are perhaps consistent with the models over the oceans (save for UAH) but they are obviosly inconsistent over land – all the datasets give amplification ratios there well below 1 (taking ‘surface’ as HadCRUT), whereas for the models it’s over 1.”
For future reference, the paper’s ratio uses TTT, not TMT. TTT is a corrected version of TMT, that removes some of the stratospheric cooling that contaminates the TMT analysis.
Also, it looks like you didn’t “make the effort” to read the relevant portions of the paper before commenting on it. If you had read it, then you’d have seen this:
“Our amplification factor over the tropics is consistent with tropical tropospheric amplification implied by models, which is approximately 1.4–1.6 (Santer et al. 2005; Fu et al. 2011). Our amplification factor over land is reduced because of enhanced land surface warming relative to sea surface warming (e.g., Sutton et al. 2007).”
https://journals.ametsoc.org/doi/pdf/10.1175/JCLI-D-13-00767.1
So one would expect the amplification ratios to be lower over land, since land warms more than water. The ratio would also be lower since the oceans provide a readier source of the evaporating water that condenses to drive the hot spot, in contrast to the land. And you’ll also need to account for the fact that horizontal mixing of air higher in the troposphere tends to make tropospheric warming trends over land vs. oceans more similar to each other than are the near-surface (or surface) warming trends for the land vs. the oceans.
Nowhere did you show that the amplification ratio just over land was greater than 1 for the models. No, Christy et al.’s claim doesn’t count, since they were corrected on their abuse of the models with respect to their land mask.
Re: “This is a ratio of TMT to TLT, not of either of those vs surface.”
“While it does show stronger warming over 700mb than over regions closer to the surface, the paper does not provide any estimate of the amplification ratio, or any comparison with a surface dataset.”
You didn’t “make the effort” to read things in context. When citing the paper, I clearly said I was looking at papers covering tropical amplification ratios for the near-surface vs. the tropophere, and for the upper troposphere vs. the lower troposphere. So why are you acting like I only said the former?:
“For instance, a number of papers have shown that the models do fairly well when it comes to representing the ratio on near-surface (or surface) warming to tropospheric warming. Parallel point for the ratio of upper tropospheric warming to lower tropospheric warming.”
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881057
Re: “That will depend on what you’re comparing to what, as there are dozens of possible matches between satellite, radiosonde and surface records.”
Now you’re moving the goal-posts, since you didn’t bring that up as an issue when you were citing the “Vogelsang and Nawaz paper”.
Re: “Unless there is a more recent paper with exactly the same name, this one is from 2006.”
“This is a satellite-based temperature estimate that ends in 2011.”
“Well, look on the bright side: it’s less outdated and incomplete than almost all the studies you cited.”
You seem confused on this. You seem to think that the issue is that the RSS analysis used by Vogelsang and Nawaz is older, or doesn’t include recent years of data. Thus you think that same criticism applies to the papers I cited.
But that was not the issue, as would have been clear if you read what I said to you, or if you read the RSS papers I cited to you. The issue was that Vogelsang and Nawaz used an incorrect version of the RSS analysis, that had a number of deficiencies, such as problems with its diurnal drift correction. That caused that RSS analysis to under-estimate tropospheric for the period of time it covered. I suggest you “make the effort” to read the RSS papers I cited you on this:
“Sensitivity of satellite-derived tropospheric temperature trends to the diurnal cycle adjustment”
“A satellite-derived lower tropospheric atmospheric temperature dataset using an optimized adjustment for diurnal effects”
So the newer version of RSS won’t give the same warming trend as the older version of RSS used by Vogelsang and Nawaz, even if you restrict the two versions to cover the same period of time and even if you exclude some recent years of data (ex: looking at a common period of 1979 – 2009 for the two analyses). That’s illustrated in the graph below for RSS’ lower tropospheric analysis:
https://3.bp.blogspot.com/-j1KHCgHI6x0/WWxsKdLiCHI/AAAAAAAAAe0/amInMXsA3U0GsGIJtM0ZA3NBHa3WI71HQCKgBGAs/s400/RSS%2Band%2BUAH%2BTLT%252C%2B4.PNG
[from: “A satellite-derived lower tropospheric atmospheric temperature dataset using an optimized adjustment for diurnal effects”]
Thus the older version of RSS used by Vogelsang and Nawaz: under-estimated tropospheric warming for the period of time that it covered. You have not shown the same problem applies to the analyses I cited. Pointing out that the analyses I cited came from earlier years (ex: 2006) or don’t include a couple of years of recent data, is not the same thing as they under-estimated tropospheric warming for the period of time they covered.
Re: “Among the other two […]”
You missed the model vs. observational analyses comparisons from the first paper cited:
“Troposphere-stratosphere temperature trends derived from satellite data compared with ensemble simulations from WACCM”
Please make sure you “make the effort” to read the paper before making any false claims on it. It helps to read some of the literature on the topics you discuss, so that you can make informed comments on them. For example, when you read that paper, remember that they are technically looking at tropospheric and stratospheric trends relative near-surface (or surface warming), since they’re forcing the model with observed sea surface temperatures.
Re: “Vogelsang and Nawaz (2017)is an important new contribution to this literature since they provide the first formal treatment of the trend ratio problem.”
Some final points before I hibernate for awhile.
You state that you use RSS and UAH lower tropospheric satellite analyses. But as far as I can tell, you’re unclear on which RSS analysis you used, beyond citing the Klotzbach et al. 2009 paper:
“The sources for the satellite series are the University of Alabama Huntsville (UAH) and Remote Sensing Systems (RSS). For each of the four sources, three temperature series are examined: (i) a land series, (ii) an ocean series and (iii) a land + ocean (global) series. All temperature series are monthly, and additional details on the data and their sources can be found in Klotzbach et al. (2009).”
https://onlinelibrary.wiley.com/doi/full/10.1111/jtsa.12209
There are a number of issues there. One issue is why you chose to look at two satellite-analyses for the lower troposphere, when there are more satellite analyses (at least 6) covering the mid-to-upper troposphere, as discussed here:
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881073
You could have easily used those mid-to-upper tropospheric analyses to calculate amplification ratios relative to near-surface warming. And the results from that would have been more interesting, since the presence of more research groups working in the mid-to-upper troposphere vs. the lower troposphere means there are more competent people around to catch a mistake in any particular satellite-based analysis (such as the RSS team having to repeatedly catch mistakes in UAH’s analyses [for instance, DOI: 10.1126/science.310.5750.972]).
Another issue is that you don’t make it clear what version of RSS you’re using. If you’re using the older version from Klotzbach et al. 2009, then that’s a problem. That older version of RSS under-estimates tropospheric warming, predominately due to issues with it’s diurnal correction, as admitted by the RSS team in these papers from 2016 and 2017:
“A satellite-derived lower tropospheric atmospheric temperature dataset using an optimized adjustment for diurnal effects”
“Sensitivity of satellite-derived tropospheric temperature trends to the diurnal cycle adjustment”
That’s illustrated in this image:
https://3.bp.blogspot.com/-j1KHCgHI6x0/WWxsKdLiCHI/AAAAAAAAAe0/amInMXsA3U0GsGIJtM0ZA3NBHa3WI71HQCKgBGAs/s1600/RSS%2Band%2BUAH%2BTLT%252C%2B4.PNG
[from: “A satellite-derived lower tropospheric atmospheric temperature dataset using an optimized adjustment for diurnal effects”]
So if you used the older version of RSS from Klotzbach et al. 2009, then you under-estimated that amplification ratio, since you used an under-estimate of the lower tropospheric warming. And if that was not the version of RSS you used, then please specify which version you used. The paper of your’s that you cited above is from 2016, with initial submission in 2015. Thus your paper may have failed to include the correction RSS published in 2016 and 2017.
There is already a published comparison of the lower tropospheric warming in the newer RSS version relative to near-surface temperatures. That analysis was co-authored by Carl Mears of the RSS team, and it shows the WACCM climate did fairly well in representing the post-1979 amplification for the RSS lower troposphere analysis:
“Troposphere-stratosphere temperature trends derived from satellite data compared with ensemble simulations from WACCM”
Mears, Thorne, and Hausfather also recently had an AGU conference abstract on this topic as well, explaining why they thought the satellite analyses still under-estimated the lower tropospheric warming. Hopefully they’ll turn that abstract into a peer-reviewed paper relatively soon:
“Understanding and reconciling differences in surface and satellite-based lower troposphere temperatures
[…]
We find large systemic differences between surface and lower troposphere warming in MSU/AMSU records compared to radiosondes, reanalysis products, and climate models that suggest possible residual inhomogeneities in satellite records. We further show that no reasonable subset of surface temperature records exhibits as little warming over the last two decades as satellite observations, suggesting that inhomogeneities in the surface record are very likely not responsible for the divergence.”
http://adsabs.harvard.edu/abs/2017AGUFMGC54C..05H
Atomsk, who is the ‘you’ you’re referring to in your latest post? As in ‘you don’t make it clear what version of RSS you’re using’ and ‘You could have easily used those mid-to-upper tropospheric analyses to calculate amplification ratios relative to near-surface warming’.
The author of this blog post and paper, McKitrick, hasn’t used any version of RSS, nor has he tried to estimate amplification ratios – he mentioned a couple papers that did so as part of the background to this post, but his post is about temperature trends in the middle troposphere, not about the difference in warming rates between surface and troposphere.
I have brought up one of the papers, Vogelsand and Nawaz, which you have criticisms of (though as explained in a previous comment almost all the studies you cite are older / less complete / less relevant to the issue of warming amplification). But I suppose the ‘you’ in your comment isn’t me? Obviously I haven’t used any version of RSS either – I simply cited the paper. So I suppose the ‘you’ in your comment should be ‘they’ – meaning Vogelsang and Nawaz.
Perhaps you’re just commenting a bit too quickly to keep track of things (some 15 out of 95 comments so far in the thread are by you). To take another example, look at your comments wondering what the paper’s second author thinks when compared with that second author’s position in other papers. Of course two coauthors can have mutually contradictory positions on some issues – or, if they agree, it’s because one of the authors has changed his mind about something and now contradicts a previous position of his. In any case, how would you expect McKitrick to tell you what Christy is thinking?
PS: in this other othread you were so eager to fire off the list of papers showing problems with energy-budget sensitivity, your list includes the very paper the author of the blog post was rebutting! Presumably you didn’t even read the blog post as none of your ten or so comments mention any of its content.
https://judithcurry.com/2018/09/05/warming-patterns-are-unlikely-to-explain-low-historical-estimates-of-climate-sensitivity/#comment-880113
Re: “PS: in this other othread you were so eager to fire off the list of papers showing problems with energy-budget sensitivity, your list includes the very paper the author of the blog post was rebutting!”
Read what I wrote again at the very comment you linked to:
“There’s a whole literature pointing out the errors in the low-end energy-budget-model-based climate sensitivity estimates made by Lewis+Curry, among others. Lewis has responded to some of this literature.”
https://judithcurry.com/2018/09/05/warming-patterns-are-unlikely-to-explain-low-historical-estimates-of-climate-sensitivity/#comment-880113
Lewis is the person who wrote the blogpost. So no, I already knew Lewis has responded to some of this work. You’d know this if you’d actually bothered to read what you commented on before commenting on it. As I told you before, please learn to “make the effort” to read things, because you often don’t do that.
Re: “Presumably you didn’t even read the blog post as none of your ten or so comments mention any of its content.”
Once again, if you’d bothered to read my comments for comprehension, then you’d notice that I was rebutting specific false claims people made regarding Lewis’ energy-budget-model-based approach.
So you’re commenting on a blog post that is rebuttal to paper X and the first thing you say is ‘hey, paper X exists!’.
Either:
A) you think nobody is going to read the blog post, so you need to remind them what the post is about. (Though in that case why do you post a dozen paper titles?)
or
B) you just post a bunch of paper titles to push a particular view, and you don’t care what the blog post you’re commenting on deals with. The more the better as people won’t have time to check what each of them says.
Seeing that out of the 7 papers you have cited in your response to me regarding trend amplification there is maybe 1 or at most 2 that are recent and relevant to the topic (of warming amplification in the troposphere vs surface), I’m guessing B.
Re: “So you’re commenting on a blog post that is rebuttal to paper X and the first thing you say is ‘hey, paper X exists!’.”
Once again: read what you’re commenting on, before you invent false claims about it.
Here’s the comment of mine that you linked to:
https://judithcurry.com/2018/09/05/warming-patterns-are-unlikely-to-explain-low-historical-estimates-of-climate-sensitivity/#comment-880113
If you bothered to read that comment, then you’d notice it’s not a response to Lewis’ blogpost. Instead, it’s a response to a false claim that someone else made regarding Lewis’ approach:
“This is Nic’s reply to a paper which attempts to show why the models shoul d be trusted over the temperature record.”
https://judithcurry.com/2018/09/05/warming-patterns-are-unlikely-to-explain-low-historical-estimates-of-climate-sensitivity/#comment-880108
Seriously, it’s not that hard to grasp.
Re: “Seeing that out of the 7 papers you have cited in your response to me regarding trend amplification there is maybe 1 or at most 2 that are recent and relevant to the topic (of warming amplification in the troposphere vs surface)”
I already corrected your false claims on this topic, though it looks like my response is being held up in moderation. Basically, your mistake boils down to you, once again, not reading before you comment. For example, you act as if my citation of the paper was just about the amplification ratio of the troposphere relative to the surface, even though I explicitly said when I first cited the papers that it was also about the ratio of upper tropospheric warming to lower tropospheric warming:
“For instance, a number of papers have shown that the models do fairly well when it comes to representing the ratio on near-surface (or surface) warming to tropospheric warming. Parallel point for the ratio of upper tropospheric warming to lower tropospheric warming.”
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881057
Reading and reading comprehension are important. Please exercise them.
Alberto: the tactics of Atom is very clear. he builts up strawmans. He writes about RSS 4.0 and (of course) he forgets to cite this sentence about the obs-model behaviour: “The troposphere has not warmed quite as fast as most climate models predict.” ( source: http://www.remss.com/research/climate/ ).
The author of this blogpost used neither RSS nor UAH data. He used much longer records and the SNR is higher. The discrepancy between models and obs. are pretty clear. This would mean: The models should be improved for better understanding what’s going on. Atom and a few others here seem not be interested in better knowledge but in propaganda. Sad.
frankclimate,
“The troposphere has not warmed quite as fast as most climate models predict.”
Well, I have a collection of observational datasets showing the temperature in the free troposphere, 850-300 mbar. I would NOT say that “the discrepancy between models and obs. is pretty clear”
https://drive.google.com/open?id=0B_dL1shkWewaUzhXR0xmN3pEN0U
300-200 mbar (used in the present blog post) is not the free troposphere, it is a boundary layer that is better referred to as the tropopause.
Satellite series for the lower troposphere suffer from some rogue elements, most notably the low-trending NOAA-15 TMT, whose low trend isn’t supported by any kind of independent data.
Some datasets suffer even more from motivated choices (aka cherrypicks) of the kind “NOAA-15 is right and NOAA-14 wrong”.
However, such motivated choices have side effects, they produce pronounced indents in the lower troposphere and very evident hotspots
Look at the AMSU-era hotspot (in blue) in this chart:
https://drive.google.com/open?id=0B_dL1shkWewaZl9UdEEzc00zVGM
Models do not time internal variability, and people are using that as an opportunity to rush to judgment, which smells like politics. Do we still have Congressman Lamar Smith on speed dial? Maybe he can hold another public lynching.
A rush to judgment is all over this deal. All these wind turbines and solar panels were because of the impeding death of fossil fuels. The IPCC judged that we more or less caused all the warming. Germany and Australia judged then transformed.
Re: “He writes about RSS 4.0 and (of course) he forgets to cite this sentence about the obs-model behaviour: “The troposphere has not warmed quite as fast as most climate models predict.” ( source: http://www.remss.com/research/climate/ ).”
Once again, if you’d read my comments closely, then you’d realize I already discussed this issue. Here’s my discussion again, removing my citations to supporting evidence:
“To put this another way: if the models do fairly well when it comes to representing the ratio of near-surface warming and tropospheric warming, then why would there be a difference between estimates of tropospheric warming and model-based projections of that warming?
There are at least two other plausible explanations:
“1) Errors in the inputted forcings: This wouldn’t represent a flaw in the climate models themselves, in contrast to McKitrick’s interpretation that climate models represent the negative lapse rate feedback.
[…]
2) Residual artifacts/heterogeneities in the radiosonde record“
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881057
Ironically, the very RSS link you showed agreed with me on this, though you conveniently left this out in the way you selectively quoted the article. That made it easier for you to act as if the only plausible explanation was a flaw in the models that needed to be improved. As the link you mentioned noted:
“Why does this discrepancy exist and what does it mean? One possible explanation is an error in the fundamental physics used by the climate models. In addition to this possibility, there are at least three other plausible explanations for the warming rate differences. There are errors in the forcings used as input to the model simulations (these include forcings due to anthropogenic gases and aerosols, volcanic aerosols, solar input, and changes in ozone), errors in the satellite observations (partially addressed by the use of the uncertainty ensemble), and sequences of internal climate variability in the simulations that are difference from what occurred in the real world. We call to these four explanations “model physics errors”, “model input errors”, “observational errors”, and “different variability sequences”. They are not mutually exclusive. In fact, there is hard scientific evidence that all four of these factors contribute to the discrepancy, and that most of it can be explained without resorting to model physics errors.”
http://www.remss.com/research/climate/
It’s getting tedious seeing so many contrarians cite that RSS page, without them bothering to read what it says first. Reading comprehension is important.
So the RSS page you linked to makes the same point I did: besides model error, there are other plausible explanations for said models vs. observations discrepancy, and these explanations account for most of the difference. That’s in line with what RSS team members have been saying for years, though contrarians always seem to conveniently miss this point when they cite RSS. For example, RSS team member Carl Mears makes similar points in the following sources he co-authored:
Peer-reviewed:
“Causes of differences in model and satellite tropospheric warming rates”
“Comparing tropospheric warming in climate models and satellite data”
Non-peer-reviewed:
“A response to the “Data or Dogma?” hearing”
“Understanding and reconciling differences in surface and satellite-based lower troposphere temperatures
[…]
We find large systemic differences between surface and lower troposphere warming in MSU/AMSU records compared to radiosondes, reanalysis products, and climate models that suggest possible residual inhomogeneities in satellite records. We further show that no reasonable subset of surface temperature records exhibits as little warming over the last two decades as satellite observations, suggesting that inhomogeneities in the surface record are very likely not responsible for the divergence.”
http://adsabs.harvard.edu/abs/2017AGUFMGC54C..05H
The first paper I listed above was even cited at the link you gave, as you would have known if you’d bothered to read what you cited instead of just repeating the quote-mine you likely saw other contrarians post. Here’s RSS referencing the paper:
“For a detailed discussion of all these reasons, see the post on the Skeptical Science blog by Ben Santer and Carl Mears, and the recent paper in Nature Geoscience by Santer et al.”
http://www.remss.com/research/climate/
Re: “The author of this blogpost used neither RSS nor UAH data.”
He cited a paper that did use RSS and UAH analyses:
“Vogelsang and Nawaz (2017)is an important new contribution to this literature since they provide the first formal treatment of the trend ratio problem.”
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/
He’s also repeatedly used RSS and UAH analyses in his blogposts on this forum. For instance:
https://judithcurry.com/2017/09/26/are-climate-models-overstating-warming/
https://judithcurry.com/2018/07/03/the-hansen-forecasts-30-years-later/
Atomsk’s Sanakan: In fact, there is hard scientific evidence that all four of these factors contribute to the discrepancy, and that most of it can be explained without resorting to model physics errors.”
So there is after all a model/data discrepancy? The existence of multiple explanations of why the model may be inaccurate hardly supports the claim that any aspect of the model is in fact reliable. And if, as asserted, “all four of these factors contribute to the discrepancy”, it would be nice to have succinct and accurate descriptions of the “model physics errors”.
They don’t have multiple independent estimates of the quantitative effects of the separate sources of error, and can not rule out any of them being large enough to the be principal source of the discrepancy. It is difficult (impossible?) at this time to track the effects of small errors, that is “the propagation of errors” through the large number of calculations entailed in the model output.
Your efforts are heroic, but you always come up short of showing an agreement between model and data of the tropical hot spot. As with this quote, a discrepancy always emerges.
The bias, if such it is, is in the sense of the models underestimating the sensitivity by overestimating the negative lapse rate feedback. This is a rare case where the skeptics are wishing for more sensitivity in the models, or they haven’t figured out the implications yet.
Atom: I second Matthew in this point- the discrepancy persists with the data of radiosondes, used by Ross in this paper. The discussion of the possible reasons for it in the sat-data brings no progress in this issue. The discrepancy is real, this is the outcome. The three reasons described by Meaers are cutted to 2: forcing-errors or intrinsic model errors. To be clear: I know that models are useful and I know that they have to be improved. So please stop your crossfire and wild speculations about “contrarians”.
best Frank
The bias, if such it is, is in the sense of the models underestimating the sensitivity by overestimating the negative lapse rate feedback. This is a rare case where the skeptics are wishing for more sensitivity in the models, or they haven’t figured out the implications yet.
I hope you recognize that your argument can be turned completely around –
that is:
Feedback is more positive but we still have low end warming.
But there’s another possibility that you keep ignoring.
That is, lapse rate feedback has been less but so to has water vapor feedback been less.
you could of course removef ENSO and volcano signals
https://media.springernature.com/m685/nature-assets/ngeo/journal/v7/n3/images/ngeo2098-f1.jpg
TE, that makes no sense because the lapse rate feedback is for a given water vapor feedback, and the water vapor feedback is for a given surface temperature change. These are all normalized to surface temperature changes, as feedback are defined.
Re: ” The existence of multiple explanations of why the model may be inaccurate hardly supports the claim that any aspect of the model is in fact reliable.”
You’re misrepresenting what I said and what Mears said. The claim was not that “[there are] multiple explanations of why the model may be inaccurate”. Instead, the point was that “there are multiple other explanations that are more plausible, and which imply no flaw in the models”.
This is one of the fundamental problems that people like you, McKitrick, etc. have: you falsely assume that whenever there’s a difference between a model and a observational analysis, then the model must be wrong. In science we know that isn’t true, since there have been multiple cases in which the model was right and the observational analyses was wrong. A class example of that was the GCMs that said the troposphere should be warming, when Christy’s UAH analysis said the troposphere was cooling. It turned out Christy’s UAH analysis was wrong for a number of reasons, including his failure to adequately account for diurnal drift and orbital decay. For more background on that, see:
https://pbs.twimg.com/media/DnqoAGNW4AA-o-R.jpg
(from: “Correcting temperature data sets”)
“The reproducibility of observational estimates of surface and atmospheric temperature change”
“The effect of diurnal correction on satellite-derived lower tropospheric temperature”
“Effects of orbital decay on satellite-derived lower-tropospheric temperature trends”
There are other examples in other fields of science, where the model was right and the observational analysis was wrong. One example is physics models where faster-than-light neutrinos are not possible, in contrast to a (now debunked) observational analysis that claimed this was possible. If you want further examples, then see:
From 33:34 to 40:39 :
“Tyndall Lecture: GC43I. Successful Predictions – 2012 AGU Fall Meeting”
https://www.youtube.com/watch?v=RICBu_P8JWI&t=2014s
Re: “Your efforts are heroic, but you always come up short of showing an agreement between model and data of the tropical hot spot.”
Not really. I regularly cite evidence. You simply ignore it, because you’re not willing to read the published research. For instance:
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881057
Re: “Atom: I second Matthew in this point- the discrepancy persists with the data of radiosondes, used by Ross in this paper. The discussion of the possible reasons for it in the sat-data brings no progress in this issue.”
False.
First, the discussion of those reasons would be pertinent here. For instance, the flaws in inputted would apply to the model-based projections that are compared to radiosonde analyses, and to the model-based projections that are compared to satellite analyses.
Second, I already cited you sources on how these explanations apply to comparisons to radiosonde-based analyses. For example:
“There are likely remaining heterogeneities in the radiosonde analyses, as discussed in:
“Internal variability in simulated and observed tropical tropospheric temperature trends””
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881057
Third, it’s ironic that you claim “no progress” is made, just because the progress isn’t going in the direction of your preferred conclusion that the models are wrong. That’s confirmation bias on your part.
Re: “The three reasons described by Meaers are cutted to 2: forcing-errors or intrinsic model errors.”
Nope. For instance, as I explained to you again above the “errors in the [radiosonde] observations” explanation is still on the table, due to remaining artifacts/heterogeneities in the radiosonde-based analyses.
Atomsk’s Sanakan: you falsely assume that whenever there’s a difference between a model and a observational analysis, then the model must be wrong.
No. The inference I draw is that the model has not been shown to be correct, or at least not accurate enough to be relied upon.
But you hit on a well-recognized problem with Popper’s falsification/strict_testing philosophy. It is seldom possible to tell from a model failure what feature of the model or the ancillary assumptions is at fault.
Re: “No. The inference I draw is that the model has not been shown to be correct, or at least not accurate enough to be relied upon.”
You clearly said that the explanations said that the model was inaccurate:
“The existence of multiple explanations of why the model may be inaccurate hardly supports the claim that any aspect of the model is in fact reliable”
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881141
You were shown to be wrong, since three of the explanations imply no flaw in the models, and thus they do not assume the model is accurate. They are not offered as explanations of why the model is inaccurate, contrary to what you said. Please don’t pretend you didn’t say things you clearly said, when your claims are shown to be wrong. And I suggest you actually read some of the material cited to you, instead of inventing false claims about what was said. For instance:
“A response to the “Data or Dogma?” hearing”
[…]
[…] temperature trends in the perfect model and perfect observations would diverge if there were errors in the inputs to the model simulations, or if the purely random sequences of internal climate oscillations did not “line up” in the simulations and in reality […]”
“Volcanic contribution to decadal changes in tropospheric temperature
[…]
Even a hypothetical ‘perfect’ climate model, with perfect representation of all the important physics operating in the real-world climate system, will fail to capture the observed evolution of climate change if key anthropogenic and natural forcings are neglected or inaccurately represented.”
Atomsk, I’m not quite sure if the cited statements on http://www.remss.com/research/climate/ are matching the theme of the mainpost. It was about the 200…300 mb T trends ( about 10…12km hight) in the tropics. Your cited statements are about TLT. To remember you it was stated there: “Fig. 2. Tropical (30S to 30N) Mean TLT Anomaly plotted as a function of time….indicating that the simulations as a whole are predicting more warming than has been observed by the satellites.” When you look at the in TLT observed hights you may find, that the 200…300mb band is not involved in this record. So IMO your comments with this citings included are o/t.
Re: “Atomsk, I’m not quite sure if the cited statements on http://www.remss.com/research/climate/ are matching the theme of the mainpost. It was about the 200…300 mb T trends ( about 10…12km hight) in the tropics. Your cited statements are about TLT.”
No, it’s relevant. To see why, note that in addition to TLT, there’s TMT and TTT. TTT corrects for the stratospheric cooling that contaminates TMT. TTT and TMT include the 200mb – 300mb area in the tropics (including heights of 10 – 12km), as depicted in the image at the left here:
http://images.remss.com/msu/msu_time_series.html
So if the explanations+statements apply to TMT or TTT, then they are applicable to the theme of the mainpost.
Now, remember that I previously quoted this portion of the RSS link for you:
“For a detailed discussion of all these reasons, see the post on the Skeptical Science blog by Ben Santer and Carl Mears, and the recent paper in Nature Geoscience by Santer et al.”
http://www.remss.com/research/climate/
I noted that I had already cited the paper they were talking about there. That paper covers TMT. Or more precisely, the paper discusses TTT (TMT corrected for stratospheric cooling). That paper also discusses the 4 explanations mentioned at the RSS link (the explanations I also went over) and applies them to TTT. Here’s that paper again:
“Causes of differences in model and satellite tropospheric warming rates”
Moreover, the “Skeptical Science post” mentioned in that RSS quote also applies the explanations+statements to TMT. I cited that article to you previously; it is:
“A response to the “Data or Dogma?” hearing”
So no, the discussion at the RSS link was pertinent to the them of the mainpost, since the cited explanations apply to the TMT and TTT analyses that cover the 200mb – 300mb in the tropics. This is clearly shown by the documents linked on that RSS page, not to mention the other sources I cited for you.
Re: “It was about the 200…300 mb T trends ( about 10…12km hight) in the tropics. […] When you look at the in TLT observed hights you may find, that the 200…300mb band is not involved in this record.”
TLT receives a slight contribution from that layer. See the image at the left side of the page for:
http://images.remss.com/msu/msu_time_series.html
Atomsk, please focus on the mean points. The altitude band of 200…300 mb has only an influence on TLT of about 10% at max. following your figure. Please stop this fireing of smoke grenades when it comes to the behaviour of the temperatures in the altitudes in question! All your citings are o/t.
Re: “Atomsk, please focus on the mean points. The altitude band of 200…300 mb has only an influence on TLT of about 10% at max. following your figure. Please stop this fireing of smoke grenades when it comes to the behaviour of the temperatures in the altitudes in question! All your citings are o/t.”
Looks like you can’t rebut what I said, so you’re simply evading.
Once again:
1) You were the one who brought up the RSS link, not me. So if you think it’s irrelevant to the main them of the post, then that’s your fault.
2) I already showed you that the pertinent points from the link apply to TMT and TTT, which are both layers that encompass 200mb – 300mb in the tropics. I showed you this using direct quotations from the RSS link, showing that the page cited sources (including sources co-authored by RSS team members) that applied those points to TMT and TTT.
Face it: you incorrectly thought the RSS page’s points only applied to TLT, because you didn’t bother to read any of the sources linked on the RSS page, nor did you bother to read the peer-reviewed literature on this subject. Now that it’s clear that those sources and that link rebut your claims, you’re trying to evade them by calling citation of them “fireing [sic] of smoke grenades”. Sorry, but that’s not going to work.
The points were explicitly applied to TMT and TTT. You didn’t know this. You were wrong. Get over it.
Olof, I refered to the conclusion ot the mentioned reviewed paper in the mean post:
“Comparing observed trends to those predicted by models over the past 60 years reveals a clear and significant tendency on the part of models to overstate warming. All 102 CMIP5 model runs warm faster than observations, in most individual cases the discrepancy is significant, and on average the discrepancy is significant.”
IMO fig. 3 of McKitrick et al (2018) illustrates this very clear:
https://i.imgur.com/7u4jG9Q.jpg
The implication for the GCM should be: they have to be improved when we want to know more about the climate of the future. The only way for this is the application of RELIABLE models.
Yes, I agree that the temperature trend in this tropical tropopause layer (about 3% of the atmosphere by mass) is significantly larger in models than in observations.
And it is not necessary to make graphs with dishonest alignment to demonstrate this (I see no common baseline in the graph you are showing except for the start, 1958).
The temperature of the tropical tropopause is very sensitive to ENSO. Models have much larger trends in Nino 3.4 SST compared to observations, which seemingly explains most of the divergence aloft.
Pick a period when the Nino 3.4 trend is similar in models and real world, for instance 2000-2017, and the divergence in the tropical tropopause will largely disappear.
The problem with models is not necessarily small scale physics concerning cloud properies, lapse rate etc. I think the problems are more large scale, ie reproducing trade wind and ENSO patterns in the Pacific..
Olof, re “dishonest graph”: It’s the figure 3 of the paper in question. And I can’t see anything “dishonest” but Ross could better respond IMO. The axis are labeled and the graphs show that the model mean calculates an increase in the temperatures of about 1.8 K but the obs. give only 0,8K between about 1962 and 2017. And yes: the temperatures are sensitive to ENSO ( of course) and the graph of the obs. shows this also.
The source of the divergence: The paper says nothing, it only shows it. My guess: The models show much more deviation after about 1995 then before. The GHG forcing increased after 1995 and the ERF aero stagnated more or less. If the models would be too sensitive to GHG forcing (see L/C 18) which was compensated before 1995 with ERFaero it would give the behaviour seen in the cited figure.
Re: “Olof, re “dishonest graph”: It’s the figure 3 of the paper in question. And I can’t see anything “dishonest” but Ross could better respond IMO. “
The graph chooses a very short baseline (if the graph even uses the same baseline for the model-based trends as for the observational analyses) in order to exaggerate any differences. Christy does this habitually, no matter how many times other scientists point it out:
http://www.realclimate.org/index.php/archives/2016/05/comparing-models-to-the-satellite-datasets/?wpmp_tp=1
And the paper also illegitimately excludes a radiosonde analysis (IUKv2) that shows more warming, as I discussed elsewhere:
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881057
Re: “The source of the divergence: The paper says nothing, it only shows it.”
False. The paper suggests that the source of the discrepancy is that the models misrepresent the lapse-rate feedback:
“Our interpretation of the results is that the major hypothesis in contemporary climate models, namely, the theoretically based negative lapse rate feedback response to increasing greenhouse gases in the tropical troposphere, is incorrect.”
https://agupubs.onlinelibrary.wiley.com/doi/pdf/10.1029/2018EA000401
McKitrick even re-iterates this point near the end of his blogpost.
Re: “My guess: The models show much more deviation after about 1995 then before. The GHG forcing increased after 1995 and the ERF aero stagnated more or less. If the models would be too sensitive to GHG forcing (see L/C 18) which was compensated before 1995 with ERFaero it would give the behaviour seen in the cited figure.”
Your guess is wrong, as shown by the very RSS page you linked to before (without you actually having read it). I explained that to you before, while citing other evidence against against your explanation. Once again:
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881126
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881057
“In fact, there is hard scientific evidence that all four of these factors contribute to the discrepancy, and that most of it can be explained without resorting to model physics errors.”
http://www.remss.com/research/climate/
This paper in particular (which I cited before, is cited on the RSS page you linked to, and is co-authored by members of the RSS team) argues against your particular explanation:
“Causes of differences in model and satellite tropospheric warming rates”
That papers gives at least three arguments against what you said:
1) If the models are much too sensitive to CO2, then there should be a specific discrepancy between observed climate responses to volcanic eruptions vs. the models’ predicted response to said eruptions. But this discrepancy does not appear.
2) If the over-sensitivity accounts for most of the post-1998 model-observations discrepancy, then models should exaggerate pre-1998 CO2-induced warming as well. So there should be a similar pre-1998 model-observations discrepancy with respect to tropospheric warming. Yet this pre-1998 discrepancy] is not evident.
3) A statistical, model-based test using a proxy for each model’s climate sensitivity argues against your model-sensitivity explanation.
And I find it interesting that you’re referencing climate sensitivity, since the paper side-steps using the tropical tropospheric warming to make claims about climate sensitivity. After all, the paper is trying to say that the flaw is with the models’ representation of the negative lapse rate feedback. And that feedback is a negative feedback on warming. So if climate models over-estimate that negative feedback, that would imply the models are under-estimating climate sensitivity, not over-estimating it.
Judy, I have a comment in moderation and I swear: there is nothing inside which would brake the blog rules :-)
Moderation queue has been very erratic, 9 were caught overnite. I will check as often as I can to release them.
Atomski, the reason we didn’t use IUKv2 is that it hasn’t been updated to 2017. Christy et al. included it (and the reanalysis products) in “Examination of space-based bulk atmospheric temperatures used in climate research” IJRS 2018. Using the 1979-2015 interval the tropical midtroposphere trend in IUKv2 is in between the two updated Wien products we use.
You refer to studies about whether amplified warming aloft in the tropics appears on time scales of solar cycles and ENSO periods. But we are looking at 60-year trends. If you want to attribute a relatively high fraction of any such trend to increasing solar output, fine. Take it up with the IPCC, it’s not my call. I was just going with the IPCC’s assertion that solar output didn’t change enough to account for much surface warming, and their 20th century reconstructions that attribute the bulk of projected tropical mid-troposphere warming to rising GHG levels.
Irrespective of how any such warming might be attributed, the point remains that models produce too much warming in the tropical mid-troposphere, right where they posit the strongest response to GHG forcing. This is not a debate over whether they get the surf/trop trend ratio correct, it’s whether they get the trop trend itself right, when the modelers get to observe the historical inputs. Our analysis shows they clearly don’t. People in the modeling community will have to grapple with why that is.
“…the point remains that models produce too much warming in the tropical mid-troposphere, right where they posit the strongest response to GHG forcing.”
I’ve been pondering a comment today. Plan A: Find the most important thing. Drive the models with that, whatever words are correct. That is, where you looked at in this study. Plan B. Drive it with the GMST, where we live and where we take the temperatures for the most part. If plan B is driving the GCM from where it’s not that important, we look at the problem by looking at ourselves instead of the system. Find the heart of the beast. Don’t attack its hat. On the other hand the SSTs are at the surface and important. Only they sit on four kilometers of water and their signals are much more confusing than the atmosphere.
Ross McKitrick, it is good of you to stick around and respond to comments.
Ross McKitrick,
I don’t think modellers need to focus on getting the tropical tropopause trend right. It’s better to focus on the cause, not the effect.
If they get the tropical SST trend right, especially in the “key” Nino 3.4 region, the upper troposphere/tropopause trend will be right as well..
Olof, I don’t aggree. The models are tuned more or less to SST , see https://agupubs.onlinelibrary.wiley.com/doi/full/10.1029/2012MS000154 . You can get this issue right from wrong reasons. If this happens you can cross-check with the tropical upper troposphere. If the model fails in this issue it’s a hint to deficiencies in the model that should be rectified before the application of the model for the projection of the next 100 years or so.
frankclimate,
The models are most certainly not tuned to SST in the Nino 3.4 region, at least not in the satellite era.
I can show this comparison again (shown in my first comment)
https://drive.google.com/open?id=0B_dL1shkWewaTXJJSExKRjBhbVE
The Nino 3.4 SST and tropical tropopause behaviour of models looks “emergent”, diverging from the real world. But if I pick a period when models and obs agree in nino 3.4 SST trend, e g 2000-2017, they agree in tropopause “lift” as well.
(200 mbar altitude and tropopause temperatures show more or less the same thing, but the former was much more convenient to download from KNMI climate explorer)
Re: “Atomski, the reason we didn’t use IUKv2 is that it hasn’t been updated to 2017”
Then you could have included an analysis for the time-period IUKv2 covered, and compared it to other radiosonde-based analyses for that time-period. That’s what was done in a paper much more comprehensive than your’s:
“Internal variability in simulated and observed tropical tropospheric temperature trends”
Re: “You refer to studies about whether amplified warming aloft in the tropics appears on time scales of solar cycles and ENSO periods. But we are looking at 60-year trends.”
The mechanism you’re talking about and trying to critique (the “negative lapse rate feedback response”) appears on both short time-scales and longer time-scales. You tried to claim that it’s relevant applicability was just to GHG-induced surface warming. It clearly isn’t, as shown in the response to shorter-term warming that isn’t caused by CO2.
Re: “Christy et al. included it (and the reanalysis products) in “Examination of space-based bulk atmospheric temperatures used in climate research” IJRS 2018. Using the 1979-2015 interval the tropical midtroposphere trend in IUKv2 is in between the two updated Wien products we use.”
I’m familiar with that paper. It’s nonsense (http://archive.is/FURlA).
Anyway, you’re using the paper in a way that isn’t comparable to what you said in your blogpost. First, 1979-2015 isn’t the same as the 1958 – 2017 time-range you use in your paper.
Second, in that paper, Christy et al. are running the radiosonde-based trends through a model in order to make them analogous to satellite-based analyses. Those satellite-based estimates don’t simply focus on 200hPA to 300hPa like your paper does. Instead, they look at a broad smear of the atmosphere, and Christy modifies the radiosonde-based trends to do the same.
So the more apt comparison for you would be to look at IUK trends for particular pressure levels such as 200hPa or 300hPa. That analysis was done already at 300hPa (with a note that the “results do not differ substantially for other middle-to-upper tropospheric levels”), and it shows that IUKv2 shows the most warming out of any of the radiosonde-based analyses from 1958 – 2014:
Figures 1 and 2 of : “Internal variability in simulated and observed tropical tropospheric temperature trends”
Re: “Irrespective of how any such warming might be attributed, the point remains that models produce too much warming in the tropical mid-troposphere, right where they posit the strongest response to GHG forcing. This is not a debate over whether they get the surf/trop trend ratio correct, it’s whether they get the trop trend itself right, when the modelers get to observe the historical inputs. Our analysis shows they clearly don’t. People in the modeling community will have to grapple with why that is.”
First, you clearly discussed ratios in your blogpost, and said it was a “related issue”. So please don’t act like it’s not part of the debate. You also tried to cast doubt on the “negative lapse rate feedback response”. But that response is not about the total amount of tropospheric warming. It’s instead about the ratio on near-surface (or surface) warming to tropospheric warming, and the ratio of upper tropospheric warming to lower tropospheric warming. After all, the negative lapse rate feedback is about transferring near-surface energy up the troposphere, where that energy can be more easily radiated away.
Second, as was already explained to you, the tropical mid-troposphere warming is not a specific response to GHG forcing. It is due to a latent-heat-release mechanisms that applies irrespective of the cause of warming. Nor is it the strongest response, since near-surface warming in the Arctic is stronger, and (arguably) near-surface warming in desertified areas is stronger.
Third, you still haven’t shown the models got the trend wrong, and the scientific community has already discussed the matter at length. They’ve already shown there are more plausible explanations that imply no flaw in the models. I’ve already cited some of the relevant literature on this for you. See:
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881057
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881126
I find it particularly ironic that your co-author John Christy admits that he can’t discount these explanations:
Page 517: “Satellite bulk tropospheric temperatures as a metric for climate sensitivity”
Re: “If you want to attribute a relatively high fraction of any such trend to increasing solar output, fine. Take it up with the IPCC, it’s not my call. I was just going with the IPCC’s assertion that solar output didn’t change enough to account for much surface warming, and their 20th century reconstructions that attribute the bulk of projected tropical mid-troposphere warming to rising GHG levels.”
The IPCC never makes the claim you did below. So please don’t falsely attribute to them something that came from you:
“Second, climate models predict that, if greenhouse gases are driving climate change, there will be a unique fingerprint in the form of a strong warming trend in the tropical troposphere, the region of the atmosphere up to 15 kilometres in altitude, over the tropics […]. The Intergovernmental Panel on Climate Change (IPCC) states that this will be an early and strong signal of anthropogenic warming. Climate changes due to solar variability or other natural factors will not yield this pattern: only sustained greenhouse warming will do it.”
http://www.financialpost.com/story.html?id=d84e4100-44e4-4b96-940a-c7861a7e19ad&p=1
“Atomski, the reason we didn’t use IUKv2 is that it hasn’t been updated to 2017”
Then you could have included an analysis for the time-period IUKv2 covered
There’s good reason to ignore IUK.
RATPAC uses only the quality controlled stations and excludes stations not meeting criteria.
IUK uses these rejects and homogenizes with them.
But homogenized crap is still crap, just spread out.
Re: “There’s good reason to ignore IUK. RATPAC uses only the quality controlled stations and excludes stations not meeting criteria. IUK uses these rejects and homogenizes with them. But homogenized crap is still crap, just spread out.”
You’re once again making mistakes that stem from you willfully refusing to read the peer-reviewed scientific literature. Let me know when you can actually cite evidence for the claims you make.
RATPAC uses homogenization, as does every other competent radiosonde-based analysis used to examine climate change. So that’s not a relevant difference. And IUK also excludes stations that don’t meet their quality criteria. I’d ask you to read some of the relevant literature on this, but you’ll just refuse to, like usual, and call it “motivated parrotry”. For those who are genuinely curious about these analyses, see:
“Radiosonde Atmospheric Temperature Products for Assessing Climate (RATPAC): A new data set of large-area anomaly time series”
“Atmospheric changes through 2012 as shown by iteratively homogenized radiosonde temperature and wind data (IUKv2)”
“Robust tropospheric warming revealed by iteratively homogenized radiosonde data”
It’s also ironic that you say IUKv2 should be ignored, when not even John Christy and Roy Spencer ignore it; they cite it in their published research (http://archive.is/FURlA). That contrasts with the HadAT2 radiosonde analysis, which they no longer cite (and an older version of which you still cite in the fabricated images you regularly post, as discussed here: https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881100). Interestingly, the HadAT2 team also cites the IUK analysis and recommend that other people use that analysis for research purposes, as do other competent experts who know more about this topic than you:
“To this end we strongly recommend that users consider, in addition to HadAT, the use of one or more of the following products to ensure their research results are robust. Currently, other radiosonde products of climate quality available from other centres (clicking on links takes you to external organisations) for bona fide research purposes are:
Radiosonde Atmospheric Temperature Products for Assessing Climate (RATPAC)
RAdiosonde OBservation COrrection using REanalyses (RAOBCORE) and Radiosonde Innovation Composite Homogenization (RICH)
IUK (Iterative Universal Kriging) Radiosonde Analysis Project
https://www.metoffice.gov.uk/hadobs/hadat/index.html
“Internal variability in simulated and observed tropical tropospheric temperature trends”
IUK: “The resulting dataset includes temperature and wind shear at mandatory reporting levels from 527 radiosonde stations, from 1959-2005. “
RATPAC: “From 1958 through 1995, the bases of the data are on spatial averages of LKS adjusted 87-station temperature data.”
Not only do the stations used by IUK suffer from poor quality and more instrument changes, they are also quite transitory, meaning they include observation bias.
So, IUK includes:
1.) data of poorer quality
2.) data of intermittent nature, and
3.) assumes homogeneous variance by using kriging
Not even the RATPAC stations are complete, which is why I also plot the RATPAC stations which exclude those stations missing 20% or more.
To some extent, the reanalyses probably also suffer from using lower quality raob data. MERRA and ERA-I use RAOBCORE/RICH, which is better, but not as rigorous as RATPAC. It sounds like CFSR was more promiscuous with raob data quality which may account for its variance:
“From 1948 through 1997 a number of archives were combined for the CFSR assimilation, including operational archives from NMC/NCEP, CMWF, JMA, USAF, NAVY, along with other military, academic, and national archives collected at NCAR and NCDC. For the CFSR radiosonde preparation, duplicates were resolved by merging the contents of duplicate soundings instead of picking one sounding from one of the sources and discarding the others, as has been commonly done in reanalysis projects to ate.”
I have challenged you to analyze the available data for yourself. How’s that coming? Here again are my results:
https://i0.wp.com/turbulenteddies.files.wordpress.com/2018/07/hot_spot_1979_2017.png
Re: “Not only do the stations used by IUK suffer from poor quality and more instrument changes, they are also quite transitory, meaning they include observation bias.”
And you’ve still cited no evidence for this claim of your’s.
Re: “I have challenged you to analyze the available data for yourself. How’s that coming? Here again are my results:”
We’ve been over this multiple times. Don’t pretend otherwise. Once again:
Your non-peer-reviewed analyses are unreliable since:
1) you have a history of posting fabricated+misleading graphs/amalyses that you never retract
2) your claims contradict peer-reviewed, published analyses made by people who understand the data-sets you cite better than you do
3) you never make it clear how you generated your analyses
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881100
You’ve also been repeatedly cited evidence showing that the hot spot exists. For instance:
https://judithcurry.com/2018/07/22/the-perils-of-near-tabloid-science/#comment-877599
https://judithcurry.com/2018/07/22/the-perils-of-near-tabloid-science/#comment-877182
https://judithcurry.com/2018/07/22/the-perils-of-near-tabloid-science/#comment-877429
In response, you simply brushed off the evidence (from the peer-reviewed papers I cited to you), by claiming that citing peer-reviewed evidence is just “motivated parrotry”:
https://judithcurry.com/2018/07/22/the-perils-of-near-tabloid-science/#comment-877614
By your logic, a flat Earther can brush off all the peer-reviewed studies that present evidence that Earth is round, by claiming that citing those studies is just “motivated parrotry”. In fact, by your logic, Judith Curry and [every other scientist who cites references in their peer-reviewed papers that provide evidence supporting a point they made] is engaged in “motivated parrotry”. It’s as if you have no clue how evidence is cited in science.
In space no one can hear you scream.
https://watertechbyrie.files.wordpress.com/2014/06/harries-2001.png
https://www.atmos.washington.edu/~dennis/321/Harries_Spectrum_2001.pdf
On the planet the signals are dynamically mixed over space and time as the Earth system evolves.
https://www.ospo.noaa.gov/data/sst/anomaly/2008/anomnight.1.3.2008.gif
Pingback: A Test of the Tropical 200-300 mb Warming Rate in Climate Models | SHOAH
global warming what? climate change what? climate has stopped warming for 20 years. already as of 2005 I have predicted it in my original thesis on solar activity and climate. In fact I have developed the only climate model that projects dropping temperatures. A link to my papers https://www.researchgate.net/profile/Dimitris_Poulos
Looking at the measured tropical temps vs models I find both consistent with the moist adiabatic. Trend at 250mb is twice that at 850mb. Only problem with models seem to be the usual exaggeration of warming. https://www.tandfonline.com/doi/full/10.1080/01431161.2018.1444293
I’ll plow this ground and beat this dead horse yet some more. Maybe somebody will step up and ‘splain scientifically how/why I’ve got it wrong – or not.
Radiative Green House Effect theory: (Do I understand RGHE theory correctly?)
1) 288 K – 255 K = 33 C warmer with atmosphere – rubbish. (simple observation & Nikolov & Kramm)
But how, exactly is that supposed to work?
2) There is a 333 W/m^2 0.04% GHG up/down/”back” energy loop that traps/re-emits per QED simultaneously warming BOTH the atmosphere and the surface. Good trick. Too bad it’s not real. – thermodynamic nonsense.
And where does this magical GHG energy loop first get that energy?
3) From the 16 C/289 K/396 W/m^2 S-B 1.0 ε BB radiation upwelling from the surface. – which due to the non-radiative heat transfer participation of the atmospheric molecules is simply not possible. (TFK_bams09)
No BB upwelling & no GHG energy loop & no 33 C warmer means no RGHE theory & no CO2 warming & no man caused climate change.
Got science? Bring it!!
Nick’s problem is that photons interact with more CO2 molecules and bounce about the system a bit more.
https://watertechbyrie.files.wordpress.com/2014/06/gw-photons-animated.gif
Increased ‘photon scattering’ can theoretically can be seen in narrow aperture IR snapshots taken at different times.
https://watertechbyrie.files.wordpress.com/2014/06/harries-2001.png
You are hung up explaining the QED mechanism behind the up/down/”back” GHG energy “warming” loop which, without the non-existent BB surface upwelling LWIR, also does not even exist.
Explain how the surface radiates as an ideal BB.
Without that, everything behind the illusion/delusion green velvet curtain is exposed & collapses.
Photons at the relevant frequencies are emitted by the sun absorbed by the Earth and remitted as IR. Photons emitted by the Earth interact with CO2 with collisions and absorption changing the vector of IR photons in the atmosphere. I explain it thus because that’s how it happens.
It is a simple system in principle based on the actions of fundamental particles. There are things that happen in addition – but where there are fundamental particles with these properties this happens.
Repeating endlessly nonsense about black bodies or unexplained nonsense about a warm surface not emitting electromagnetic radiation or of photons not bouncing around the atmosphere is the complete sky dragon package. Complete nonsense that only nickunreality can see.
“Hemispherically averaged linear trend of tropospheric temperature between 1979 and 2005 divided by the global mean of the skin temperature”
Odd calculation to make – given the well known difference in MST trend between hemispheres.
Just sayin’…
“The rate of observed warming since 1979 for the tropical atmospheric TMT layer, which we calculate also as +0.10 ± 0.03°C decade−1, is significantly less than the average of that generated by the IPCC AR5 climate model simulations. Because the model trends are on average highly significantly more positive and with a pattern in which their warmest feature appears in the latent-heat release region of the atmosphere, we would hypothesize that a misrepresentation of the basic model physics of the tropical hydrologic cycle (i.e. water vapour, precipitation physics and cloud feedbacks) is a likely candidate.” https://www.tandfonline.com/doi/full/10.1080/01431161.2018.1444293
It is far more fundamental than just getting the geophysics wrong.
“Whether or not the irreducible imprecision proves to be a substantial fraction of present AOS discrepancies with nature, it seems imperative to determine what the magnitude of this type of imprecision is.” http://www.pnas.org/content/104/21/8709
It doesn’t have to be a problem with “basic model physics of the tropical hydrologic cycle”. It has the character of a dynamic atmosphere-ocean coupling issue with the models being too El-Nino-like compared to nature in this period (as Olof R said). Other studies show the bias to be mostly in the Pacific which is consistent.
Despite being dynamically complex – they don’t do dynamic well. So a fundamental lack of knowledge that bedevils many scientific and engineering goals. We are in Fermi terrotory. I say 50% of 20th century warming – to be lost abruptly this century – coupled with Pacific shifts. At this stage we may as well toss a coin.
It is very difficult for coupled models to get ENSO right or even at all in some cases. Too many moving parts have to fit together. This is what Jim McWilliams was saying.
He means Professor McWillisms.
https://www.ioes.ucla.edu/person/james-mcwilliams/
And no it wasn’t.
“Sensitive dependence and structural instability are humbling twin properties for chaotic dynamical systems, indicating limits about which kinds of questions are theoretically answerable. They echo other famous limitations on scientist’s expectations, namely the undecidability of some propositions within axiomatic mathematical systems (Gödel’s theorem) and the uncomputability of some algorithms due to excessive size of the calculation.”
It was much more fundamental.
It was confined to chaotic dynamics, not the physics. There is a difference.
Deterministic chaos is not the third great idea in 20th century physics? Many people will be surprised.
“Atmospheric and oceanic computational simulation models often successfully depict chaotic space–time patterns, flow phenomena, dynamical balances, and equilibrium distributions that mimic nature. This success is accomplished through necessary but nonunique choices for discrete algorithms, parameterizations, and coupled contributing processes that introduce structural instability into the model. Therefore, we should expect a degree of irreducible imprecision in quantitative correspondences with nature, even with plausibly formulated models and careful calibration (tuning) to several empirical measures. Where precision is an issue (e.g., in a climate forecast), only simulation ensembles made across systematically designed model families allow an estimate of the level of relevant irreducible imprecision.” http://www.pnas.org/content/104/21/8709
It was about irreducible imprecision in chaotic models. One of the many things #Jiminy can’t contemplate.
Again, not about the “basic model physics of the tropical hydrologic cycle”. Do you even see the difference between physics and dynamics? McWilliams has more of a Lorenz type argument that would even be true of a perfect model.
Again it is about a profound agnotology on #Jiminy’s part. The geophysics are unpredictable because they are complex and dynamic. Models have a whole extra dimension of imprecision.
Even if the model is perfect there is dynamical imprecision. That’s chaos theory, Lorenz and all that. It’s a separate point from the physics in models.
a) There is not a chance that the model is ‘perfect’.
b) There is not a chance that any model can produce a unique deterministic solution.
Not sure what #Jiminy is on about – but it is more nonsense.
Certainly not what I was saying but yes to your two points anyway.
What was he saying and why did think it meant something rational.
It doesn’t have to be a problem with “basic model physics of the tropical hydrologic cycle”. It has the character of a dynamic atmosphere-ocean coupling issue with the models being too El-Nino-like compared to nature in this period (as Olof R said). Other studies show the bias to be mostly in the Pacific which is consistent.
Now he repeats himself and quotes a blogger called Olaf. Jiminy makes things up on the spot. Does it make any sense at all? Not usually.
Just checking. Your responses make it look like you haven’t read the comments above them at all.
#Jiminy argues that the models are wrong because of chaos – not because of knowledge gaps of complex and dynamic systems. .
I think that was you when you quoted McWilliams. Imprecision does not mean lack of knowledge. He says the knowledge is there for the dynamics, but it can’t be fully accurately represented in models of chaotic systems if you read it. It’s like Lorenz.
The physics of tropical hydrology include ENSO btw.
Your definition of physics seems to encompass atmosphere-ocean coupled dynamics. OK, then, but I do not. Redefine terms as you want. The problem is that models are more El-Nino-like over this period for whatever reason.
Geophysics is a fairly simple notion – it is the physics of everything. And the problem is Jiminy’s pure inventions. This time El Nino in models because Olaf said so.
I happen to agree with Olof because there are other studies that also show this IPCC CMIP5 warming tendency in the tropical troposphere together with the Pacific SST pattern that goes with it. This post’s study did not show any spatial patterns, but it is likely the same since it is the same models.
http://www.nbi.ku.dk/english/research/Geophysics/
Within a model the physics and dynamics parts are very well defined and separate things. Dynamics only governs how things move, and physics governs how they are changing apart from just motion.
A case study in the struggle to get beyond the incorrect idea that only forcing leads to climate change. Models have temporal chaos – climate spatio-temporal chaos. There are fundamental differences. The CMIP ensemble purports to have 102 unique model solutions. An impossibility understood as such for nearly 60 years. Every model has an evolving uncertainty that lead to a broad range of feasible solutions. Jiminy raised the name of ‘Jim’ McWilliams in an overly familiar way and attributed ‘irreducible imprecision’ to ENSO. Which is why I quoted. The problem is indeed Lorenzian – but we have come some way since the 1960’s.
http://www.pnas.org/content/pnas/104/21/8709/F1.medium.gif
‘Generic behaviors for chaotic dynamical systems with dependent variables ξ(t) and η(t). (Left) Sensitive dependence. Small changes in initial or boundary conditions imply limited predictability with (Lyapunov) exponential growth in phase differences. (Right) Structural instability. Small changes in model formulation alter the long-time probability distribution function (PDF) (i.e., the attractor).’
Lorenz’s problem was that he truncated results to 3 decimal places. It should not by all that was known have made a difference. The rest is history. The problem for modelers is that initial conditions are not known to any great precision and small differences leads to solution divergence over time. Prediction is quite literally impossible.
Earth’s climate is a fluid flow problem. Fluid flows result in quasi standing waves – ENSO is just one – that shift in time and space due to internal reorganizations. As I say the Pacific is due to shift again within the decade – if not now. As I said – prediction is impossible – you may as well toss a coin.
Jiminy’s problem is that he hand waves about ‘studies’ but rarely cites anything at all – when he does – it doesn’t say what he claims it does. The claim that models underestimate the lapse rate and therefore sensitivity is just one example of his Procrustean proclivity for fitting science to narrative.
OK, thanks.
Agnotology
The perfect word for describing the approach to climate science by the MSM and warmists. Now I can save keystrokes when discussing their faulty thinking.
Of course there is always misology, which for some may be an even more accurate description.
However explained, there is a very pervasive problem preventing a more thorough understanding of climate science.
As Wikipedia says, the definition of agnotology is what the tobacco industry were doing. Also known as manufactured doubt or cultivated ignorance. Basically anti-science and post-truth.
Re: “Because the model trends are on average highly significantly more positive and with a pattern in which their warmest feature appears in the latent-heat release region of the atmosphere, we would hypothesize that a misrepresentation of the basic model physics of the tropical hydrologic cycle (i.e. water vapour, precipitation physics and cloud feedbacks) is a likely candidate.”
McKitrick and Christy wrote this in the paper McKitrick cited in his blogpost:
“Our interpretation of the results is that the major hypothesis in contemporary climate models, namely, the theoretically based negative lapse rate feedback response to increasing greenhouse gases in the tropical troposphere, is incorrect. Further diagnosis of the nature of the inaccuracy is beyond this analysis: For discussion see, for example, Spencer and Braswell (2014), Lewis and Curry (2014), and Christy and McNider (2017).”
https://agupubs.onlinelibrary.wiley.com/doi/full/10.1029/2018EA000401
That “Christy and McNider (2017)” paper is nonsense (http://archive.is/Hxv9W http://archive.is/1EOrt), as is the Christy et al. 2018 paper you cited (http://archive.is/Do2BL). But let’s set aside that issue for now. Another issue here is that Christy and McNider 2017 admits that it cannot totally discount alternative explanations for differences between model-based projections vs. observational analyses of tropospheric warming:
“As noted, we cannot totally discount that natural variability or errors in forcing might also account for the discrepancy between modeled and observed [tropospheric transient climate response]. However, given the facts that the processes controlling the uptake of energy by oceans and the transfer of heat in the tropical atmosphere are largely parameterized, it is not scientifically justified to dismiss model error, possibly substantial, as one source of the discrepancy.”
https://link.springer.com/article/10.1007/s13143-017-0070-z
These alternative explanations for the difference include:
1) internal variability
2) errors in the inputted forcings
3) residual artifacts/heterogeneities in the observational analyses
None of these alternative explanations imply a flaw in the climate models. For example, as Santer et al. noted:
“Volcanic contribution to decadal changes in tropospheric temperature
[…]
Even a hypothetical ‘perfect’ climate model, with perfect representation of all the important physics operating in the real-world climate system, will fail to capture the observed evolution of climate change if key anthropogenic and natural forcings are neglected or inaccurately represented.”
I’ve previously cited evidence for these alternative explanations, along with citing evidence against Christy and McKitrick’s “error in model physics” explanation being the primary explanation for the difference:
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881057
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881126
Now you’re citing Christy et al. offering some hypotheses in support of their “error in model physics” explanation. As you quoted, Christy et al. “hypothesize that a misrepresentation of the basic model physics of the tropical hydrologic cycle (i.e. water vapour, precipitation physics and cloud feedbacks) is a likely candidate”. Well, that doesn’t mean much when Christy can’t adequately discount the alternative explanations, and when there’s evidence against Christy’s explanation.
It’d be interesting to see them cite evidence in support of their claim, especially in light of the evidence on positive feedback from tropospheric water vapor (with increasing tropospheric water vapor), along with models doing fairly well in representing precipitation, the water cycle, and positive feedback from clouds:
Water vapor:
“Upper-tropospheric moistening in response to anthropogenic warming”
“Construction and uncertainty estimation of a satellite‐derived total precipitable water data record over the world’s oceans”
“The radiative signature of upper tropospheric moistening”
“Three decades of intersatellite-calibrated High-Resolution Infrared Radiation Sounder upper tropospheric water vapor”
“Trends in tropospheric humidity from reanalysis systems”
“Physical mechanisms of tropical climate feedbacks investigated using temperature and moisture trends”
“Climate variability and relationships between top-of-atmosphere radiation and temperatures on Earth”
Water cycle and precipitation:
“Global water cycle amplifying at less than the Clausius-Clapeyron rate”
“Physically consistent responses of the global atmospheric hydrological cycle in models and observations”
“Observed heavy precipitation increase confirms theory and early models”
“Observed and simulated precipitation responses in wet and dry regions 1850–2100”
“Observed drought indices show increasing divergence across Europe”
“Human contribution to the increasing summer precipitation in Central Asia from 1961 to 2013”
Clouds:
“Evidence for climate change in the satellite cloud record”
“Cloud feedback mechanisms and their representation in global climate models”
“A net decrease in the Earth’s cloud, aerosol, and surface 340 nm reflectivity during the past 33 yr (1979–2011)”
“New observational evidence for a positive cloud feedback that amplifies the Atlantic Multidecadal Oscillation”
“Impact of dataset choice on calculations of the short-term cloud feedback”
“Long-term cloud change imprinted in seasonal cloud variation: More evidence of high climate sensitivity”
“A determination of the cloud feedback from climate variations over the past decade”
“Observations of climate feedbacks over 2000–10 and comparisons to climate models”
“The accurate representation of this continuum of variability in numerical modelsis, consequently, a challenging but essential goal. Fundamental barriers to advancing weather and climate prediction on time
scales from days to years, as well as longstanding
systematic errors in weather and climate models, are partly attributable to our limited understanding of and capability for simulating the complex, multiscale
interactions intrinsic to atmospheric, oceanic,
and cryospheric fluid motions.” http://www.cgd.ucar.edu/staff/jhurrell/docs/hurrell.modeling_approach.bams10.pdf
Atomski’s odd filibustering attempts to prove an impossible thesis? They get cloud and rainfall right? Or the tropical hot spot? Utter incredible nonsense.
Atom,
The numerous references you give in support of your stance are typically assessing model uncertainty that, in the ways of harder science, are evolved, debated, reworked until the hypotheses pass minimal standards of understanding.
Many of the disturbing outcomes we have, are products of using modelled results before the models are ready.
Come back when the models are validated, replicated, pass the usual acceptance standards. Meanwhile, attach the caveat Warning, not ready for use in policy formulation. Geoff
Re: “The numerous references you give in support of your stance are typically assessing model uncertainty”
Nope. For instance, many of the papers are comparing model projections to observational analyses. I know this because I’ve read each of the papers. Next time, actually read papers before commenting on them, instead of making false claims on material you have not read.
Re: “Come back when the models are validated, replicated, pass the usual acceptance standards”
That’s ironic coming from you, since your above comments show that you didn’t even read some of the listed papers that validated models by comparing them to observational analyses. You’re really going to have no clue about this topic if you don’t put some effort into reading the peer-reviewed literature. Try reading it.
Pingback: Weekly Climate and Energy News Roundup #329 |
Pingback: Computer-Klimasimulationen sind gerade kollabiert – EIKE – Europäisches Institut für Klima & Energie
Re: “But the IPCC states that only greenhouse forcing would explain a strong historical warming trend in the target region. The presence of such a trend would thus have only one explanation; likewise, its absence would conflict with only one major hypothesis of the model, namely the set of parameterizations that yield amplified GHG-induced warming.”
Since you make the same point in the paper you co-authored with Christy, someone should go tell Dessler that Christy is still making the same false insinuations that were corrected years ago:
https://twitter.com/AndrewDessler/status/437999679494582272
Atomsk, of course EVERY warming would introduce an amplification in the 200…300 mb hight in the tropics. And we know from many sources ( i.e. models) that the reason for the present warming is the GHG forcing. If this warming would be lower than models expect we would see it first in the upper tropical troposphere. Actually we see this indeed. Where is the problem??
Re: “Atomsk, of course EVERY warming would introduce an amplification in the 200…300 mb hight in the tropics.”
I know that. Yet folks like John Christy, Christopher Monckton, David Evans, Anthony Watts, etc. falsely claimed otherwise for years. They acted as if the amplification was only something one would get from GHG-induced warming. That’s why folks like Dessler, Santer, etc. had to keep correcting that nonsense. For instance:
“In the tropics, moist thermodynamic processes amplify surface warming […]. Such tropical amplification occurs for any surface warming; it is not a unique signature of greenhouse gas (GHG)-induced warming, as has been incorrectly claimed (Christy 2015) [page 383].”
https://journals.ametsoc.org/doi/pdf/10.1175/JCLI-D-16-0333.1
In fact, Donald Rapp, one of the people who regularly contributes blogposts to this website, created that false impression in his discussion of tropospheric temperatures. He had to be corrected by Fred Moolten (probably one of the people I most admire on this website):
https://judithcurry.com/2011/10/29/tropospheric-and-surface-temperatures/#comment-129673
Of course, a whole bunch of people in the comments on here then falsely claimed the amplification was a GHG-specific, anthropogenic fingerprint, based on their distortion of what the IPCC said.
Re: “And we know from many sources ( i.e. models) that the reason for the present warming is the GHG forcing.”
I went over this already:
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881068
To repeat myself:
Most of the industrial-era, multi-decadal warming (especially since the 1950s) is due to anthropogenic increases in greenhouse gas levels. However, plenty of factors also contribute to shorter-term warming trends, including ENSO and the phase of the solar cycle in which TSI increases. Tropospheric amplification (the “hot spot”) with the negative lapse rate feedback, applies both to the longer-term warming and shorter-term warming. So you cannot do what Christy+McKitrick attempt to: claim that a lack of a hot spot is just an objection to the climate response to GHG-induced forcing.
Re: “If this warming would be lower than models expect we would see it first in the upper tropical troposphere. Actually we see this indeed. Where is the problem??”
At least two problems.
First, as I explained to you on other occasions, this comparison does not reveal a substantial flaw in the models; it does not show that “this warming [is] lower than models expect we would see”. Most of the difference is not due to model error, as noted by the RSS link you selectively quoted:
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881126
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881057
There are more plausible, evidence-based explanations for the difference, where those explanations imply no flaw in the models. These explanations include:
1) Errors in the inputted forcings
2) Residual artifacts/heterogeneities in the observational record
3) Internal variability
You falsely claimed the last two explanations wouldn’t apply to the McKitrick’s comparisons with radiosondes:
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881146
Of course, you’re wrong, as shown by the following paper I previously cited:
“Internal variability in simulated and observed tropical tropospheric temperature trends”
Second, you made the same mistake as McKitrick made below, a mistake which I already addressed:
“Irrespective of how any such warming might be attributed, the point remains that models produce too much warming in the tropical mid-troposphere, right where they posit the strongest response to GHG forcing”
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881157
The strongest response is not in the tropical mid-troposphere. The strongest warming response is in Arctic near-surface:
https://wol-prod-cdn.literatumonline.com/cms/attachment/31dfb7af-2b20-4dd5-af32-3e24990af7b2/wea3174-fig-0002-m.png
[Figure 2 from: “Recent United Kingdom and global temperature variations”]
Heck, the near-surface response in desertified areas is (arguably) stronger that the tropical mid-troposphere response:
https://journals.ametsoc.org/na101/home/literatum/publisher/ams/journals/content/clim/2015/15200442-28.16/jcli-d-14-00230.1/20150804/images/large/jcli-d-14-00230.1-f7.jpeg
[from: “Detection and analysis of an amplified warming of the Sahara Desert”]
{Entire tropics (blue line; from 30°N to 30°S), tropical land (green line; from 30°N to 30°S), and the Sahara desert (red line). The horizontal axis represents the warming trend in K per 34 years. The vertical axis represents altitude, with decreasing atmospheric pressure as altitude increases}
Atomsk, nice to read that we agree in some fundamental issues. However, you once again cite the wording which is dediated to the TLT data and NOT to the tropic T’s at altitudes in which the air preasures are 200…300mb. AND: you mix these T with T2m ( your cited figure from GISS) to show that the arctic warms faster than anything. This is “argument hopping” IMO. Please stay focused on the field. And: IMO we should agree that we disagree, no need to introduce the same again and again. If the tropical upper troposohphere ampifies the warming on the ground and the result is a much smaller warming ( obs. from baloons and sats) there than models estimate…there is a mismatch that should be cleared. Not more and not less I wanted to say.
Re: “However, you once again cite the wording which is dediated to the TLT data and NOT to the tropic T’s at altitudes in which the air preasures are 200…300mb.”
The points apply to TTT and TMT as well, which include 200mb – 300mb. You’ve been corrected on this already:
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881832
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881848
I even showed you an image of a trends at 300mb in the post you’re responding to. But you conveniently ignored that, so at this point there’s no reason to think you’re actually going to engage the evidence.
Re: “AND: you mix these T with T2m ( your cited figure from GISS) to show that the arctic warms faster than anything. This is “argument hopping” IMO.”
It is not “argument hopping”, since it’s clearly pertinent to what you said. You, like McKitrick, acted as if the strongest response (the response that would be first seen) is in the upper troposphere:
“If this warming would be lower than models expect we would see it first in the upper tropical troposphere.”
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881823
I showed that claim of your’s is false, by showing the response is stronger in other places, like the Arctic and deserts
Re: “And: IMO we should agree that we disagree, no need to introduce the same again and again. If the tropical upper troposohphere ampifies the warming on the ground and the result is a much smaller warming ( obs. from baloons and sats) there than models estimate…there is a mismatch that should be cleared. Not more and not less I wanted to say.”
And I’m saying it’s not even clear that there’s a mismatch, once the model estimates are based on accurate forcing estimates, with homogeneous observational analyses, and internal variability taken into account.
One of the many debunkings is here.
https://itsnotnova.wordpress.com/2013/02/11/hot-spot-2-tropospheric-warming-continues/
The point of this second experiment is to demonstrate that a surface with multiple outgoing heat transfer pathways cannot radiate as a BB. Just as reflected, transmitted, absorbed incoming radiation must equal 1.0 the outgoing radiative and non-radiative heat transfer processes must equal 1.0. Radiation does not function independently from the non-radiative processes.
The immersion heater is feeding 1,180 W of power into the insulated pot of water which is boiling at an equilibrium temperature of 200 °F. (6,300 feet) The only significant pathway for energy out of this system is through the water’s surface.
Any surface at 200 °F radiates at 1,021 W/m^2. This is 2.38% of the 42,800 W/m^2 power input to the system. That means 97.6% of the power input is carried away by non-radiative heat transfer processes, i.e. conduction, convection and evaporation.
Likewise, the significant non-radiative heat transfer processes of the atmospheric molecules render the 396 W/m^2 LWIR radiation upwelling from the surface impossible.
No 396 W/m^2 upwelling BB LWIR means there is
No energy to power the 333 W/m^2 GHG out-of-nowhere perpetual energy loop,
No energy for the CO2/GHGs to “trap” or absorb and re-radiate “warming” the atmosphere/surface and
No man-caused climate change.
This second experiment validates the findings of the modest experiment.
Modest experiment:
https://www.linkedin.com/feed/update/urn:li:activity:6394226874976919552
Annotated TFK_bams09
https://www.linkedin.com/feed/update/urn:li:activity:6447825132869218304
Re: “There are likely remaining heterogeneities in the radiosonde analyses, as discussed in:
“Internal variability in simulated and observed tropical tropospheric temperature trends””
To further illustrate this point, here is a radiosonde-based graph from Christy+McKitrick’s paper:
https://i.imgur.com/7u4jG9Q.jpg
[figure 3 of: “A test of the tropical 200‐ to 300‐hPa warming rate in climate models”]
Basically: the results from the IUKv2 radiosonde-based analyses, a satellite-based GPS-RO analysis, various satellite-based microwave emissions analyses, and various re-analyses, support the claim that Christy+McKitrick’s graph under-estimates tropical upper tropospheric warming due to residual remaining heterogeneities in the radiosonde-based analyses Christy+McKitrick chose.
To elaborate on this further:
I already pointed out how Christy+McKitrick’s above graph leaves out the greater warming trend from IUKv2 radiosonde-based analysis. That’s covered in:
“Internal variability in simulated and observed tropical tropospheric temperature trends”
Moreover, a satellite-based GPS-RO analysis appears to show greater post-2001 tropical upper tropospheric warming than does Christy+McKitrick’s graph:
https://pbs.twimg.com/media/Dozx5EmXoAAXP6a.jpg
[figure 4 of: “Postmillennium changes in stratospheric temperature consistently resolved by GPS radio occultation and AMSU observations”]
It also looks like various satellite-based analyses that use microwave emissions (UW, NOAA/STAR, RSS, UMD, and Weng+Zou; not UAH), show more post-1979 tropical upper tropospheric warming than does Christy+McKitrick’s graph above. The papers for these satellite-based analyses are cited here:
https://judithcurry.com/2018/09/17/a-test-of-the-tropical-200-300-mb-warming-rate-in-climate-models/#comment-881073
Furthermore, various re-analyses (MERRA-2, ERA-I, and CFSR; not JRA-55 and NCEP-2) also show more post-1979 tropical upper tropospheric warming than does Christy+McKitrick’s graph above. The evidence for those re-analyses is cited here:
https://judithcurry.com/2018/09/28/week-in-review-science-edition-87/#comment-881563
By the way: if one wants to compare ERA-I’s analysis to satellite-based TMT analyses (as Christy does in DOI: 10.1080/01431161.2018.1444293; Christy’s paper conflicts with DOI: 10.1002/joc.4909), then one should remember that ERA-I under-estimates mid-to-lower tropospheric warming, as acknowledged by the ERA-I team. Thus when one runs ERA-I through a model in order to generate an ERA-I-based estimate of TMT, that TMT estimate will under-estimate the actual rate of warming:
“ERA‐Interim exhibits a weaker overall warming trend over the period at 700 and 500 hPa; reasons why it is thought to underestimate trends in the lower and middle troposphere are discussed by Simmons et al. (2014).”
https://rmets.onlinelibrary.wiley.com/doi/full/10.1002/qj.2949
“Simmons et al. [2014] demonstrate the excellent quality of ERA‐I tropospheric temperatures, except that a change in source of SST analysis led to a shift to cooler SSTs by about 0.1 K in mid‐2001, and thus, lower tropospheric warming is somewhat underestimated.”
https://agupubs.onlinelibrary.wiley.com/doi/full/10.1002/2014JD022887
Simmons et al. 2014 is this paper:
“Estimating low-frequency variability and trends in atmospheric temperature using ERA-Interim”