
by Fritz Vahrenholt and Rolf Dubal
The warming of the last 20 years has its essential cause in the change of the clouds.
We have investigated the Earth’s radiation balance over the last 20 years in a peer – reviewed publication in ” Atmosphere”. The net radiation flux, i.e. the difference between solar irradiation and long- and short-wave radiation, determines the change in the energy content of the climate system. If it is positive, the Earth is heating up; if it is negative, it means cooling. The NASA-operated satellite-based CERES project has been providing such radiation data for two decades now, as well as data on the development of cloud cover in temporal and spatial resolution. These data are determined both in relation to an altitude of approx. 20 km (TOA = “Top of Atmosphere”), and also in relation to the Earth’s surface.
Our new publication “Radiative Energy flux variation from 2001 – 2020″ has brought to light a surprising result for climate science: the warming of the Earth in the last 20 years is mainly due to a higher permeability of clouds for short-wave solar radiation. Short-wave radiation has decreased sharply over this period (see figure), equally in the northern and southern hemispheres (NH and SH). With solar radiation remaining nearly constant, this means that more shortwave radiation has reached the Earth’s surface, contributing to warming. The long-wave back radiation (the so-called greenhouse effect) contributed only to a lesser extent to the warming. It was even largely compensated for by the likewise increasing permeability of the clouds to long-wave radiation emanating from the Earth. The authors come to this clear conclusion after evaluating the CERES radiation data.

NASA researcher Norman Loeb and collaborators [link], as well as the Finnish researcher Antero Ollila [link], had already recently pointed out that the short-wave solar radiation increased from 2005 to 2019 due to the decrease in low clouds. Our latest publication has examined TOA and ground-level radiation fluxes for the entire period and related them to changes in cloud cover. The net energy influx was positive throughout the period, increasing from 0.6 W/m² to 0.75 W/m² from 2001 to 2020. The 20-year average was 0.8 W/m². The bridge chart shows the drivers of this change and these are clearly in the area of shortwave radiation in the cloudy areas, which make up about 2/3 of the Earth’s surface (SW Cloudy Area, +1.27 W/m²).
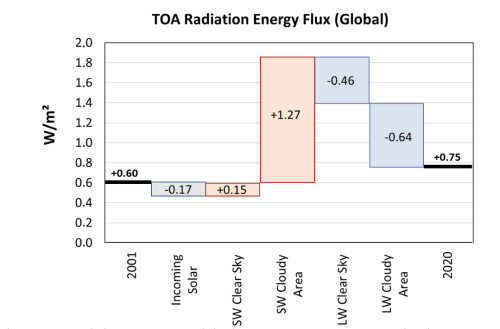
This contrasts with the assumption made by the IPCC in its most recent report that the warming caused by the increase in long-wave back radiation was due solely to the anthropogenic greenhouse effect. The IPCC attributes 100% of the warming to this effect and justifies this with model calculations. However, the analysis of the measured data by Dübal and Vahrenholt shows that the warming due to the decrease of 1.4 W/m² short-wave radiation and the – 1.1 W/m² increase in long-wave radiation is mainly attributable to the cloud effect.
We also considered the effect of this radiative excess on the heat content of the climate system for a longer period since 1750, where “enthalpy” means the sum of heat, work and the latent heat, i.e. heat of evaporation of water, heat of melting of ice, energetic change of the biosphere (plant growth), etc. Since about 90% of this enthalpy remains as heat in the oceans, conclusions about enthalpy development can also be drawn by looking at long-term ocean heat content (OHC). Good agreement was found between these two independent data sets for the period 2001-2020, and existing OHC data were evaluated for earlier, longer periods to provide an overall picture. This shows that warming since 1750 has not been continuous, but has occurred in heating episodes, designated A, B and C, during each of which a high net radiative flux (0.7 to 0.8 W/m²) acted for 20-30 years, interspersed with milder phases. The onset of these heating episodes coincided with the change of sign of another known natural climate factor, the AMO (Atlantic Multidecadal Oscillation). The crucial question of whether the present heating phase C will soon come to an end as in cases A and B, or whether it will continue, can only be decided on the basis of longer observations and must therefore remain open.
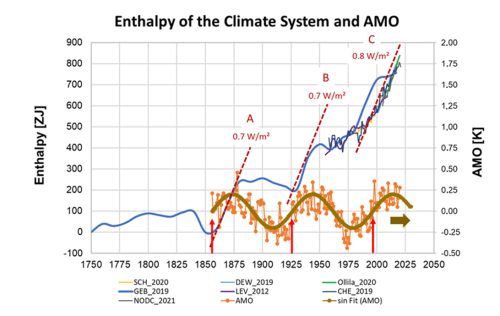
In order to investigate the beginning of phase C around the year 2000, further data sets were used, including the cloudiness measurements of EUMETSAT, a European satellite project. Here it can be seen that the onset of phase C is accompanied by a decrease in cloudiness, coinciding with the above-mentioned change in sign of the AMO. From the radiation measurements it can be deduced that 2% less cloud cover means about 0.5 W/m² more net radiation flux, which could explain most of the 0.8 W/m² mentioned above.
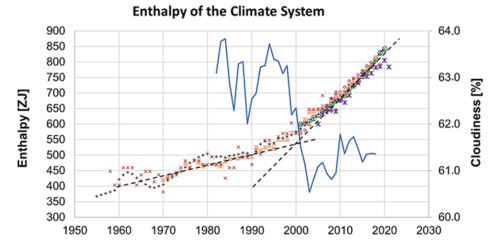
This result is also corroborated by the analysis of the near-surface radiation balance. Here an increase of the greenhouse effect is found, which correlates well with the increase of the greenhouse gases water vapour and CO2, but only for the cloudless areas (“clear sky”). This correlation, however, does not apply to the cloud-covered areas, which make up about 2/3 of the earth.
We could prove the increased greenhouse effect of the sum of all greenhouse gases (water vapour, CO2 etc.) under “Clear Sky” conditions with 1.2 W/m² increase in the last 20 years. However, this increase is overcompensated on an area-weighted basis by the increasing radiation of long-wave radiation in the cloudy zones (“Cloudy Areas”) amounting to -1.48 W/m².
The time span of 20 years is still too short to be able to decide conclusively whether the current heating phase is a temporary or permanent development. In the former case, climate forecasts will have to be fundamentally revised. The physical mechanism that led to the cloud thinning is discussed differently in the literature. Vahrenholt: “The cloud changes can be caused by a decrease in aerosols, by atmospheric warming due to natural causes (e.g. the AMO or the PDO), by anthropogenic warming due to CO2, or by a combination of these individual factors. However, one thing can already be stated: the warming of the last 20 years has been caused more by change in the clouds than by the classical greenhouse effect.

The result is caused by cloud effect feedback from a cooler eastern Pacific during the hiatus and warmer sea surface temperatures since.
e.g. https://www.mdpi.com/2225-1154/6/3/62
It simply means that there is natural variability in the global energy dynamic that is combined with slow but inexorable anthropogenic climate forcing.
The rate of increase of absorbed solar is 6.7W/m2 per century.
The rate of increase of RF from GHGs is 3.5W/m2 per century.
This doesn’t obviate GHGs.
But to the extent that CERES is correct, only a third of the last two decades warming is from greenhouse gasses.
Interestingly, ERA5 reanalysis does not bear out CERES:
https://climateobs.substack.com/p/earth-radiance-trends
Also, the trend of lunar earthshine is about 2.5W/m2 per century.
That’s about 40% solar and 60% CO2 compared with
CERES about 65% solar and 35% CO2.
Two independent measures and reanalysis agree that the sensitivity to CO2 is less than modeled because some to most of the warming of the last two decades is from solar, not CO2.
Albedo changes and hence reflected shortwave varies on decadal to millennial scales – given the sea surface temperature/marine boundary layer cloud mechanism. Anthropogenic forcing rises slowly but inexorably. Apples and oranges.
“In fact, as NASA’s Dr Gavin Schmidt has pointed out, the IPCC’s implied best guess was that humans were responsible for around 110% of observed warming (ranging from 72% to 146%), with natural factors in isolation leading to a slight cooling over the past 50 years.”
https://www.carbonbrief.org/analysis-why-scientists-think-100-of-global-warming-is-due-to-humans
For the last 20 years, CERES and lunar earthshine indicate 35% to 60% CO2, and not 72% to 146%.
“ The long-wave back radiation (the so-called greenhouse effect) contributed only to a lesser extent to the warming.”
Will this get much play in the MSM? Fat chance.
Second question. Will this finding be included in IPCC7?
Let me guess. About as much as studies on geothermal activity in Antarctica.
“Let me guess. About as much as studies on geothermal activity in Antarctica.”
Bingo! Why nobody ever talks about that?
Total absorbed solar radiation is 120,000 TW
Total geothermal energy generated 50 TW
Total energy from human production 20 TW
Back radiation from CO2 9000TW
The reason they don’t mention it is that it’s too small.
BTW, the above are the ONLY sources of energy that can warm the planet besides back radiation from other greenhouse gases. Current movement and all that other nonsense has NO impact on the earth’s temperature and NO impact on climate. Moving energy from one point to another on the planet has NO impact on the planet’s temperature.
Currents don’t matter to two dimensional thinkers.
Currents don’t matter period. Neither do lava flows, hurricanes, tornadoes, or hot flashes.
JJ
Why don’t you do some research. If you did you would begin to understand the issue. It has nothing to do with warming the planet. But go ahead, join Appell and revel in those 5th grade equations.
You mean the “5th grade equations” you don’t understand?
JJ don’t do complicated.
‘The top-of-atmosphere (TOA) Earth radiation budget (ERB) is determined from the difference between how much energy is absorbed and emitted by the planet. Climate forcing results in an imbalance in the TOA radiation budget that has direct implications for global climate, but the large natural variability in the Earth’s radiation budget due to fluctuations in atmospheric and ocean dynamics complicates this picture.’ https://link.springer.com/article/10.1007/s10712-012-9175-1
Once again, RIE shows his ignorance of the fundamentals. How many times is it now? It’s so many, I forget.
Fluctuations do not impact planetary temperatures. To cause a continuous increase in planetary temperature requires a continually increasing energy source. Fluctuations are nothing more than noise.
Once again, RIE demonstrates a lack of understanding of the fundamentals.
To sustain an increase in planetary temperature requires a permanent increasing energy source. Fluctuations are just noise.
What so hard to understand about that?
Climate has always changed – Earth system science 101. How does he imagine that works? The simple answer is that he cannot.
https://watertechbyrie.files.wordpress.com/2018/05/nile-e1624996429189.jpg
“Climate has always changed – Earth system science 101. How does he imagine that works? The simple answer is that he cannot.”
You are really bad at this.
Data from the Nile? Really? Did you ever think that taking data from a limited geographic region might not be representative of climate on the planet? No? Why am I not surprised?
Climate doesn’t vary for no reason. It takes energy to make the climate change. You are completely CLUELESS!
What? Are we going thorough some kind of phase? In a few years the temperature of the planet is going to drop because “the climate has always changed?” LOL!!!
Amateur hour.
I am very good at this – and I have been doing it for a long time. JJ just doesn’t know enough to realise it. But then he is one of these people for whom dissent from whatever trifle possesses their lofty intellect is ignorance.
The Nile River records are of particular interest because of their length – and because hydrologist Harold Hurst discovered in them – in the first half if the last century – something that transforms climate statistics – and indeed much else. Nile River flows are influenced – btw – by both Pacific and Atlantic Ocean states.
e.g. https://www.researchgate.net/publication/227670614_Hurst-Kolmogorov_Dynamics_and_Uncertainty
“I am very good at this – and I have been doing it for a long time. JJ just doesn’t know enough to realise it.”
That’s your ego talking. The reality is quite different.
I don’t care how long the Nile statistics are taken. It’s too limited a geographic area to be significant. The changes in the Nile statistics could have just as easily been caused by energy transfers without climate change.
Climate deniers use this approach all the time. I’ve seen them chart the number of hurricanes in the Gulf over decades and claim the numbers didn’t change enough for climate change to be occurring.
The only data that you can draw conclusions from are worldwide and the broader the category of events the better. I use the number of worldwide extreme weather events as reported by the insurance industry over decades.
https://image.slidesharecdn.com/companypresentationsblue21deltasyncindymo-170912160433/95/floating-cities-for-human-and-ecological-progress-monitored-real-time-by-aquatic-drones-8-638.jpg?cb=1506072823
I stopped reading at climate denier. I am not even close. Climate is a globally coupled, spatiotemporal chaotic system. It is primarily a problem in fluid dynamics governed by the Navier-Stokes equation unpacked into millions of partial differential equations in 3 dimensions It is trying to explain invariant set theory to a baboon – but it is how the world works at every scale.
JJ, I was wrong about you. I thought you could learn.
The only thing I could learn from you is anti-science. No thanks! I’m good.
JJ is one of the brainwashed, refusing to expand his knowledge, since he’s been told what to think his entire life.
It’s a cinch that a year from now he still won’t know the significance of geothermal activity in Antarctica.
Why learn the complexities and intricacies of the debate when The Control Knob Theory is peachy keen and all you need to know.
“JJ is one of the brainwashed, refusing to expand his knowledge, since he’s been told what to think his entire life.”
I’m not “brainwashed”. I understand the science — you don’t. The problem here is not about me, but about your ignorance.
“It’s a cinch that a year from now he still won’t know the significance of geothermal activity in Antarctica.”
Sure I will. With regards to climate change, the significance will be insignificant. It will be the same 1 yr from now, 5 years from now, or 100 years from now. Geothermal is too small to have an impact on climate change.
“Why learn the complexities and intricacies of the debate when The Control Knob Theory is peachy keen and all you need to know.”
Why worry about complexities that don’t matter? It’s the same as worrying about the complexities of the origin of naval lint.
JJ
I’m trying to keep you from embarrassing yourself any more. It’s not about warming the planet. If you had taken my advice and had done some research you would have known that. Like I said, a year from now you still won’t figure it out.
“I’m trying to keep you from embarrassing yourself any more.”
I’m not the one embarrassing themselves.
“It’s not about warming the planet.”
It not about warming the planet? Really? What planet do you live on? It’s all about warming the planet. If the planet keeps warming at the current rate, there will be nobody left to give a damn what happens in the Antarctic, and there won’t be an Antarctic to worry about.
Your priorities are screwed-up.
“ Open-ocean convection in the Weddell Sea releases large amounts of heat into the atmosphere approximately every 75 years …….”
“ In summary, we see that global energetic equilibrium is coupled to the response to Weddell Sea convection. The increased TOA radiative flux into the system at SH ice latitudes is transmitted into the SH tropics, then across the equator and into the Northern Hemisphere via the altered Hadley circulation. The Hadley circulation thus transports anomalous energy into the cooler (northern) hemisphere via its upper branch and moisture into the opposite (southern) hemisphere, such that the ITCZ shifts to the warmer (southern) hemisphere.”
Cabre et al 2017
https://journals.ametsoc.org/view/journals/clim/30/20/jcli-d-16-0741.1.xml
Studies such as the subject of this post and Cabre 2017 are providing new insights into the climate dynamics on a regular basis. In any other field they would provide the impetus to rethink some aspects of previously held views.
Not so in climate science. Regardless of new understandings, they hold on to the same views that have dominated thinking for the last 40 to 50 years. That is a result of intellectual inertia.
“Not so in climate science. Regardless of new understandings, they hold on to the same views that have dominated thinking for the last 40 to 50 years. That is a result of intellectual inertia.”
Climate science has become a religion, with its orthodox view being that of the IPCC.
Mickey Mann for Pope!
LOL
“However, one thing can already be stated: the warming of the last 20 years has been caused more by change in the clouds than by the classical greenhouse effect.”
Very well said! Thank you.
https://www.cristos-vournas.com
Jim Hunt | October 10, 2021 at 8:06 am |
Mornin’ Angech,
You know more about the topic of Earth’s energy (im)balance than “a graduate student in atmospheric and oceanic sciences (AOS) at Princeton”
Thank you.
Judith has this up as a new discussion so pop over to that thread and I will bemuse you.
Will be fun putting up NASA/NOAA’s very humble opinion:
https://www.nasa.gov/feature/langley/joint-nasa-noaa-study-finds-earths-energy-imbalance-has-doubled
Researchers have found that Earth’s energy imbalance approximately doubled during the 14-year period from 2005 to 2019.
Will the Princeton chappie be able to cope with a real Professor?
Contrast with
https://www.nasa.gov/feature/langley/joint-nasa-noaa-study-finds-earths-energy-imbalance-has-doubled
Researchers have found that Earth’s energy imbalance approximately doubled during the 14-year period from 2005 to 2019.
Earth’s climate is determined by a delicate balance between how much of the Sun’s radiative energy is absorbed in the atmosphere and at the surface and how much thermal infrared radiation Earth emits to space. A positive energy imbalance means the Earth system is gaining energy, causing the planet to heat up…
Scientists at NASA and NOAA compared data from two independent measurements. NASA’s Clouds and the Earth’s Radiant Energy System (CERES) suite of satellite sensors measure how much energy enters and leaves Earth’s system. In addition, data from a global array of ocean floats, called Argo, enable an accurate estimate of the rate at which the world’s oceans are heating up. Since approximately 90 percent of the excess energy from an energy imbalance ends up in the ocean, the overall trends of incoming and outgoing radiation should broadly agree with changes in ocean heat content.
Off Topic: There’s a fantastic collection of very detailed skeptical comments about the basics of CAGW on Jo Nova’s current thread, starting at:
https://joannenova.com.au/2021/10/google-demonetizes-climate-skeptics-and-bans-denier-ads-because-skeptics-win-over-too-many-people/#comment-2477715
I enjoyed reading that thread, as an example of blog commenting sociology. Much more productive and interesting discussion than many discussions at CE, notably no sniping or p*ssing matches among commenters
Yes. Good point. Joannenova.com is a shining beacon of good faith dialog among people of differing viewpoints.
Lol.
What you may not realize about the Jo Nova blog is that comments that do not agree with Ms. “Web Sheriff” are forced into moderation, and sometimes censored (not published).
I’m not talking about nasty comments or arguments.
Just respectful disagreements with the author of the article, who is usually Jo Nova — an author who perceives herself as an expert on climate, energy, COVID, the US election, and Australian politics.
,
My comments were at first put into 100% moderation, and then some were never published. Ms. Nova last insulted my intelligence for simply stating the truth — that PCR tests with high CT rates were not accurate.
She printed my comment but plastered it with her bold bright blue ink comments, repeatedly scolding me for misinformation, which in her world is not agreeing with her.
My response comment, trying to defend my original comment, was not published.
.I have never tried to post another comment at Jo Nova, and never will.
The downside of civility can be censorship.
No blog or website in my 25 years of using the internet, and commenting frequently, has ever censored my comments, with one exception:
One comment criticizing US acres burned data for the 1930’s, with an explanation of why the data were not likely to be accurate, got me PERMANENTLY banned from commenting at Tony Heller’s Real Climate Science Website.
Leftists censor and ban contradictory comments — I expect that.
But It is surprising when “free speech” conservatives do the same.
It is a slippery slope from deleting nasty comments … to deleting comments that do not agree with the author of the article.
Richard Greene
Bingham Farms, Michigan
Hello Richard,
“The downside of civility can be censorship.
No blog or website in my 25 years of using the internet, and commenting frequently, has ever censored my comments.”
I have a long list of “skeptical” websites where my perfectly civil comments about Arctic sea ice are censored.
See my conversation with Willis upthread for one example out of many.
Richard
I tend to agree with Jo about Climate change and disagree about the election being ‘stolen’ from Trump, and the pandemic, especially Australia’s over reaction to it.
She has never censored any of these posts, although the number of dissenters there tends to be fewer than on Climate etc..
Mind you the dialogue is usually a lot more constructive than over here, which has far too many sniping or p*ssing matches amongst the same few suspects. I wish they would stop, it is very tiresome and stops a proper discussion dead.
tonyb
Jim –
> I have a long list of “skeptical” websites where my perfectly civil comments about Arctic sea ice are censored.
I would argue that having blog comments moderated by a proprietor of a blog is most definitely not “censorship.”
Imo, calling that “censorship” trivializes a serous problem that happens in countries where free expression truly is censored.
Evening Joshua,
I was echoing Richard’s use of the word “censored”.
What word would you choose to describe “comments moderated by a proprietor of a blog” when said comments manifestly fail to contravene said blog’s published commenting policy?
Richard –
> Ms. Nova last insulted my intelligence for simply stating the truth — that PCR tests with high CT rates were not accurate.
Not that I’m defending Jo moderating your comments, but stating that PCR tests with high CT rates are not accurate is simply false. As such, saying so is misinformation, indeed. It’s certainly a blog proprietor’s right to not have her blog promoting misinformation.
PCR tests capture pre- and post-infectious stage infections, no doubt. But that doesn’t mean they aren’t accurate, or that they’re capturing “false positives” (if that’s what you’re arguing).
Hey Jim –
How about capriously moderated? Or selectively moderated? Or mercurially moderated? Or maybe just moderated?
Blog proprietors get to moderate comments for whatever reason they wish. I often see the moderated claim victimhood when the proprietor just felt that they were deleting obnoxious or off-topic comments or annoying comments. My own belief is that almost always, if a commenter is thoughtful they can word their comments that get the basic substance of their point across without eliciting moderation. Often commenters think they’re moderated because the proprietor is seeking to hide damaging perspectives – and while there may be some truth to that the proprietor never thinks that’s the reason.
Joshua – I still reserve the right to take umbrage when a series of carefully worded comments of mine that conform to a site’s published comment policy all end up on the cutting room floor of a “selective moderator”.
Back to the “flux variations”!
I didn’t mention in my earlier comment that climate alarmists websites typically keep their comments “productive” by deleting comments that disagree with the author.
I forgot that I had been banned from commenting at Skeptical Science after just one comment (at the time I thought the site encouraged debate, based on the name “skeptical”).
I had commented that here in Michigan, we enjoyed the global warming since the 1970s, and hoped it would continue. And I speculated that lots of people living in colder areas enjoyed global warming. My comment was deleted in hours, and then I was permanently blocked !
But now I expect that from Climate Alarmist websites, so never visit.
This website is so much better.
One of the best climate websites in the world.
In response to Joshua,
who scolded me on PCR tests,
just like Jo Nova did (are you related?),
I will quote Tony Fauci’s position
identical to what I have stated:
July 16, 2020, podcast,
“This Week In Virology”
— Tony Fauci’s key quote:
“…If you get [perform the test at] a cycle threshold of 35 or more…the chances of it being replication-competent [aka accurate] are miniscule…you almost never can culture virus [detect a true positive result] from a 37 threshold cycle…even 36…”
(starting at the 4m01s mark through to the 5m45s mark
— Fauci begins his first answer to the first question at the 4m20s mark and begins his second answer to the second question at the 5m26s mark):
Now you can argue with Tony Fauci too !
Richard –
So as to avoid moderation…just one more comment on this topic.
To show how vapid your argument is, I’ll just point out that hospitalizations, ICU admissions, and deaths have all tracked with positive tests, all over the planet, throughout the pandemic.
If you think that Fauci was arguing that the PCR tests aren’t accurate, you’re sadly mistaken. The idea that he’d promote their use of PCR tests despite them being inaccurate is the kind of wild conspiracy theory that you might find at certain climate websi….
Oh, wait.
I submit comments irregularly in very few places and never expect any of them to appear or stay appeared. . I believe It is the right of the provider to ‘disappear’ any comment I may make as it is their site and not mine.
I was once a regular on the Guardian and the BBC sites in the days of more open debate on climate matters and have had increasing numbers of contributions disappear since ‘consensus’ became fashionable. I have never been banned but I no longer post regularly. I have found better ways of producing arguments that do not disappear quite so quickly on either site.
I disagree with Jo Nova on SARS-CoV-2 origin and mitigation but my posts appear no matter. I posted an alternative view of the inappropriate US Election activities and 1/6/21 insurrection video. It was not popular but that isn’t the point – is it?
I am just grateful that there are sites such as these where you have a chance to join in, but I will not take that chance for granted because I know the risk sites run in the ‘current censorship climate’ with which I throughly disapprove. I have learned so much from this site and for that I am very grateful to Dr Curry and the many comment contributors who have encouraged me to look furher and think deeper.
“I enjoyed reading that thread, as an example of blog commenting sociology. Much more productive and interesting discussion than many discussions at CE”
As shareholders in her and David Evan’s Global Cooling hedge fund may find Fahrenholt’s discourse fascinating, as a matter of optics, Jo ought to disclose her interest in the fund when publicizing information that could affect share values.
You old cynic RS!
I have to admit that it’s many years since I’ve bothered trying, but for some strange reason Jo was never very keen on my Arctic words of wisdom.
The credibility of most skeptic blogs dropped to zero for me as soon as they started peddling nonsensical election conspiracy theories. It forced me to rethink my own views on climate change since I thought I learned so much from people who are clearly more interested in twisting facts to suit their desired reality.
Thanks for the heads up Angech,
I am eagerly awaiting becoming bemused!
Here is the recent paper by “the Princeton chappie” you refer to:
https://www.nature.com/articles/s41467-021-24544-4
and here is the 2014 paper by Pistone et al. about “Arctic albedo” that Willis Eschenbach is currently studiously ignoring over at WUWT:
https://GreatWhiteCon.info/2021/10/whats-up-with-that-arctic-sea-ice-disinformation/#Willis
Jim, I don’t “studiously ignore” a damn thing, so you are either jumping to false conclusions or lying.
Some guy called “greatwhitecon” claimed he’d posted a comment on WUWT, but as your link points out, it has not appeared. I am waiting to comment on it there when it does appear, but I fear responding there to an invisible comment is beyond my capabilities.
Having read the link that greatwhitecon provided, I see that Pistone and I are measuring very, very different things. I looked at surface albedo (surface all-sky upwelling sw divided by surface all-sky downwelling sw). This is the usual definition of “albedo”, reflected divided by incident.
Pistone, on the other hand, looked at a hybrid measure (toa upwelling clear-sky SW divided by toa downwelling SW). Pistone’s measure is affected by a number of other factors (atmospheric absorption of downwelling SW, atmospheric absorption of upwelling SW, and a variety of cloud-related factors affecting both up- and downwelling SW), so it is not the actual albedo of the surface.
As a result, the two variables are incommensurate. And that means that the conclusion by the great white conman is unsupported.
Finally, as I pointed out in my post, I was merely extending the findings of Kato, viz:
Happy now?
w.
Evenin’ Willis (UTC),
FYI “Snow White” is female, and my Arctic alter ego:
https://twitter.com/GreatWhiteCon/status/1447173783882768384
I thought you were well aware of that fact. My apologies if you were not.
My “studiously ignoring” remark referred to this comment over at WUWT which, unlike my own, appears to have been visible for all to see since October 4th:
https://wattsupwiththat.com/2021/10/03/a-robust-balance/#comment-3358738
I would argue that the spectacular decline in the strength of the solar magnetic field seen in the 25th solar cycle is deliberately kept quiet by scientists. This is due to human powerlessness in the face of climate change, which is inevitable. It will especially affect people in the middle latitudes.
https://i.ibb.co/X73wwjR/onlinequery.gif
https://www.iup.uni-bremen.de/gome/solar/mgii_composite_2.png
http://wso.stanford.edu/gifs/Dipall.gif
Ireneusz, despite looking in a long list of places, I’ve never found any actual evidence that any sunspot-related changes (changes in TSI, heliomagnetic field, solar wind, etc.) have any perceptible effect on surface-level weather phenomena of any kind.
Links to thirty-six of my analyses on the subject are here.
If you have such evidence, please provide a link. Note–please, no claims based on reanalysis “data”.
And yes, as a ham radio operator (H44WE) I’m well aware that sunspots affect the ionosphere. I’m talking about affecting weather here at the surface where we live.
Thanks,
w.
Willis
The problem lies in the fact that we can only infer the effects of low solar activity from climate information from about 100 years ago. Now everything will be new, because we haven’t had such weak solar magnetic activity in the satellite era. Galactic radiation measurements and WSO observations at Stanford leave no illusions.
https://i.ibb.co/k6bC59g/gfs-hgt-trop-NA-f036.png
The relationship between climatic parameters and the Earth’s magnetic field has been reported by many authors. However, the absence of a feasible mechanism accounting for this relationship has impeded progress in this research field. Based on the instrumental observations, we reveal the spatio-temporal relation ship between the key structures in the geomagnetic field, surface air temperature and pressure fields, ozone, and the specific humidity near the tropopause. As one of the probable explanations of these correlations, we suggest the following chain of the causal relations: (1) modulation of the intensity and penetration depth of energetic particles (galactic cosmic rays (GCRs)) in the Earth’s atmosphere by the geomagnetic field; (2) the distortion of the ozone density near the tropopause under the action of GCRs; (3) the change in temperature near the tropopause due to the high absorbing capacity of ozone; (4) the adjustment of the extra tropical upper tropospheric static stability and, consequently, specific humidity, to the modified tropopause temperature; and (5) the change in the surface air temperature due to the increase/decrease of the water vapor greenhouse effect.
https://www.researchgate.net/publication/281441974_Geomagnetic_Field_and_Climate_Causal_Relations_with_Some_Atmospheric_Variables
http://www.geomag.bgs.ac.uk/images/charts/jpg/polar_n_dz.jpg
Ireneusz, please supply us with more geomag data for 2025.
World Magnetic Model (WMM)
The World Magnetic Model (WMM) is a standard model of the core and large-scale crustal magnetic field. It is used extensively for navigation and in attitude and heading referencing systems by the UK Ministry of Defence, the US Department of Defense, the North Atlantic Treaty Organization and the International Hydrographic Organization. It is also used widely in civilian navigation and heading systems.
Annual rate of change of declination for 2020.0 to 2025.0 from the World Magnetic Model (WMM2020). Red –easterly change, blue – westerly change, green – zero change. Contour interval is 2’/year (1/30th of a degree), white star is location of a magnetic pole and projection is Mercator.
https://geomag.bgs.ac.uk/images/charts/wmm2020_dd_merc_nocaption.jpg
https://geomag.bgs.ac.uk/research/modelling/WorldMagneticModel.html
https://geomag.bgs.ac.uk/data_service/models_compass/polarsouth.html
http://www.geomag.bgs.ac.uk/data_service/models_compass/polarnorth.html
“Galactic Cosmic Ray-driven amplification mechanisms
In Section 2.6.1, we discussed how several researchers have argued for Sun/climate relationships that are driven by the larger variability in the UV component of the solar cycle, rather than the more modest variability over the solar cycle in TSI. Since most of the incoming UV irradiance is absorbed in the stratosphere, this has led to various “top-down” mechanisms whereby the Sun/climate relationships begin in the upper atmosphere before being propagated downward, as schematically illustrated in Figure 4(a). However, other researchers have focused on a separate aspect of solar variability that also shows considerable variability over the solar cycle, i.e., changes in the numbers and types of GCRs entering the Earth’s atmosphere. Because the variability in the GCR fluxes can be different at different altitudes, but some GCRs are absorbed in both the troposphere and the stratosphere, such mechanisms could potentially be relevant throughout the atmosphere (Carslaw et al. 2002; Ney 1959; Dickinson 1975) – Figure 4(c). Also, because both the flux and the variability in the incoming GCR fluxes increase with latitude (greatest at the geomagnetic poles (Carslaw et al. 2002; Ney 1959; Dickinson 1975)), if such mechanisms transpire to be valid, this might mean that the Sun/climate relationships are more pronounced in some regions than others (Sect. 2.6.3).”
Sorry.
Research in Astronomy and Astrophysics that they were reporting on, i.e., Connolly et al. (2021): https://doi.org/10.1088/1674-4527/21/6/131
Probably also affects fluid dynamics. Modulation of cosmic rays by the sun likely affects ionization in oceans and magma. Magnetic field in turn will affect the pressure and circulation of these fluids over long periods of time.
Willis Eschenbach | October 10, 2021 at 1:33 pm | Reply
”despite looking in a long list of places, I’ve never found any actual evidence that any sunspot-related changes (changes in TSI, helio magnetic field, solar wind, etc.) have any perceptible effect on surface-level weather phenomena of any kind.”
-Is there or is there not a change in energy output during the solar cycles which are defined by the presence or absence of sunspots?
If there is a detectable fluctuation in energy output and the presence of said sunspots defines these solar cycles then there must be an effect on climate.
Unless you are purely referring to the sunspot perturbations themselves?
one glass of water.
In space shine a flashlight on it, turn it off. Energy in energy out.
Glass of water reverts to its original temperature.
There is no battery in matter.
Matter is stored energy.
EMR is moving energy.
There is no radiative imbalance when energy impinges on matter.
Difficult questions.
If the energy going out at the TOA is the same as the energy going in.
It is by definition and a liberal application of SB law.
How can there be any continuing gain of energy in the system?
The standard way around this impasse.
It is an impasse as one either accepts the physics we are taught is true or we prevaricate and make excuses.
The standard excuse is the heat is stored in the oceans.
“We also considered the effect of this radiative excess on the heat content of the climate system . Since about 90% remains as heat in the oceans, conclusions can be drawn by looking at long-term ocean heat content ”
The ocean is not a battery.
It is not a heat sink
Complex open systems lose heat continually.
Entropy.
Can anyone give one good rational reason for a non heat producing body, on its own, producing any heat de novo.*
If it encounters a pulse of energy as EMR, does it not immediately radiate the energy out.
*Excluding radioactive nuclear decay this is impossible in our system of physics.
So why when we heat up a glass of water on the earth does it not go back to room temperature immediately.
How come it is showing the result of a persistent radiative imbalance?
Is there storage of the heat in the glass of water?
RIE’s and many others point of view.
Does everyone agree that the energy is stored in the glass of water?
If you do then the SB law is wrong.
If the SB law is wrong then all our physics including this article goes out the window.
There is an answer, obvious but invisible, that saves the law.
It saves the definition of TOA [indeed depends on it]
It makes redundant all of these Energy imbalance theories.
It preserves the GHG theory.
Of course, we know that the atmosphere is not isothermal. In fact, air temperature falls quite noticeably with increasing altitude. In ski resorts, you are told to expect the temperature to drop by about 1 degree per 100 meters you go upwards. Many people cannot understand why the atmosphere gets colder the higher up you go. They reason that as higher altitudes are closer to the Sun they ought to be hotter. In fact, the explanation is quite simple. It depends on three important properties of air. The first important property is that air is transparent to most, but by no means all, of the electromagnetic spectrum. In particular, most infrared radiation, which carries heat energy, passes straight through the lower atmosphere and heats the ground. In other words, the lower atmosphere is heated from below, not from above. The second important property of air is that it is constantly in motion. In fact, the lower 20 kilometers of the atmosphere (the so called troposphere) are fairly thoroughly mixed. You might think that this would imply that the atmosphere is isothermal. However, this is not the case because of the final important properly of air: i.e., it is a very poor conductor of heat. This, of course, is why woolly sweaters work: they trap a layer of air close to the body, and because air is such a poor conductor of heat you stay warm.
https://farside.ph.utexas.edu/teaching/sm1/lectures/node56.html
https://www.cpc.ncep.noaa.gov/products/stratosphere/strat-trop/gif_files/time_pres_TEMP_MEAN_ALL_EQ_2021.png
angech
“There is an answer, obvious but invisible, that saves the law.
It saves the definition of TOA [indeed depends on it]
It makes redundant all of these Energy imbalance theories.
It preserves the GHG theory.”
There is the answer! It is the Planet Surface Rotational Warming Phenomenon.
https://www.cristos-vournas.com
Jim Hunt | October 10, 2021 at 8:46 am | Reply
Thanks for the heads up Angech,I am eagerly awaiting becoming bemused!
I may have gone in a bit too deep for everyone, including myself, Jim.
You might just have to put up with rolling on the floor laughing.
angech, something to think about. Wikipedia:
“The temperature of the ocean at depth lags the Earth’s atmosphere temperature by 15 days per 10 meters (33 ft), which means for locations like the Aral sea, temperatures near its bottom reaches a maximum in December and a minimum in May and June.”
https://rclutz.com/2015/04/21/the-climate-water-wheel/
Clouds net zero
virakkraft.com/CERES-ToA-Net-CRE.pdf
Should you not find the integral here and see if it is mainly positive or negativ during the time period*?
It is worth noting that with La Niña advancing, the western equatorial Pacific shows no surface anomalies.
https://coralreefwatch.noaa.gov/data_current/5km/v3.1_op/daily/png/ct5km_ssta_v3.1_pacific_current.png
The glass of water remains hot for a while [cools down slowly] because it has now become part of the system releasing incoming energy back to space.
This can only be done if the emitting CO2/H2O GHG at high levels are excited enough to release enough outgoing energy to space as what is coming in. This is achieved by each of the levels below this being excited enough to pass enough energy up to the emitting molecules.
The result of this is increasingly warm and more densely packed atmospheric particles below this down to the surface.
At the surface the incoming SW radiation from the sun and the very large amount of IR radiation from the atmosphere close to the surface causes the surface to rise well above the temperature that the short wave on its own could induce.
All this seeming energy is still only due to the actual SW from the sun.
No actual extra energy is produced.
The heated surface is losing [transmitting] the 163 W of SW it received back to space by various methods.
Because of the layering and back radiation it has to heat up to an emission temperature of 288K.
This is not a storage of energy level.
The energy is going out but a lot is coming back in.
It is the level required at the surface to maintain the correct TOA emission.
The glass of water is purely part of the surface.
The energy required to heat it up has already left the glass and gone through the TOA .
The energy now in the glass is coming in from the surrounding atmosphere and will reduce in time to the atmospheric temperature based on its specific heat.
Wait – hold on one minute:
I thought it’s the Sun wot dunnit:
-snip-
In 2012 Vahrenholt together with geologist Sebastian Lüning published Die kalte Sonne: warum die Klimakatastrophe nicht stattfindet[7][8] (The Cold Sun: Why the Climate Crisis Isn’t Happening), a book asserting that climate change is driven by variations in solar activity. They predict the Earth is entering a cooling phase due to periodic solar cycles, and will cool by 0.2 to 0.3 degrees C by 2035.[4]
Here are two claims:
(C1) The cloud changes can be caused by a decrease in aerosols, by atmospheric warming due to natural causes (e.g. the AMO or the PDO), by anthropogenic warming due to CO2, or by a combination of these individual factors.
(C2) The warming of the last 20 years has been caused more by change in the clouds than by the classical greenhouse effect.
It might be hard to go from C1 to C2.
Willard made a good argument that many variables could have affected the climate in a 20 year period — it would be very difficult to know exactly what each variable did, and then determine causes versus effects.
You almost got it, RG.
I don’t argue that many variables could have affected the climate in a 20 year period. I argue that once you assume etc, it’s hard to then exclude one of them.
Well, it’s not that hard – Denizens reward this kind of infelicity!
Willard | October 12, 2021 at 6:58 pm |
“I don’t argue that many variables could have affected the climate in a 20 year period”
.What’s Holding Antarctic Sea Ice Back From Melting?
why then is sea ice in the Antarctic slowly increasing?
Apologies to Paul Simon – 50 ways to leave your lover
Dwindling Ozone Levels
A More Stratified Southern Ocean
Flooded Sea Ice Turns Snow to Ice
A Phenomenon Due to a Lot of ‘Hot Air’?
“Almost all of the CMIP5 models produce a decrease in Antarctic sea ice
increasing northward winds during the autumn caused the variations.
seasonal wind trends for the different regions.
paradoxically Ocean warming and enhanced melting of the Antarctic ice
there is no consensus on the reason for the expansion.
You’re Just Asking Questions once again, Doc.
It has nothing to do with the point I made.
It’s boring.
σ*288^4 – σ*255^4 = 390W/m^2 – 240W/m^2 = 150W/m^2
The Greenhouse Theory claims that atmosphere emits IR EM energy of 240W/m^2 outgoing to space energy at high altitude levels where the atmospheric temperature reaches 255K or -18C.
Thus the Greenhouse Theory equalizes a solid blackbody surface of 255K IR EM energy radiation (240 W/m^2) with the at some elevated altitude the thin atmosphere’s of 255K IR EM radiation (240W/m^2).
It is scientifically impossible to expect from a thin gas to emit the same as a solid body (metal) to emit the same IR EM per m^2 (240 W/m^2) amount of energy. Because there are not enough atoms and molecules in a thin gas layer outstretched per m^2 to emit that amount of energy.
https://www.cristos-vournas.com
Nonsense
https://scienceofdoom.com/2013/01/08/visualizing-atmospheric-radiation-part-three-average-height-of-emission/
“”The Greenhouse Theory claims that atmosphere emits IR EM energy of 240W/m^2 outgoing to space energy at high altitude levels where the atmospheric temperature reaches 255K or -18C.”
–
No
GHG Theory is about warming of the lower surface related atmosphere.
Radiation theory.
Yes
SB Law is what specifies that the outgoing radiation is 240W/m^2 at the TOA.
It is not a claim, it is a fact.
The mass and volume of the GHG in the atmosphere able to emit directly to space is immense.
It is difficult to give a precis of this but…
Consider the energy incident on a solid airless planet surface with no albedo.
It is all absorbed by a thin layer of surface molecules which radiate the energy back to space as IR.
One thin one molecule deep layer of molecules.
That’s it.
It does not matter how thick the planet is the only bits that can radiate back are the single surface layer molecules.
In real life we fudge it a bit and say well some might get through to the second or third layer and back out again,
So that one thin layer of closely packed molecules is it.
and it radiates IR at 240 W/M2.
which is colder by far than the actual surface temperature of a planet with GHG
This is the amount of energy that a GHG planet has to put out at TOA.
What do we find?
A much larger surface area of exactly the same emitting molecules at the earths 1 layer thick surface.
Every particle of the kilometers thick higher atmosphere has to block the same energy that comes from the surface and remit it to space unimpeded.
But there are a lot more particles in this spread out 1 molecule thick layer emitting to space.
Hence the energy they have to give out per surface area] is greatly reduced but the amount still equals 240 W/m2.
It is a fact.
The planet blackbody temperature – the effective temperature Te is a parody of the Stefan-Boltzmann emission law.
Please compare:
Jemit = σΤ⁴ (W/m²), uniform surface emittance intensity, which leads to
T = (Jemit /σ )¹∕ ⁴ uniform surface temperature
And
Jemit = (1 – a) S/4 (W/m²), averaged surface emittance intensity, which leads to
Te = [ (1-a) S /4σ ]¹∕ ⁴ uniform surface temperature.
It is a parody of SB law!
https://www.cristos-vournas.com
Please state the source for your “uniform”, “averaged”, etc. As far as I can understand both from your comment here, and your webpage these are not real, but just stuff you are making up. The temperature of a planet is not uniform, and the average is meaningless in this T^4 context as repeatedly demonstrated. The energy both incoming and outgoing is not “uniform” over the surface of a sphere either. I am not sure your use of the word “parody” is correct English, but as I am also not sure what your point is I can not tell for sure.
atandb
“The temperature of a planet is not uniform, and the average is meaningless in this T^4 context as repeatedly demonstrated. The energy both incoming and outgoing is not “uniform” over the surface of a sphere either.”
Very much agreed!
https://www.cristos-vournas.com
Christos: My main message is that science usually doesn’t progress by searching for equations and parameters. Von Neumann said with four parameters I can model the outline of an elephant and with a fifth parameter make his nose wiggle. One of the idiots pushing theories about voting machines stealing has found that a 6 degree polynomial can predict certain voting patterns, proving fraud. With seven adjustable parameters, one can fit an elephant and make its nose and tail wiggle and make election results appear fraudulent
The scientific method starts with one hypothesis that you test, not sorting through an infinite number of possible hypotheses to find one that fits your data. In Cargo Cult Science, Feynman advises that a theory constructed using data should predict something besides the data that inspired the theory.
In complicated situations, you need to start with the correct physics for the fundamentals – which means you don’t violate Kirchhoff’s by incorporating a solar acceptance parameter so absorptivity is not equal to emissivity. If you have an atmosphere, you need the correct physics for predicting radiative transfer from the surface to space.
Box famously said that all models are wrong, but some models are useful. You can model a limited data set with a complicated equation, but that doesn’t mean you model is useful for anything.
Unfortunately, your favorite tool (your hammer) is fitting parameters. To you, every scientific problem looks like a nail.
Christos Vournas
-It is scientifically impossible to expect from a thin gas to emit the same as a solid body (metal) to emit the same IR EM per m^2 (240 W/m^2) amount of energy.?
Emissions occur from the surface of a body only. It does not matter whether it is solid or not.
If a “thin” gas has enough depth then there will be as many molecules capable of emitting IR as a solid body surface.
In fact more given that the surface area at the average altitude of such an emitting gaseous layer would be larger than that of the surface of a smaller spherical solid body.
It is scientifically possible.
Your argument is incorrect.
angech,
“Emissions occur from the surface of a body only. It does not matter whether it is solid or not.
If a “thin” gas has enough depth then there will be as many molecules capable of emitting IR as a solid body surface.”
I understand that, but the Stefan-Boltzmann emission law equation does not describe this phenomenon.
https://www.cristos-vournas.com
Christos: If our atmosphere were condensed into a liquid the same density as water, it would be 10 m deep. If it separated into layers, the CO2 layer would be 4 mm thick. Like our atmosphere, the glass in a car sitting in the sun lets most visible light in and doesn’t let much thermal infrared out. A liquid layer may be a more tangible model for the mass of GHGs in our atmosphere. The minor GHGs would form thinner layers. Even a layer of PABA in sunscreen is thin enough to have a big impact on radiation. Since this is an intuitive MODEL or thought experiment for the atmosphere that isn’t intended to accurately represent all of its physics.
Our planet behaves like a black-body at 255 K in some ways – it emits an average of 240 W/m2 of thermal infrared. However, it clearly IS NOT a blackbody because the spectrum of thermal infrared it emits does not look like the spectrum of a blackbody. You are offering a Blackbody MODEL for our planet. Like all MODELS, it gets some features of the real object correct and not others.
Then we come to Stefan-Boltzmann MODELS for the atmosphere. Since the temperature of the atmosphere and surface varies from 190 K to 310 K, no single temperature is unambiguously appropriate a S-B MODEL for our planet. When you include an adjustable emissivity, there are an infinite number of possible S-B MODELS for the emission from our planet: W = -eoT^4 = 240 W/m2. Taking the derivative gives dW/dT = -4eoT^3. If you choose the MODEL e = 0.61, T = 288, dW/dT = -3.3 W/m2, which is very near the -3.2 W/m2 value produced by much more sophisticated MODELS that break the surface and atmosphere up into about 1 million grid cells with fairly realistic temperature and composition for each grid cell. The AOGCM MODEL gets the spectrum of the thermal infrared emitted by the planet correct, but the e = 0.61, T = 288 S-B MODEL does not – it only gets W and dW/dT correct. dW/dT is critical because that is the LWR feedback in response to global warming.
However, this e = 0.61, T = 288 S-B MODEL is still INCORRECT, because I assumed that emissivity is independent of temperature when I took the derivative. Since water vapor is one of the major molecules that emits thermal infrared to space (and absorbs it on the way), controls the lapse rate and clouds, and varies with temperature, we can’t ignore the de/dT term – it includes water vapor, lapse rate and cloud LWR feedbacks! If you look at how the planet’s radiative imbalance (R) varies with temperature (dR/dT), you will also have terms for how surface and cloud albedo change with temperature – SWR feedbacks.
My point is that we are always talking about the behavior of MODELS for the real world, not the real world itself. This is why I have been capitalizing the word MODEL. If your MODEL doesn’t incorporate important physical processes, it won’t be useful. It isn’t that basic physics is wrong – your MODEL simply doesn’t include all of the physics. AOGCMs use parameters that are tuned to substitute for important physics that occurs on sub-grid scales. AOGCMs can be wrong too.
When you get down to the REAL basics, the S-B equation and Planck’s Law are also MODELS. Planck’s Law is derived ASSUMING radiation is IN THERMODYNAMIC EQUILIBRIUM (by absorption and emission) with the medium through which it is traveling. This assumption isn’t true at all wavelengths and altitudes in our atmosphere, most obviously at wavelengths in the “atmospheric window”. Schwarzschild’s Equation for Radiative Transfer is valid when such an equilibrium doesn’t exist and simplifies to Planck’s Law when it does. It is used to calculate radiation transfer in climate models. It is derived ASSUMING that collisions between gas molecules have produced a Boltzmann distribution of energy among ground and excited states (rotational, vibrational and, when hot enough, electronic). That assumption is called local thermodynamic equilibrium or LTE. That assumption breaks down above about 100 km, where absorption and emission can perturb a Boltzmann distribution faster than collisions create one. At some wavelengths, we also need to include scattering of radiation by particles, including individual gas molecules. Fortunately, this isn’t important for thermal infrared in the troposphere and lower stratosphere, where rising GHGs are producing the radiative forcing that is driving climate change. (LTE doesn’t exist in LED, lasers, fluorescent lights and other devices where excited states are not produced mostly by collisions.)
What you call “Greenhouse Theory” arises from applying Schwarzschild’s Equation to an atmosphere containing GHGs whose temperature drops with altitude (where most emission and absorption occur). Schwarzschild’s equation predicts that the radiation escaping through such an atmosphere will decrease with rising GHGs.
Emissivity is a fudge factor applied after integrating Planck’s Law over all wavelengths to account for a phenomenon that occurs at the interface between two different media. The same phenomena occurs when radiation enters AND exits a solid or liquid – some radiation is scattered backwards by the interface – and absorptivity equals emissivity at every wavelength. This is easy for me to understand for radiation entering a solid, but it is incomprehensible to me that radiation travels through a solid and is partly scattered backwards exiting into air. I can’t understand why emissivity – a phenomena that develops at interfaces between two media – can be used with some success in S-B MODELS for our planet when there is no distinct interface and scattering at the interface between the atmosphere and space! Certainly 61% of the photons reaching the edge of space are not scattered back towards the Earth. The emissivity fudge factor we use at the interface between a solid and air does not arise from same phenomena as the emissivity we assume for an S-B MODEL of the planet.
Fundamentally, the interaction between radiation and gases is controlled by Einstein coefficients. These coefficients become absorption cross-sections after line broadening by pressure, Doppler and uncertainty. Assuming LTE exists, one can then derive Schwarzschild’s equation for radiative transfer. By further assuming thermodynamic equilibrium between radiation and transmission medium, one gets Planck’s Law. An emissivity fudge factor is needed to deal with interfaces between transmission media.
All the climate physics we discuss comes from MODELS that are far from truly fundamental physics and contain assumptions. We need to be careful when and how we use them. They are MODELS.
Oh. Dangerous. I tried earlier to explain to people here that emissivity is a surface property and thus, cannot be strictly applied for gasses.
Expect resident “experts” and protectors of truth, like Willard and Robert Elliot to attack you at once. ;)))))
Minor nitpicking, After you differentiate dW/dT, the unit cannot stay W/m2 any longer.
ΔF = (1 – α)S – εσT^4
In this equation, α is the Earth’s albedo, S is the average solar energy flux, 342 W/m2, ε is the effective emissivity of the planetary system, σ is the Stefan-Boltzmann constant, and T is the average planetary surface temperature. If ΔF is zero, the energies are balanced.
Equivalently – the change in planetary heat and work is equal to energy in minus energy out.
d(W&H)/dt = Ein – Eout
Like Frank I don’t think emissivity has any physical meaning in the planetary context. It is a fudge factor to balance the 1st differential global energy equation when the surface temperature is 288 K. Like Isakov – not to be taken seriously.
Christos’ problem is the invention of physical laws based on an analogy with fluid drag. Science by analogy is very post modern.
Who said it wasn’t a fudge factor? Reality is different from an idealized equation. Sometimes its called an efficiency.
In thermodynamics we calculate reversible work and then apply an “efficiency” to come up with the actual work.
It’s not something that you can disregard.
288 K is a measured quantity. There is no need for an unphysical fudge factor. Thermal efficiency – otoh – has a very physical basis.
I wasn’t referring to a thermal efficiency. You do understand that work and heat are different? No? Not surprising.
If you were observing earth from space, and had a IR spectrograph that indicated a 288 K blackbody temperature, and the IR radiation rate that indicated a 255 K blackbody temperature. You could calculate an emissivity to correct the S-B equation — not even knowing what was causing the discrepancy.
Thermal efficiency relates heat input to work output. The surface is at 288 K but the Earth emits mostly from the atmosphere. It is not blackbody emission quite obviously. I think JJ must be a road engineer – the drummers of engineering.
You are CLUELESS!
What I was referring was work efficiency used to correct work calculated from an equation for reversible work. It has nothing to do with thermal efficiency. If you knew anything about thermodynamics, you’d understand that.
Think efficiency related to a pump or compressor.
That is your postmodern science by analogy. I brought to reality. You are a pompous, full of yourself twit nattering on with simple minded though bubbles.
“That is your postmodern science by analogy.”
What I wrote has been part of classical thermodynamics for decades and decades and decades. It’s not my fault you don’t have a clue.
“I brought to reality.”
Your reality in the fantasy world you live in. Out in the real world, reality is completely different.
“You are a pompous, full of yourself twit nattering on with simple minded though bubbles.”
That’s called projection.
Wat you wrote is unrelated to emissivity. An efficiency analogy in fact.
Efficiency as I said has a real world basis. The work obtainable from a given energy input. The emissivity SB fudge factor has no physical basis. You are a dill
When we model a real system we develop a set of equations. We make assumptions in those models. The model will have a discrepancy with the real world and we apply an efficiency, coefficient of performance, emissivity, etc., so that the model scales to the real world.
There may or may not be a way to calculate the fudge factor. Sometimes, we use “rules of thumb” or scale something from a similar application.
You’re way out of your depth.
So many words so little substance. The SB fudge factor is derived from measured surface temperature that is then used to calculate surface temperature. Way to go around in circles. It is not obtained from first principles.
This is the kiddies wading pool that you imagine has profound significance. But going around in circles again with a road engineer like you is not on my agenda today. 😁
“Way to go around in circles. It is not obtained from first principles.”
I never said it was.
“But going around in circles again with a road engineer like you is not on my agenda today.”
Really? Trust me. You could never do what I do. You don’t have the intelligence or the skill set. You have already amply demonstrated that.
Franktoo,
in the New equation I do not use the emissivity term.
The New equation is for the planets without-atmosphere mean surface temperature calculation.
Two major principles are newly discovered and been applied in New equation:
1). The Φ(1-a) coupled term for the precise the planet surface “energy in” estimation.
2). The “Planet Surface Rotational Warming Phenomenon”, which states:
Planets’ mean surface temperatures (everything else equals) relate as their (N*cp) products’ sixteenth root.
And New equation “works” for 14 planets and moons in solar system.
https://www.cristos-vournas.com/448752897
In New equation the surface temperature is not uniform, but it is the planet average (mean) surface temperature.
Tmean.planet = [ Φ (1-a) S (β*N*cp)¹∕ ⁴ /4σ ]¹∕ ⁴ (K)
Φ – is the solar irradiation accepting factor (dimensionless)
N – is the planet rotational spin (rotations/day)
cp – is the planet average surface specific heat (cal/gr.oC)
β – is the Solar irradiated Rotating Planet Surface Absorbing-Emitting Universal Law constant (day*gr*oC / rot*cal)
https://www.cristos-vournas.com
I just noticed there is another “problem” with your equation. I guess you use Cp to account for the temperature rise at the surface of the planet, but that is a function of thermal conductivity, which is a measure of the resistance of a mass to heat transfer.
I guess you don’t do much with heat transfer. Bringing in Cp is similar to bringing in viscosity. It has no relevance.
https://en.wikipedia.org/wiki/Thermal_conductivity
Here’s another problem, but probably not a big one. Technically, you should be using Cv which gives you the change in internal energy. Cp gives you the change in enthalpy.
Along that line, I just thought of a another problem. On the earth, the surface is 3/4 water. In terms of surface temperatures water is a completely different animal.
On a planet with a solid surface, the only way solar energy penetrates the surface is by conduction. That’s why thermal conductivity is important. On a liquid surface, with waves and currents solar energy penetrates by forced convection. The liquid water also evaporates which keeps the surface temperature lower. In any event the situation on the earth is a lot more complicated.
I don’t see where you take any of that into account. That could mean the temperature of the earth may be a lot lower than your equation predicts.
Your “theory”, equation, and analysis are full of holes.
JJBraccili
”
I just noticed there is another “problem” with your equation. I guess you use Cp to account for the temperature rise at the surface of the planet, but that is a function of thermal conductivity, which is a measure of the resistance of a mass to heat transfer.”
JJBraccili, thank you for your note.
It is an observed “Planet Surface Rotational Warming Phenomenon”. It states
“Planets’ mean surface temperatures relate (everything else equals) as their (N*cp) products’ sixteenth root.”
(N*cp) appears here as a physics coupled term. N – the rotational spin is what accounts for the solar energy /surface interaction duration.
Cp – the average surface specific heat… cp is a well known and well measured for almost all the materials physics term.
Cp in the (N*cp) coupled term accounts for the amount of atoms and molecules stretched on a unit of solar irradiated surface area.
It is well known, the smaller the atoms and molecules, the higher the specific heat. Thus, for a higher specific heat there would be more atoms and molecules interacting with solar flux…
https://www.cristos-vournas.com
“Cp in the (N*cp) coupled term accounts for the amount of atoms and molecules stretched on a unit of solar irradiated surface area.
That’s molar density — not Cp.
It is well known, the smaller the atoms and molecules, the higher the specific heat. Thus, for a higher specific heat there would be more atoms and molecules interacting with solar flux…”
That’s a world salad that says NOTHING and doesn’t answer the question. Cp has nothing to do with surface temperature. What determines the surface temperature is the thermal conductivity.
Cp plays a role in determining how long it takes to reach steady-state and how the temperature of the planet varies with time reaching steady state. It plays no part in determining the steady-state temperature.
I repeat my question. What is the purpose of Cp in your equation other than it looks good?
You just keep making stuff up as you go along, don’t you? That’s a clear indicator that your theory is junk science.
Isakov Dmitry: Thanks for the correcting my mistake. dW/dT is -3.3 W/m2/K (not W/m2) for a S-B Model with e = 0.61 and T = 288. Forcings – changes in radiation that are independent of temperature (such as 3.5 W/m2 per doubling of CO2) – are measured in W/m2. Feedbacks – changes in radiation that are produced by temperature change (such as Planck feedback = -3.76 W/m2/K for a BB at 255 K) – are always reported in W/m2/K.
Robert: After struggling for a long time to express things properly, I prefer to say:
R = Energy In – Energy Out (where R is the imbalance at the TOA)
R = (1 – α)S – εσT^4
dR/dT = -S*(dα/dT) – 4εσT^3 – (σT^4)*(dε/dT)
dR/dT = SWR feedbacks (cloud and surface albedos)
+ Planck feedback
+ LWR feedbacks (WV, LR and Cloud LWR)
dR/dT = climate feedback parameter (usually symbolized by lambda)
The above equations are always true in the absence of a forcing change. Suppose we start at steady state and the temperature is say 287 K. Imagine instantly doubling CO2. R changes from 0 to F (Forcing). (Some refer to the change in forcing, deltaF.) The warming (deltaT) needed to restore steady state balance between incoming and outgoing radiation is:
F + lambda*deltaT = 0 (imbalance)
deltaT = -F/lambda
Christos: You are still using a “dimensionless Solar Irradiation accepting factor”, which violates a fundamental law of physics – Kirchhoff’s Law – that says absorptivity = emissivity. Since you are working without atmospheres, the difference in temperature between the Earth and Moon is now mostly due to the difference in rotation rate, not the Earth’s atmosphere. And none of your made up physics is ever going to explain Venus.
Fitting parameters and a limited observational data set to a wide variety of possible equations is not how science usually makes real progress. In fact, it is a fundamental weakness with AOGCMs. They rely on parameters that must be tuned. And since these models produce too few marine boundary layer clouds, they must be tuned to produce compensating errors.
I learned an embarrassing lesson about searching for the correct equation by trial and error when my son came home from school with data showing how the maximum load a “bridge” made of dry spaghetti could carry varied with the width of the span. I wanted to show him how science was REALLY done. Inverse and inverse-squared laws both worked about equally well (or poorly depending on how you looked at it). A power law gave an exponent of -1.4. You could even get a good fit to a parabola! Unfortunately the parabola predicted an infinitely long bridge could carry an infinitely heavy load. I was embarrassed, and had to look up the correct answer.
Later I realized that this isn’t how science is really done. We start with a hypothesis! Then we subject that hypothesis to the most rigorous testing possible. We don’t cherry pick a subset of the data (ie leave out Venus), and go looking for a complicated hypothesis with lots of adjustable parameters. In your case, a sensible hypothesis would start with what we know about absorption and emission from solid surfaces and modify that to account for the effect of an atmosphere on outgoing OLR.
The correct hypothesis for how the load a bridge can carry varies with its span is to think in terms of a simple lever arm: force times distance. That turns out to be an inverse law.
“Christos:…If your MODEL doesn’t incorporate important physical processes, it won’t be useful. It isn’t that basic physics is wrong – your MODEL simply doesn’t include all of the physics. AOGCMs use parameters that are tuned to substitute for important physics that occurs on sub-grid scales. AOGCMs can be wrong too.
When you get down to the REAL basics, the S-B equation and Planck’s Law are also MODELS. Planck’s Law is derived ASSUMING radiation is IN THERMODYNAMIC EQUILIBRIUM (by absorption and emission) with the medium through which it is traveling.”
“Christos: You are still using a “dimensionless Solar Irradiation accepting factor”, which violates a fundamental law of physics – Kirchhoff’s Law – that says absorptivity = emissivity. Since you are working without atmospheres, the difference in temperature between the Earth and Moon is now mostly due to the difference in rotation rate, not the Earth’s atmosphere. And none of your made up physics is ever going to explain Venus.
We start with a hypothesis! Then we subject that hypothesis to the most rigorous testing possible. We don’t cherry pick a subset of the data (ie leave out Venus), and go looking for a complicated hypothesis with lots of adjustable parameters. In your case, a sensible hypothesis would start with what we know about absorption and emission from solid surfaces and modify that to account for the effect of an atmosphere on outgoing OLR.”
Franktoo, thank you.
I have not left out Venus. Venus is well calculated too. I do not post the page with Venus, because I am trying to explain the simpler Planet Surface Rotational Warming Phenomenon.
I have prepared a page for Venus, Earth and Titan with atmosphere. Please visit:
Link:
https://www.cristos-vournas.com/446364348
Also you can visit Ron Clutz’s blog “Science Matters”. Ron has prepared a very good synopsis of my work:
Link:
https://rclutz.com/2021/07/21/how-to-calculate-planetary-temperatures/#:~:text=The%20Planet%20Surface%20Rotational%20Warming%20Phenomenon.%20It%20is,planet%20rotates%20faster%20it%20is%20a%20warmer%20planet.
While not exactly on topic, the fact that the earth’s magnetic field is weakening at an accelerating pace never gets any attention. If the 5% decrease per decade keeps up, I think we have a lot more to worry about than a trace gas like CO2.
I’m afraid I have to disagree with Fritz’s latest work. Not with their data, but with their interpretation.
Reflected shortwave radiation, usually termed RSR, has indeed been decreasing since about 2000, as confirmed by an increase in albedo, although not as pronounced as the CERES data:
Goode, P. R., et al. “Earth’s albedo 1998‐2017 as measured from earthshine.” Geophysical Research Letters (2021): e2021GL094888.
However this was after a large decrease in albedo that took place 1995-1998, as albedo used to be larger before 1995 than after 2000.
Goode, P.R. and Palle, E., 2007. Shortwave forcing of the Earth’s climate: Modern and historical variations in the Sun’s irradiance and the Earth’s reflectance. Journal of Atmospheric and Solar-Terrestrial Physics, 69(13), pp.1556-1568.
This decrease was due to a decrease in cloud cover between c. 1987-2000 as figure 5 from this paper shows. Although cloud cover increased from 2000, the ratio changed. Low cloud cover decreased and mid-high cloud cover increased (see figure 5).
The interpretation of these changes is not as straightforward as Fritz & Rolf present. These changes were part of the Great Climatic Shift of 1997-98.
Swanson, K.L. and Tsonis, A.A., 2009. Has the climate recently shifted?. Geophysical Research Letters, 36(6).
To my knowledge this shift was first identified in 2003 by,
Chavez, Francisco P., et al. “From anchovies to sardines and back: multidecadal change in the Pacific Ocean.” science 299.5604 (2003): 217-221.
The main result of this shift was the inauguration of the Pause that still continues. There was no warming between 1998-2013 and between 2016-2021. The only 1st century warming took place during the huge 2014-15 Niño. Quite telling.
Fritz & Rolf get their phase C backwards. Clearly the RSR and cloud changes are not ruling. Dewitte et al., have a very important paper of RSR and total outgoing radiation that Dubal & Varenholt 2021 cite extensively, however they fail to mention that the implications of Dewitte et al., 2019 are just opposite:
Dewitte, S., Clerbaux, N. and Cornelis, J., 2019. Decadal changes of the reflected solar radiation and the earth energy imbalance.
Remote Sens. 2019, 11(6), 663
Their figure 12 shows that RSR would have not really decreased during this period if we disregard the huge effect of 2014-15 El Niño on ToA radiation. They also show that total outgoing radiation (TOR) has been increasing, which is the opposite interpretation to Dubal & Varenholt 2021, besides providing a more satisfactory explanation to the Pause than just heat hiding in the ocean.
https://www.mdpi.com/remotesensing/remotesensing-11-00663/article_deploy/html/images/remotesensing-11-00663-g015.png
That figure shows the same as my temperature time-derivative figure:
https://i.imgur.com/7PksH7H.png
Despite the big El Niño, the 15-yr avg of monthly temperature increase is still decreasing, and clearly it is responding in its sinusoidal component to the Stadium Wave of internal variability, synchronized to the AMO. The long-term increasing trend is a mixture of GHG increase and high solar activity from the Modern Solar Maximum.
Phase C is lack of warming, reduced warming or slight cooling, whatever.
Most of the papers mentioned are open, the rest can be obtained from Google Scholar.
My mistake. I meant decrease in albedo in the second paragraph. See the Goode papers to clarify that point.
You see, Jimmy!
Tamino has come around and recognized that the accelerated melting 1997-2007 was a temporary phenomenon.
No end in sight for Arctic sea-ice. Your web site is safe until at least 2100.
Evening Javier,
Note the continuing downward trend in the final segment.
Don’t count your Arctic chickens just yet. Particularly since the 3 segments have a physical explanation.
Prof. Wadhams will ultimately be proven correct, albeit not as quickly as he originally anticipated!
You are starting to come my way. Now a physical explanation is needed for something that previously only existed in my imagination.
When the 2021-2030 September Arctic sea-ice extent average comes higher than the 2011-2020 average I’ll love to hear the explanation.
It is surprising that after so many years of sea-ice study Tamino and you have so little understanding of the underlying processes.
A rebound in Arctic sea-ice is already baked in the cake when the drivers of the strong decline revert. Your hypothesis has no place for that. Mine does.
Wadhams is pathetic, a clear example of the ignorance of the experts that Feynman mentioned.
Javier,
No I’m not “starting to come [your] way”. The concept of what was dubbed “The Slow Transition” has been under discussion over at the Arctic Sea Ice Forum since 2014:
https://forum.arctic-sea-ice.net/index.php/topic,933.0.html
“Winter ice growth will oppose the factors that have led to strong ice volume loss over past decades. That volume loss is now at an end. We face a relatively slow transition to a seasonally sea ice free state some time late next decade to the 2030s.”
“When the drivers of the strong decline revert”
When do you predict that will happen?
“Wadhams is pathetic, a clear example of the ignorance of the experts that Feynman mentioned”
Peter Wadhams is a very nice man, although I may of course be biased in my opinion. He’s considered to be the world’s leading expert on “waves in ice”, and he was very complementary about my own humble efforts in that field.
Javier,
My detailed response seems to have disappeared. Perhaps it’s in moderation?
In brief, no I am not “coming [your] way”.
And, Peter Wadhams is a very nice man!
P.S. Now it’s back again.
Just a brief glitch in the Matrix?
“transition to a seasonally sea ice free state”
That’s hilarious. You are never going to see a sea-ice free Arctic in your life. Perhaps in 70,000 years during the next interglacial.
Nature will decide when the next shift happens. In 10 years or 20. We don’t know enough about them to be able to predict them. We don’t even know what causes them. They are clearly not in the models.
It is not a question of niceness. It is said that Isaac Newton was not a nice person. Wadhams was wrong and will continue being wrong because he is unable to learn from his mistakes.
Mornin’ Angech,
The latest PIOMAS Arctic sea ice volume data has now been released:
https://GreatWhiteCon.info/2021/10/facts-about-the-arctic-in-october-2021/#Oct-12
Average September 2021 ice volume was about 0.7 sigma above the 1979-2020 trend line.
Jim Hunt, good afternoon (UT). May I help you with a chart of the Arctic SIV September up to 2021 ?
https://i.imgur.com/VlaBZJf.png .
Not a “death spiral” but a hiatus since 2012 with very small variations thereafter. Any thoughts?
Afternoon Frank,
I believe I’ve already outlined and linked to my thoughts and the PSC’s above?
Moi – https://judithcurry.com/2021/10/10/radiative-energy-flux-variations-from-2000-2020/#comment-961243
The PSC September update:
Average September 2021 ice volume was about 0.7 sigma above the 1979-2020 trend line. September ice melt was fairly normal for recent years but the mean ice thickness for September (above 15 cm thickness) was near a record low suggesting that the ice was spread out over a wider area.
Jim, it seems to me ( my chart) that the “transisiton” is a nonlinear issue. It happend between 2005 and 2012 as the 5year rng. sigmas of the september data came to a peak. Thereafter this slowed down ramarkably, see here : https://i.imgur.com/qdUo0ih.png . Hence I question the statement that something is uward or downward of a linear trend line. If an issue is nonlinear in it’s DNA ,as it seems to be, the use of a linear trend makes no sense. One should use a nonlinear trend as I did with a 10years loess lowpass filter or something. Than the illusion that is born by the LOS- trendline, that there is something with a clear continious downward line, is avoided when it comes to the eye of the beholder.
best
Evening Frank,
“A 10years loess lowpass filter or something.”
Or as I may have already mentioned, Tamino’s “three straight-line segments with their changes chosen to best-fit the data, like this”?
https://GreatWhiteCon.info/wp-content/uploads/2021/10/Tamino-3segments.jpg
Mornin’ Angech,
The latest PIOMAS Arctic sea ice volume data has now been released:
https://GreatWhiteCon.info/2021/10/facts-about-the-arctic-in-october-2021/#Oct-12
Morning Jim,
–
And a welcome report at that.
It is one of the few times that volume and extent match 8th overall lowest I think out of 43 years and a welcome relief from the low figures of 2012.
The refreeze id proceeding better than I hoped and the ENSO is still behaving itself so the cooler conditions might persist for a while.
A long way 600,000 Sq K to get back into the middle range but certainly Tamino’s cherry picks are going to be harder to defend.
Afternoon Angech,
What alleged “cherry picks” of Tamino’s might those be then?
Here’s the latest sea ice animation from yours truly:
https://GreatWhiteCon.info/2021/10/facts-about-the-arctic-in-october-2021/#Oct-13
The NSIDC comment:
Despite September total ice extent being high compared to recent years, the amount of multiyear ice as assessed from ice age reached a near-record low, with an extent of only 1.29 million square kilometers (498,000 square miles), just slightly above the value of 1.27 million square kilometers (490,000 square miles) at the end of the 2012 melt season.
“There was no warming between 1998-2013 and between 2016-2021”
Lol. Just too funny.
The trend from 1998-2021 by GISS is 2.25 degrees/ century.
https://www.woodfortrees.org/plot/gistemp/from:1998/to:2021/trend/plot/gistemp/from:1998/to:2021
To describe this as a “Pause that still continues” due to an El Nino, stadium wave and other magick really is a super- special kind of cherry picking. Quite telling indeed.
Start your trend with a heat year including a major El Nino, and then look at only a few years, and you can data mine a short “cooling trend”.
I wish Climate Realists would stop doing this.
I see that “trick” too often.
HadCRUT4
https://www.metoffice.gov.uk/hadobs/hadcrut4/data/current/time_series/HadCRUT.4.6.0.0.annual_ns_avg.txt
1998 0.539
2013 0.514
2016 0.797
2021 0.624
All the increase took place mid 2014-early 2016. The rest is noise.
https://i.imgur.com/Y5LVxLK.png
That’s why the 15-yr velocity of warming is falling.
https://i.imgur.com/7PksH7H.png
“All the increase took place mid 2014-early 2016. The rest is noise.”
Oh, but this is too good.
“When calculating an increase, years of increase must be disregarded”
You’re (in) creasing me up, Javier.
Please continue.
[The trend by Javier’s preferred Hadcrut is 1.5 degrees/ century during this “pause” from his cherry picked 1998. Some pause. ]
“Please continue.”
When in October 2016 I posted my first Arctic sea-ice article explaining how it had entered a new climatic regime there were also a lot of complaints about the statistics, and even Tamino dedicated me an article entitled “extreme cherry ice.” But he only knows a few mathematical tricks and has no understanding of climate. Here we are after 14 years without a significant decline in September Arctic sea-ice extent, and there are more to come. Who’s laughing now?
https://wattsupwiththat.com/2016/10/07/evidence-that-multidecadal- arctic-sea-ice-has-turned-the-corner/
Your basic mathematics and trends can’t explain a thing of climate. It is too complex. The changes of climatic regimes, known as shifts, with the 1976-77 detected in the early 1990s, were defined from the work about the North Pacific by Mantua and Minobe. The last shift took place in 1997-98. Read and learn.
Don’t get me started Javier!
FYI here’s Tamino’s latest Arctic sea ice extent graph:
https://GreatWhiteCon.info/2021/10/facts-about-the-arctic-in-october-2021/
Still no way to embed images here? Ah well:
https://GreatWhiteCon.info/wp-content/uploads/2021/10/Tamino-3segments.jpg
To get at least vaguely back on topic, here too is (albeit invisible) this year’s Arctic albedo warming potential:
https://GreatWhiteCon.info/wp-content/uploads/2021/09/AWP_Cumulative-2021-09-15.png
Oh, Javier, you are good!
To respond to being called out on a risible cherry pick on global temperature, you respond with a cherry pick on Arctic Ice.
Or are you saying there was no particular reason to choose 14 years?
Very impressive, but to cap it off with a reference to WUWT as a source is the icing on the cherry.
Bravo. Encore!!
Piomas The April time series (Fig 8) for both data sets have no apparent trend over the past 11 years.
Afternnon Angech,
And how about the full PIOMAS September timeseries from figure 3?
https://GreatWhiteCon.info/wp-content/uploads/2021/10/PIOMASIceVolumeAprSepCurrent-2021-09.png
Not yet including September 2021.
Pingback: Radiative energy flux variations from 2000 – 2020 – Watts Up With That?
https://countercurrents.org/2021/06/human-population-activity-the-primary-factor-that-has-precipitated-a-climate-emergency-biodiversity-loss-and-environmental-pollution-on-our-watch/
Pingback: Radiative energy flux variations from 2000 – 2020 |
Weaker solar wind states since 1995 have driven a warm AMO (via the NAO/AO), and which has reduced low cloud cover. It’s a self amplified negative feedback with a large overshoot.
“We correlate an overlapping period of earthshine measurements of Earth’s reflectance (from 1999 through mid-2001) with satellite observations of global cloud properties to construct from the latter a proxy measure of Earth’s global shortwave reflectance. This proxy shows a steady decrease in Earth’s reflectance from 1984 to 2000, with a strong climatologically significant drop after 1995.”
http://research.iac.es/galeria/epalle//reprints/Palle_etal_Science_2004.pdf
Pingback: Radiative energy flux variations from 2000 2020 – Watts Up With That? – Adfero News
I think the authors get way out over there skis by claiming that a decrease in cloud cover is causing change.
The articles conclusions are based on data from NASA’s CERES satellites. I think there are 3 of them. Considering the size of the planet, I would say one should be wary of the results.
The albedo effect may be one of the least understood phenomena in climate science because of the lack of data. NASA has or had a project called RAVAN to launch 36 CubeSat satellites to continuously monitor earth’s radiant energy. You can read about it here:
https://directory.eoportal.org/web/eoportal/satellite-missions/r/ravan
The project was supposed to get better data on radiative forcing and the albedo effect. I have no idea about the status of the project.
Hard to believe that as the planet warms you wind up with less cloud cover since the moisture in the atmosphere increases with temperature.
About 10 years ago Roy Spencer published a peer reviewed paper claiming that climate change was being caused by increasing cloud cover. You can read it about it here:
https://www.livescience.com/15293-climate-change-cloud-cover.html
That paper was also published in an online, peer-reviewed, open access journal. Turned out he was wrong. The paper being currently discussed is claiming the same thing but this time less cloud cover is the culprit.
Over the last 20 years solar irradiance has been decreasing — not increasing.
https://climate.nasa.gov/internal_resources/2165/
There is an 11 year solar cycle as well where solar irradiance varies about 1 W/m2. Either or both of these could explain the decrease in short wave solar radiation at TOA.
Here’s a bio of Friz Vahrenholt
https://www.desmog.com/fritz-vahrenholt/
Definitely not someone who can be considered an unbiased source. I couldn’t find anything on Rolf Duabi. He must be new.
For those who think this paper is the silver bullet that will slay consensus climate science, it probably isn’t. BTW there is no cabal of the MTM and climate scientists to conceal the truth. I like conspiracy theories as much as anyone, but a conspiracy that spans decades and generations of climate scientists is hard to swallow.
“Hard to believe that as the planet warms you wind up with less cloud cover since the moisture in the atmosphere increases with temperature.”
Less water vapour condenses in the warmer lower atmosphere?
Increase in annual sunshine hours in the UK since 1995:
https://www.metoffice.gov.uk/pub/data/weather/uk/climate/actualmonthly/17/Sunshine/UK.gif
Nope, if you put more water vapor into the atmosphere it will condense and form more clouds. That may occur higher in the atmosphere because of the higher temperature, but it will condense. It will not build up in the atmosphere.
Lower troposphere specific humidity has increased since 1995 while low cloud cover has declined since then. Get over it.
Higher humidity means higher temperatures in the lower atmosphere — that’s expected. Higher temperatures in the lower atmosphere means cloud formation moves further up in the atmosphere where it is colder. Get over it.
We don’t know much about the albedo effect because we don’t have enough satellites measuring the earth’s IR. NASA needs to launch a bunch of inexpensive cubesat satellites to monitor earth’s radiation. Instead of Congress funding a project that would do just that, they plan to waste billions to land a man on Mars. A photo-op is more important than a project that could help save the world. Think Congress isn’t a hot mess with warped priorities?
I’ve seen 3 theories on this thread saying CO2 isn’t the cause of planetary warming — less cloud cover, planetary spin, and hydrocarbons in the oceans that are interfering with evaporation. To all of those who support any of those theories I have one question. If CO2 is benign, where did all the energy go that CO2 is preventing being radiating into space in this IR spectrograph of earth’s radiant energy:
https://th.bing.com/th/id/R.4c1109c44467935f499d0e0fdba7d026?rik=qPsBByxrFebz%2fw&riu=http%3a%2f%2fwww.xylenepower.com%2fMars_EarthM.gif&ehk=r4PdeNCLINzEnbHMnGxtIheHg0Aj8vuM8kVUpkf%2b1B0%3d&risl=&pid=ImgRaw&r=0
Did the energy fairy eat it? I posed this question several times before. I never got an answer. Until I get a satisfactory answer, all the alternate theories from this thread are nothing more than junk science being peddled by snake oil salesman.
“I’ve seen 3 theories on this thread saying CO2 isn’t the cause of planetary warming — less cloud cover, planetary spin, and hydrocarbons in the oceans that are interfering with evaporation. To all of those who support any of those theories I have one question. If CO2 is benign, where did all the energy go that CO2 is preventing being radiating into space in this IR spectrograph of earth’s radiant energy”
I know I promised to ignore you but just curious.
Previously you demanded me to compare CO2 absorption band on earth’s IR spectrograph to IR spectrograph from water (https://webbook.nist.gov/cgi/cbook.cgi?ID=C7732185&Type=IR-SPEC&Index=1#IR-SPEC)?
I know that you prefer to run away when your stupidity is pointed out but still. Did you try to understand the difference finally?
Why do you always jump between different Earth’s IR spectrographs? Do you see the difference between the one you’ve sent now and the one you gave previously? https://www.giss.nasa.gov/research/briefs/2010_schmidt_05/curve_s.gif
Hint, look at the modeled emissions temperature.
I know that you do not know, but still try to find out the difference between vibrational and translational kinetic energy. Maybe you will see the difference between the overall “black body emission” spectrum and characteristic absorption bands that are independent of temperature. It is basic science but, try, it is not so hard to learn. I’m afraid that without that knowledge your will never understand the meaning behind the data that you are referring to.
JJB
“Higher temperatures in the lower atmosphere means cloud formation moves further up in the atmosphere where it is colder.”
Water vapour hasn’t increased further up.
Doesn’t have to.
Here’s a plot of how water varies with height in the atmosphere:
http://image.slidesharecdn.com/highaltitude-120720141408-phpapp01/95/high-altitude-13-728.jpg?cb=1342793821
See how it falls with altitude and is gone at the top of the troposphere. That’s from water condensation. As the concentration drops, mass transfer will pull the water vapor higher in the atmosphere.
JJ, one of the first things I did when I got interested in this topic was to ask myself how did climate change in the past and changes in ocean heat transport was one of the most common answers. That paper will explain to you why. If you don’t like that one then explore the topic for yourself. There are dozens if not hundreds of papers dating back from decades ago. This isn’t a new idea and it isn’t outdated either as people are still working the topic. I didn’t write them. Experts in the field did.
Everbody has heard that “energy cannot be created or destroyed”. Not many know what that implies.
For long term climate change, the temperature of the earth has to rise. The only way that happens is by raising the amount of energy on the planet. That energy has to come from somewhere. Ocean currents moving the energy from one place to another is not going to raise the amount of energy on the planet. It could change the weather patterns over a wide area, but not over the entire planet. It would also change the weather patterns in another part of the planet and everything would balance out.
“mass transfer will pull the water vapor higher in the atmosphere”
Specific humidity has declined since 1993 at 300mb. Upper clouds have increased slightly, but not as much as low cloud cover has declined.
What’s happening to the increased water vapor? Essentially, no water escapes the troposphere. Is it going directly to rain?
I question your conclusions only because I have no faith in the accuracy of the albedo numbers.
“To all of those who support any of those theories I have one question. If CO2 is benign, where did all the energy go that CO2 is preventing being radiating into space?”
CO2 is not only preventing (reducing) radiation into space, it’s also radiating into space and helping cool the atmosphere. The bulk of the atmosphere (N2 and O2) cannot radiate significantly and need to transfer the heat to CO2, water vapor and clouds so they can radiate into space.
Furthermore, the measured outgoing longwave radiation (OLR) is increasing and is closely following surface temperatures.
https://andthentheresphysics.files.wordpress.com/2020/04/remotesensing-10-01539-g004.png
LOL!!! Looks like you got your degree in science out of a Cracker Jack box.
So everything would balance out? Tell me, if you evenly distributed the warmth of the Earth would the albedo be exactly what it is today? That’s just goofy. Carry on.
Over time, yes. The amount of water vapor in the atmosphere is a function of temperature. As the temperature rises, more water vapor is in the atmosphere. Essentially no water vapor leaves the troposphere. Three things are possible you either get more clouds or you get more rain or you get both.
> That’s just goofy.
See, Dmitry?
That’s another appeal to incredulity.
One day Denizens will have something else in their hands.
Willard, besides decades of literature and plain common sense I guess I have nothing. Don’t ask me for another sandwich.
I’m quite sure I have more experience in contrarian crap than you do, Steven. My common sense tells me that uncertainty increases risks and risks cost money. Yet here we are.
Well then Willard, since you know so much about contrarian crap, perhaps you can be my research assistant for a change. What do you think? Have any published literature that shows ocean heat transport doesn’t change the global mean climate or is all you have smack talk off the top of your head?
Do you know what’s a sammich request, Steven, and what will happen if your High Expectation Father is never met?
“What’s happening to the increased water vapor?”
Less of it proportionally condenses into low cloud and rain during a warm AMO phase. And more water vapour is produced, by the warmer sea surface temperatures reducing low cloud cover which increases sunshine hours, and by the increase in surface wind speeds over the oceans since 1995. And it’s the decline in the solar wind strength since 1995 which is driving the warm AMO phase, so it’s all negative feedbacks.
JJBraccili: Anything of factual contribution? Mostly you discuss the messangers not the message. Such things don’t qualify your comment.
I was commenting on the article. If you want my opinion on the article, I think its cherry-picked scientific nonsense.
Here’s a piece I wrote a few years back on Quora. I dumbed it down for people who have no idea what they are talking about, but insist they understand climate science and feel compelled to demonstrate their ignorance.
https://www.quora.com/If-climate-change-is-a-hoax-why-do-so-many-scientists-say-its-happening/answer/John-Braccili?__nsrc__=4&__snid3__=27399468379
So we know it can’t be solar because solar is on the decline? Tell me when exactly the earth came to equilibrium with the increase in solar in order to support your premise that reducing solar should cause a decline.
If you look at the graph, until about 1960 the earth’s temperature tracks with the changes in solar radiation. Then there is a break. Something has to cause that break. It also has to be something that is increasing. If, whatever it is stops increasing, then the earth’s temperature would stablize and it wouldn’t be increasing. It would then track with the increases and decreases of solar radiation.
The problem with climate skeptics is that few of them have any training in science beyond HS. They read something written by a PhD selling snake oil and latch on to it because that’s what they want to be true. Next, comes the conspiracy theories that claim the MSM and climate scientists have formed a cabal to prevent the “truth” from coming out. It’s all nonsense. I’ll tell you what is true. We are going to reach a point where nothing can be done about our warming problem. It’s a lot closer than you may think.
I think many feel when the time comes we’ll just throw a lot of money at the problem and it will get solved. Kind of like what we did when we decided to go to the moon. That was an engineering feat. This is different. The science is all on the wrong side of this. I’m a chemical engineer. Usually, when posed with a problem there is something that can be done — not with CO2. Everything about this molecule is bad. There always could be a scientific miracle, but scientific miracles are hard to come by and I wouldn’t count on it. All we can do is stop dumping CO2 into the atmosphere and pray that’s enough.
That a long winded way of saying you are clueless as to when the Earth came to equilibrium and so you are also clueless as to if solar is a negative or a positive influence on temperatures?
I assume you are talking to me. It not my fault if you can’t read and understand a chart.
I see you subscribe to one of these idiotic theories about heat transport on the planet having some effect on climate. Let me assure you, it has none. Neither do magnetic fluxes or lava flows or little green men. The only thing that has significant impact on climate is the amount of solar radiation absorbed by the earth and the amount of the earth’s radiation going into space. That’s unless you believe in an energy fairy that can magically create and destroy energy at will.
JJBraccili, yes, I was talking to you. You don’t seem like the type of person that would call the climate models complete garbage but you just did. Dunning-Kruger is strong in you.
JJ, look up “Why ocean heat transport warms the global mean climate” and expand your horizens.
I was asked why I don’t contribute factual information? I have, but my main function these days is to debunk climate denial junk science. Usually, it’s pretty easy. This thread started with a paper that claimed climate change is caused by less cloud cover. Hard to believe that you get less clouds with more water in the atmosphere as temperature rises. The claim is impossible to prove one way or the other. We don’t have enough satellite coverage to do much more than come up with a guesstimate.
Radiative forcing is another number that has a lot of uncertainty. We don’t have enough satellite coverage. Radiative forcing is a small difference between two large numbers. A small error in either of large number is a large error in the radiative forcing.
NASA has a project called RAVAN to put 36 satellites across the globe to measure the earth’s radiant energy. That would vastly improve the albedo numbers. The project claims they will be able to measure radiative forcing to within +- 0.3 W/m2. A number used a lot for radiative forcing is 0.6 W/m2. If that were the measured number, it would have a +- 50% error. Climate change occurs slowly over decades. Small errors in the radiative forcing could lead to wildly different predictions on the effect on climate.
“JJ, look up “Why ocean heat transport warms the global mean climate” and expand your horizens.”
Moving energy from one point on the planet to another impacts weather — not climate. It’s like taking money out of one pocket, putting it into another, and believing you have more money. Trust me. I tried it. It doesn’t work.
JJ,
Look at the way NASA describes the energy budget.
https://www.nasa.gov/feature/langley/what-is-earth-s-energy-budget-five-questions-with-a-guy-who-knows
Thermals are a net loss of 18.4 w/m^2.
Evapotranspiration is a net loss of 86.4 w/m^2
Incoming is 340.4 w/m^2
The greenhouse back radiation is 340.3 w/m^2
Reflected by clouds is 77 w/m^2
Emitted by clouds is 29.9 w/m^2
The energy does not just get moved around, and even if it did it would matter to where. Moving energy from higher temperatures to lower temperatures will raise the average temperature. This is due to the temperature to the 4th power in the equation.
At 86.4 w/m^2 evaporation is about a quarter of the incoming in the budget. This is not an insignificant portion of the budget.
At 77 w/m^2 clouds reflecting energy is a little less that a quarter of the incoming, also not an insignificant portion of the budget.
Emission by clouds is 29.9 w/m^2 which is about 9% of incoming, not as significant, but still somewhat significant.
If the greenhouse 340.3 w/m^2 is responsible for 33 degrees C. Then it stands to reason that evaporation, cloud reflect, and emission are responsible for 8, 7, and 3 degrees C respectively.
Even 3 degrees C is significant when we are talking about trying to attribute less than that of a temperature difference.
I am having real trouble reconciling your statements with the statements of experts on the subject, and frankly basic math. You might want to look at the numbers for a single degree temperature difference (obviously smaller than actual) from one side of the planet to the other. The error in the energy is based on the temperature squared. The math was performed previously on this blog.
The first law of thermodynamics states accumulation of energy = energy in – energy out.
Look at that NASA energy balance. All that matters is the energy incoming from the sun and the energy the earth radiates into space. Everything else balances to zero. It’s just a transfer of energy from one place to another. On NASA’s balance, solar radiation in is 340.4. Subtract out the energy reflected by the surface and the clouds which is 99.9 and you get the total energy absorbed from the sun which is 240.5. The only way energy leaves the planet is by radiation. That figure is the 239.9, the total outgoing IR. We have the total energy in 240.5. We subtract the total energy out 239.9. We get the most important number in the energy balance — the net energy absorbed 0.6. It’s on the lower left of the energy balance in white. It’s also called the radiative forcing. It is the cause of the energy accumulation and climate change. You don’t even mention the three most important numbers in the balance in your analysis. If you sum all the other numbers up, they will sum to 0 and have no impact.
You have the same problem as ID. You think because a number is big it must be important. In this case, the smallest number in the balance is the most important. Anyone who tells you different is no expert.
JJ,
I never said that the small numbers were unimportant. Quite the opposite. However, where the energy is placed on the planet is very important. Movement of energy is very important, and any movement of energy from hot places to cold places will result in an increase in average temperature. Further clouds are important as can be seen from the energy balance. I would agree that we likely do not have enough information to model the clouds, but that is true regardless of which study we are talking about.
You don’t get it. Moving energy around does not create energy. In order for the temperature of the planet and the climate to change energy has to added to the planet. That comes from the imbalance between the energy the earth receives from the sun and what it radiates into space. That’s all there is to it. It’s not complicated. Don’t try to make it complicated.
Why ocean heat transport warms the global mean climate
https://www.gfdl.noaa.gov/bibliography/related_files/ch0501.pdf
No, I get it completely. Changing the albedo (in all models) and changing water vapor (in newer models) is changing the energy budget. I think you could get it if you weren’t so busy already knowing everything despite not knowing everything.
JJ,
Look at the link provided above. OHT is ocean heat transport.
“OHT has a substantial impact on the distribution of sea ice,
clouds, atmospheric water vapour and consequently on the top of
the atmosphere (TOA) radiative fluxes”
I never said that moving energy around changed the total amount of energy. However, it definitely will have an impact on temperature (from the math of the equation involved) and according to the experts above it will have substantial impacts on other things that will result in radiative fluxes at TOA. Which I interpret to mean it has effects on the NASA balance that I referred to earlier.
Thanks Steve for providing the link.
The paper that is the theme of this blog, uses the best information that we have (as far as I know) to look at the effects of clouds on these energy fluxes. If you are aware of better cloud information, please provide us with it.
Ocean currents moving things around is just like air currents moving things around. It moves energy, but doesn’t create energy. Does it impact local weather? Yes! Does it affect global climate? No!
Yeah, at least one model can produce a world from snowball to ice free Earth using today’s forcings and only changing ocean heat transport. That’s a lot of local weather but I suppose you get enough local weather changes and the next thing you know you’ve changed the climate.
DeSmog is a hit-tank.
This is where ad hom is reasonable. Anyone citing them can safely be ignored. Find better sources.
Reassessment and update of long-term trends in downward surface shortwave radiation over Europe (1939–2012):
https://agupubs.onlinelibrary.wiley.com/doi/full/10.1002/2015JD023321
More recent analysis:
Evidence for Clear-Sky Dimming and Brightening in Central Europe
https://agupubs.onlinelibrary.wiley.com/doi/10.1029/2020GL092216
From the abstract:
“Irrespective of the cloud-screening method, strong dimming and brightening tendencies in the atmospheric transmission are evident not only under all-sky but also of similar magnitude under clear-sky conditions, causing multidecadal variations in surface solar radiation on the order of 10 Wm−2. This points to the cloud-free atmosphere as a main responsible for dimming and brightening in central Europe and suggests that these variations are anthropogenically forced rather than of natural origin, with aerosol pollutants as likely major drivers.”
So recent warming is linked to reduction, not increase in high level cloud and water vapour content?
There are elements of this important finding that cohere with what Miscolczi (remember him?) was saying.
http://www.drroyspencer.com/2010/08/comments-on-miskolczi’s-2010-controversial-greenhouse-theory/
For one thing, he also looked at total energy content of air not just temperature (associated with Virial theory) and was roundly ridiculed for it. Now it turns out he was right in this.
Also Miskolczi showed from balloon data as well as modeling that upper atmosphere water content (and thus cloud) would decrease in compensatory response to CO2 increase. This would cancel out the increased opacity of the atmosphere that otherwise would be caused by CO2 increase, and therefore negated any change to the emission height.
Emission height change is the core of the greenhouse argument. It is supposed to result from increased atmosphere opacity to IR from CO2. But a compensatory decrease in high level water vapour would cancel this out. Cancel both the opacity change and the associated emission height change.
So does this mean Miscolczi was right and there is no CO2 radiative greenhouse effect?
Climate/weather is changing due to cloud changes which in turn are caused by the complex system as a whole.
Is this what the authors meant by this paragraph?:
We could prove the increased greenhouse effect of the sum of all greenhouse gases (water vapour, CO2 etc.) under “Clear Sky” conditions with 1.2 W/m² increase in the last 20 years. However, this increase is overcompensated on an area-weighted basis by the increasing radiation of long-wave radiation in the cloudy zones (“Cloudy Areas”) amounting to -1.48 W/m².
It is good to see Philip Goode back in print. Earthshine is an endearing notion. It is conciliant with the CERES record.
‘WASHINGTON—Warming ocean waters have caused a drop in the brightness of the Earth, according to a new study.
Researchers used decades of measurements of earthshine — the light reflected from Earth that illuminates the surface of the Moon — as well as satellite measurements to find that there has been a significant drop in Earth’s reflectance, or albedo, over the past two decades.
The Earth is now reflecting about half a watt less light per square meter than it was 20 years ago, with most of the drop occurring in the last three years of earthshine data, according to the new study in the AGU journal Geophysical Research Letters, which publishes high-impact, short-format reports with immediate implications spanning all Earth and space sciences.’ https://news.agu.org/press-release/earth-is-dimming-due-to-climate-change/
https://agupubs.onlinelibrary.wiley.com/cms/asset/6244ac84-dcb5-4864-b576-24613f35b4bd/grl62955-fig-0003-m.jpg
https://agupubs.onlinelibrary.wiley.com/doi/10.1029/2021GL094888
The dominant source of sea surface warming in the period is ocean and atmospheric circulation in the eastern Pacific. The albedo mechanism involves Rayleigh-Bénard convection over oceans and bistable closed and open cell marine stratocumulus cloud. Closed cells rain out out faster over warm ocean leaving open cells and a reduced domain albedo.
https://earthobservatory.nasa.gov/images/87456/open-and-closed-cells-over-the-pacific
The article reports “a reduction of bright, reflective low-lying clouds”. Do you believe it is a transition from closed cells to open cells?
‘Marine stratocumulus cloud decks forming over dark, subtropical oceans are regarded as the reflectors of the atmosphere.1 The decks of low clouds 1000s of km in scale reflect back to space a significant portion of the direct solar radiation and therefore dramatically increase the local albedo of areas otherwise characterized by dark oceans below.’ https://aip.scitation.org/doi/10.1063/1.4973593
Spencer is very clear on satellite measurement of the energy imbalance by satellite.
Clouds, the very things that Fritz Vahrenholt and Rolf Dubal bang on about render satellite estimation of outgoing IR radiation impossible to quantify accurately.
I repeat
Satellite estimation of outgoing IR radiation is impossible to quantify accurately.
What this means is that there is no true estimate of energy imbalance, if it exists possible.
Worse different people then make theories based on the cloud properties that they wish to use , even though they cannot be accurately assessed for precisely the reasons given and claim that the inaccuracies in the estimations are proof that their theory works.
It is double dipping, select an outcome Gerghis style manipulation of data.
I repeat .
TOA is where energy in matches energy out.
By definition.
It is not a real absolute figure at any stage.
It is a scientific statement and fact.
It can never, by definition, be in imbalance.
Now this causes a few conceptual problems, I agree.
Stored energy like the Chief and Hansen want to use.
The fact is that energy cannot be stored as energy.
It pours into a bucket , it pours out of the bucket.
If you want to store energy you have to deny TOA and SB and the laws of physics.
Energy can be stored. That’s the First Law of Thermodynamics. The stored energy can be depleted or increased. Heat and work are energy being transferred from system to surroundings and increases or decreases the energy of the system and surroundings. Heat and work are energy in motion.
Let’s say the earth is in energy balance and the sun increases it’s radiant energy output by 10%. The earth absorbs that 10% radiant energy but because the temperature of the earth doesn’t rise instantaneously, the earth puts out the same amount of energy as it did before the sun’s radiant energy increases. Now you have an imbalance. If nothing else happens, the earth’s temperature rises until the earth radiates the same amount of energy it receives from the sun. Then the earth is in energy balance and the temperature stops changing. The inertia of the earth to temperature change is what causes the imbalance.
JJBraccili
Entropy is central to the second law of thermodynamics, which states that the entropy of isolated systems left to spontaneous evolution cannot decrease with time, as they always arrive at a state of thermodynamic equilibrium, where the entropy is highest.
ie
A system on its own cannot store heat.
The second law of thermodynamics says nothing about the storage of energy. BTW heat is energy in motion into or out of a system.
The second law of thermodynamics is about the transfer of energy. It says every time you transfer energy the ability of energy to transfer is degraded. Entropy is a measure of the degradation. For example, if you transfer heat into a tank of water you increase the entropy of the water in the tank, but you decease the the entropy of the system where the heat comes from. The SUM of those entropies will be zero or greater than zero, but never negative.
Take the same tank of water and add heat. The temperature of the water will rise. The energy of the water (a state function called internal energy) is higher. If we stop heating the tank and the tank is perfectly insulated, it will stay at the heated temperature indefinitely. If you come along later and remove the same amount of heat, the water temperature will fall to its original value. You have stored the energy from the heat in the water to be removed later.
I will take it further
“Let’s say the earth is in energy balance and the sun increases it’s radiant energy output by 10%. The earth absorbs that 10% radiant energy but because the temperature of the earth doesn’t rise instantaneously, the earth puts out the same amount of energy as it did before the sun’s radiant energy increases.”
You say the temperature of the earth does not increase instantly.
It is true it will take 8 minutes for the extra energy to arrive.
When it arrives the temperature does go up instantly.
How can it do otherwise?
10% extra sun energy arriving 134 W/m2 hitting the earth would be like standing under a meteor suddenly.
The earth doeskin say, oh that’s a lot of heat, better put it in the oceans.
Shallow bodies of water would start to boil. If you were unlucky to be standing outside you would now be in a furnace. The air temperature under the sun would become extremely hot instantaneously.
Its like saying you put a bit of toast in the toaster but don’t worry it takes minutes to heat up.
Just not true.
The surface temperature of the earth directly under the sun would heat up instantly and by the way be radiating all that extra energy back to space straight away.
Here’s where you’re wrong. The earth doesn’t heat up immediately. If you put a pot of water on your stove and turn on the burner and stick a thermometer in is the temperature at the boiling point of water? Don’t be ridiculous.
Actually, the extra heat does mostly wind up in the oceans. The surface of the earth is 3/4 water. Guess what that means?. The lion’s share of the energy absorbed by the earth from the sun is absorbed in the oceans. When you warm water some of it evaporates which lowers the temperature. Ever wonder why a water in a pot boils faster when the pot has a lid? That’s why.
In your scenario, “dark” side of the earth is still radiating energy. That means The “sunny” side of the earth would get would very hot, and the “dark” side of the earth would get very cold. The planet could not support life. We do have a planet in the neighborhood that is exactly like that. It’s called the moon. It has no oceans or atmosphere. We do.
JJBraccili
“In your scenario, “dark” side of the earth is still radiating energy. That means The “sunny” side of the earth would get would very hot, and the “dark” side of the earth would get very cold. The planet could not support life. We do have a planet in the neighborhood that is exactly like that. It’s called the moon. It has no oceans or atmosphere. We do.”
Yes…
There is also the Newly discovered Planet Surface Rotational Warming Phenomenon.
It states:
Planets’ Mean Surface Temperatures relate (everything else equals) according to their (N*cp) products’ sixteenth root.
https://www.cristos-vournas.com
That’s a bunch of baloney.
It’s true that if a planet spins faster the surface temperature where sunlight is incident will be lower allowing it to absorb more heat. The problem with the theory is how much more?
The Stefan-Boltzman gives us how much heat is transferred from the sun to the earth. Heat transferred is proportional T of the sun to the fourth power – T of the earth to the fourth power. T of the sun is 5000 K. I checked what the change would be if the earth’s surface temperature was 288 K and 500 K. The change in heat transferred between the two planets is less than 0.01%. In other words, insignificant.
I think the mistake in this analysis is not taking into account the sun’s temperature and the impact it has on the radiant heat transfer. It is so large, it swamps the impact of the earth’s surface temperature
If this “discovery” had any merit, it would be published in a respectable scientific journal. Not on some random website. Thinking that the spin of the planet has a major impact on climate is, frankly, ridiculous.
JJBraccili
“It’s true that if a planet spins faster the surface temperature where sunlight is incident will be lower allowing it to absorb more heat.”
Good.
“Thinking that the spin of the planet has a major impact on climate is, frankly, ridiculous.”
Yes, the spin of the planet has a major impact on every planet mean surface temperature. I have demonstrated that in many examples in my website pages.
https://www.cristos-vournas.com
In radiant heat transfer the heat transferred is proportional to the temperature of sun to the fourth power minus the temperature of the earth to the fourth power. Where do you take the sun’s temperature into account? You don’t. If you do the calc I suggested, you’ll find out that spin has an insignifcant impact on heat transfer.
You imply greenhouse gases have no impact on the earth’s temperature. There is a mountain of data that says otherwise.
Write up your “theory” and submit to a reputable journal and let it go through a rigorous peer-review. If your so sure you right, It should be no problem.
JJBraccili
“Write up your “theory” and submit to a reputable journal and let it go through a rigorous peer-review. If your so sure you right, It should be no problem.”
Thank you for your advice, I am looking forward to it…
Please visit Ron Clutz’s blog. Ron has devoted three posts in his blog to the Planet Surface Rotational Warming Phenomenon.
Link:
https://rclutz.com/2021/07/21/how-to-calculate-planetary-temperatures/
Please visit:
https://rclutz.com/2021/07/21/how-to-calculate-planetary-temperatures/
I went back and took another look at your website to see if there was anything I missed.
You claim is that your equation calculates the average temperature of a planet without an atmosphere. Your equation calculates the average temperature of the earth is 288 K therefore the standard calculation from the Stefan-Boltzmann equation of 255 K is wrong and there is no greenhouse effect.
I looked at you equation and I see one big, big problem. You define the solar Irradiation accepting factor two different ways. First, you say it’s 1 for a “smooth” planet and 0.47 for a “rough” planet. I don’t understand why solar radiation absorption has anything to do with whether a planet is “smooth” or “rough” planet. What happens if the planet is “semi-rough”? Is it 0.75?
Then you define the factor as the ratio of the area a disk to the surface area of a sphere with the same radius. The ratio is 0.25 — not 0.47. Area of a circle is pi * r**2. Area of a sphere is 4 * pi * r**2. Divide the area of a circle by the area of a sphere and you get 0.25.
I assume what you want “prove” is that CO2 is a benign harmless gas that can’t possibly cause global warming. Take a look at this:
https://geosciencebigpicture.files.wordpress.com/2014/03/curve_s.gif
That graph is an IR spectrograph of the earth’s radiant energy. The blue area is earth’s radiant energy. See the white area under the CO2 label. If CO2 was harmless that area should be blue. The area represents the amount of the earth’s radiant energy CO2 is preventing from escaping the planet. That energy warms the planet.
No other way to say it. You’re theory is wrong. Spin does not have a significant impact on planetary temperature
JJBraccili
“Thinking that the spin of the planet has a major impact on climate is, frankly, ridiculous.”
Certainly, you are trying to fight nonsense, and so a bit of overzealousness is hard to avoid. However, the spin of the planet does impact the climate. At the one extreme of a tidal locked planet the side always facing the sun would be very hot, and the other side very cold. The weather on a planet like this would be extreme as wind would be the result of the differential temperatures. At the other extreme, a planet spinning faster than the earth would not have the differences between temperatures from day to night that we see on the earth. Further, a planet without tilt would not experience winter and summer. Both the spin and tilt therefore, affect climate and the temperature profile of the planet.
You are correct in that the amount of energy reaching the planet would not be affected by spin or tilt.
We have a different definition of climate change. My definition defines climate change as the effects caused by an accumulation of energy on the planet. That only happens if there is an imbalance between what the earth absorbs from the sun and what it radiates into space.
A while ago I got into debate on evaporation. The claim was the climate change was do to the destruction of vegetation which cut transpiration. In other words we lose evaporation from plants which cool the planet. Besides the fact that the whole idea is laughable it makes an important point. Let’s say the premise is true. Water evaporates at the surface. This does cause cooling at the surface. The water vapor rises into the atmosphere where it condenses and releases the same amount of energy it absorbed. Net impact on climate change is zero. You can say that about any other process where energy does not escape the earth. Weather, heat traveling to the poles, etc. have no impact on climate change because it has no impact on on energy accumulation on the planet. All the alternate theories that rely on energy transfer on the planet are BS.
Actually, climate can change without changing the energy in, the energy accumulation, or the energy out. Raising the temperature by an amount at the poles will not result in an equal amount of temperature loss at the equator, all other things remaining equal. This is due to the T^4 factor in the energy equation. Further, a change in albedo will affect the energy for the planet. For instance, replacing grass with asphalt, or coating snow with soot.
Do you attribute pre-historic climate change to accumulations of energy?
How do you propose to raise the temperature at the poles? If your talking about energy transfer from somewhere on the planet, all that does is take energy from somewhere else. Net energy change is zero. You warm part of the planet and cool another part. That will not change climate. If your talking about absorbing more energy from the sun, that will change climate.
Changing the albedo effects the absorption of energy by the planet. You are changing energy in.
Climate change, as I define it, is due an energy imbalance, but not necessarily CO2 or greenhouse gases. The sun irradiance was weaker in prehistoric times because irradiance increases as a sun ages. We know very little about the sun and we have no data on how it behaved in the distant past. Volcanic activity can have an impact as well. That’s why you can’t look at CO2 levels in prehistoric times and equate it to what we are seeing now to try to discredit climate science. You must know the state of all things that can impact climate.
JJBraccili | October 11, 2021 at 7:06 pm |
“”We have a different definition of climate change. My definition defines climate change as the effects caused by an accumulation of energy on the planet. That only happens if there is an imbalance between what the earth absorbs from the sun and what it radiates into space.”
JJ Climate refers to the weather where you are on a daily, annual and multidecadal basis.
As such changes in orbital inclination with the same energy input would cause a different climate.
This demonstrates that it is not just the energy in or the change in energy that is important, Other local factors like clouds, ocean circulations, mountain degradation affecting wind flow, deforestation and irrigation and damming affect climate.
What atandb said.
The climate is changing all the time.
Due to varying albedo from clouds and other factors and distance from the sun and sun output.
Hence there is no time of climate normality.
You only refer to an positive imbalance. Both increase and decreases would cause climate change.
Finally according to physics by definition there can be no energy imbalance. Higher energy in equals higher energy out..
You’re talking about weather. In a previous post I provide a link to post I made on Quora to explain the scientific basis behind climate change. There is a graph in that post the plots the number of all extreme weather events around the world year by year from 1980. The graph goes up and down but the trend is up and looks like it will go exponential. The only way that happens is with an accumulation of energy on the planet.
Weather is always changing. Climate change is a permanent long term change.
I only talked about positive energy imbalances because that what we are experiencing now. Otherwise, the temperature would be decreasing.
Energy in = energy out only if the system is at steady state. Systems do not have to be at steady state and in reality they only approach steady state. I already gave the example of what would happen if the sun would suddenly increase it’s output. The temperature of the earth wouldn’t rise instantaneously. It would slowly rise to the steady state temperature where energy in = energy out. That’s exactly what it is currently doing. If we stopped increasing the CO2 in the atmosphere the temperature would begin to stablize (the temperature vs time curve would flatten out) until the temperature of the planet reaches the point where energy in = energy out.
JJBraccili
“Energy can be stored. That’s the First Law of Thermodynamics. ”
The first law, also known as Law of Conservation of Energy, states that energy cannot be created or destroyed in an isolated system.
I do not see the word stored there, do you?
In fact if you built up a store of energy that would have to be creating it.
It’s a bit heavy but basically you have energy and mass that coexist in the universe and while they are convertible when we speak about energy entering and leaving a system or being stored in a system we are not talking about the breakdown of matter into energy.
Right?
Now energy is actually motion. Matter is non motion.
No matter if the matter is traveling at 9/10ths the speed of light on its own it has no extra energy. If it absorbs some energy it re-emits it, it cannot store it. It is not hotter ie containing more energy than if it were standing still.
It does not have a storage bank or battery, it is quite happy sitting in its low entropy state unless acted upon by an outside force [energy or a collision [matter].
“The second law of thermodynamics says nothing about the storage of energy.
The second law of thermodynamics is about the transfer of energy.”
The second law of thermodynamics states that the entropy of any isolated system always increases.
It seems you have contradicted yourself. The law means that a molecule, on its own has no battery, no energy and definitely no storage .
Take the same tank of water and add heat. The temperature of the water will rise. The energy of the water (a state function called internal energy) is higher. If we stop heating the tank and the tank is perfectly insulated, it will stay at the heated temperature indefinitely.
The superman example. or the impossible example.
If we specify the heat cannot get out then the heat cannot get out?
There is no point in providing impossible examples.
The whole point about entropy is that it increases with time which means that water tanks, no matter how well insulated, will lose energy to the surroundings and cannot ever stay at the same temperature indefinitely.
That is the point of the second law.
There is no place to store energy in a system.
Without a heat or energy source it will always lose energy.
The system itself cannot ever retain or store heat.
You have done that by altering the rules to make it an enclosed system.
Sure the heat loss from part of that system is slow but remember in putting that heat in the system loses more energy to its surrounds There is no gain or storage of energy in the new bigger system.
Just creating a fudge factor for one part [like the atmosphere] does not mean any energy is actually retained in the system.
Thank you for the opportunity to try to get this concept across. The chief has told me it is wrong so I am obviously waiting for someone to point out the flaws in this simple argument in a way that I can see.
You have on idea what you are talking about.
The First Law of Thermodynamics say the the total amount of energy in the universe is fixed and energy cannot be created or destroyed only transferred.
The Second Law of Thermodynamics says that every time you transfer energy, you degrade the ability to transfer that energy again.
At the end of the life of the universe all the original energy will still be there, but you will not be able to transfer energy because everything in the universe will be very close to absolute zero.
Energy is a state function. You set the state of matter by fixing its temperature, pressure, and composition. That amount of energy that matter contains at that state is fixed. You increase the temperature of matter by adding heat. The amount of heat added increases the energy of the matter by the amount of heat added. The matter is at a new increased energy state as indicated by the higher temperature. If the matter is water in a tank and I perfectly insulate the tank so no heat can escape. The tank can maintain its new state FOREVER. Stopping talking about the Second Law. It has NOTHING to do with this.
Now I put a heat exchanger in the tank and run through it water that is colder than the water in the tank. I run enough cold water through the exchanger to return the water in the tank to its original state (temperature). The exact of amount of heat I originally added is extracted. The Second Law has NOTHING to do with this. I STORED energy in the water by heating and I extracted the same amount of energy by cooling.
Here’s where the Second Law comes in. The cooling water temperature must be lower than the water temperature in the tank to transfer the energy from the water in the tank. If I calculate the change in entropy of the water in the tank it will be negative because I’m taking heat out of the water in the tank. If I calculate the change in entropy of the cooling water it will be positive because heat is being added to the cooling water. The Second Law requires when I add the entropy change of the water in the tank to the entropy change of the cooling water the sum must be >0. I have degraded the ability of the the energy I exchanged to be transferred again. That means that if I want to transfer energy from the cooling water to somewhere else, the medium I use must be at a colder than the cooling water. Every time I transfer the same energy the cooling medium temperature must be lower.
That’s the best I can explain it. You shouldn’t get discouraged. Very few engineers and scientists who take courses in thermodynamics understand it. That because the instructors don’t understand it. It’s taught as a survey course — all equations which they don’t derive and no context. I became fluent in it because I had to. I went back to the beginning and went through it concept by concept. It took a while.
JJBraccili
You are incorrect. There is no net change in the enrgy of the earth at all. Only energy transfer from one subsystem to another. From the upper atmosphere to surface. Transpiration cools the surface and warms the atmosphere. Deforstation does the opposite. At least 35% of this warming is deforestation. See my published papers under my name Nabil Swedan.
Your right about evaporation having no impact on earth’s energy balance. Deforestation has an impact because less CO2 is removed from the atmosphere.
Climate change is about how much of the sun’s radiant energy the earth absorbs and how much energy the earth radiates into space. Right now there is an imbalance caused by CO2 interfering with earth’s radiant energy. As long as the imbalance exists the earth will continue to accumulate energy and climate change will continue.
Read what I posted on Quora about the subject:
https://www.quora.com/If-climate-change-is-a-hoax-why-do-so-many-scientists-say-its-happening?top_ans=155488291
Earth’s atmosphere doesn’t play any significant role in the slow rise of surface temperatures.
The rise in temperatures is caused by the very slow orbital changes.
https://www.cristos-vournas.com
Let’s go back to that equation of yours. It’s a modified Stefan-Boltzmann equation. The standard Stefan-Boltzmann J = K*T**4. You used the modified form for solar irradiance J = K*T**4 / 4 to take into account the spherical surface of the earth. J would have units of watts/m2 with the appropriate K.
Your equation takes that equation and adds some variable and constants. I don’t know what the “Rotating Planet Surface Solar Irradiation Absorbing-Emitting Universal Law constant”. I looked it up and there is no such constant. The other constant is the solar Irradiation accepting factor. You define that factor as a correction for the spherical shape of the earth. You already corrected for that. That constant looks like a fudge factor to fit the data.
You used Mercury, Earth, the Moon, and Mars to verify your equations. There is one planet missing. That planet is Venus. Is there a reason you left that planet out? It wouldn’t be that it destroys your theory? You claim is that CO2 in the atmosphere has no impact on planetary temperature. It’s all about spin. Venus has an albedo of 0.9. The temperature of the planet should be 60 deg C. The actual temperature is 460 deg C. Can you explain that based on planetary spin?
The equation used for radiant heat transfer is q/A = k * (Th**4 – Tc**4). The temperature of the sun is 5000K. As I pointed out, variation of the temperature on the surface of the earth with spin is not larger enough to signficantly effect radiant heat transfer. No comments?
So what did you do? Did you use the solar Irradiation accepting factor to match the temperature you wanted on the earth and then vary the Cp of the other planets to match their data? You don’t show what you use for Cp for the other planets. Only for the earth.
This theory looks like junk science to me.
“Earth’s atmosphere doesn’t play any significant role in the slow rise of surface temperatures.
The rise in temperatures is caused by the very slow orbital changes.”
Nonsense! Orbital changes that cause temperature rise would show up as an increase in solar irradiance. Solar irradiance has been flat or declining for the past 40 years as planetary temperature has risen.
https://climate.nasa.gov/internal_resources/1802/
JJBraccili
“The equation used for radiant heat transfer is q/A = k * (Th**4 – Tc**4). The temperature of the sun is 5000K. As I pointed out, variation of the temperature on the surface of the earth with spin is not larger enough to significantly effect radiant heat transfer. No comments?”
The equation used for radiant heat transfer q/A = k * (Th**4 – Tc**4) cannotbe applied in the case of sun – planet radiative energy transfer.
The equation is correct for two parallel and having the same dimensions (a * b) flat plates. The distance between plates (c) should be very much less than plates’ dimensions.
c <<< a
and
c <<< b
https://www.cristos-vournas.com
That’s not true. Here’s why.
If there is not some form of a (Th – Tc) in a heat transfer equation it is possible to violate the Second Law of Thermodynamic which requires net heat to flow from the hot body to the cold body.
How do we determine the temperature of the sun. The sun, as all planets, behaves like a black body. In black body radiation theory the energy profile of a blackbody is unique at each temperature. All you have to do is to find the black body energy profile that matches the energy profile of the sun and you have the sun’s temperature.
Let’s do a thought experiment. Let’s put a planet about the same size as the sun in proximity of the sun. Let’s insulate the planet so that no energy escapes the planet except form the area facing the sun. Now let the two bodies exchange energy. What happens. The sun is hotter so the planet begins to warm. When does the warming stop? When the temperature of the planet is the same as the temperature of the sun? Yes, but it actually is when the planet’s energy profile matches the sun’s profile. Then the planet is radiating to the sun the same energy it is absorbing. The Second Law of Thermodynamic is valid for radiant heat transfer.
Let look at the situation of radiation from the sun to the earth. The sun is 93 million miles away. How can the temperature of the sun possible have an impact on heat transfer from the earth? It can because even though the radiation from the sun is less intense, it has the same energy profile. It doesn’t matter how far away the sun is. Postulate a sun at 5000 K close to the earth that has a small enough heat transfer area it radiates to the earth the same amount of energy that the earth is current absorbing. The driving force is (Th**4 – Tc**4) and changes in Tc are not going to have much impact on the heat transfer.
You have another problem. I posted a few times a graph that shows the temperature of the earth is rising and solar irradiation is falling. According to you, greenhouse gases have no impact on the earth’s temperature. It’s the rotational velocity of the planet. That means the rotational velocity of the earth must be slowly increasing. I don’t think that happening. Last time I checked the length of a day is still 24 hours.
JJBraccili,
Sun and Earth are very much away from each other. Sun is the source of radiative energy, Earth is a receiver of Sun’s radiative energy, as every other planet is.
The sun’s radiative energy intensity incident on a planet surface is called solar flux (S). It is measured in W/m².
The sun’s radiative energy intensity on the top of Earth’s atmosphere (TOA) is So = 1,362 W/m². It is called solar constant.
Earth’s average surface (mean) temperature slowly rises due to the orbital changes. It has nothing to do with the Earth’s rotational spin.
https://www.cristos-vournas.com
As I said, It doesn’t make a difference how far apart they are the sun’s energy profile in the radiant energy incident on the earth is the same. The driving temperature is equivalent to 5000K.
The idea that orbital changes are causing the climate change we are seeing is laughable. Those occur over thousands of years. What we’re seeing occurred over less than 100. I guess orbital changes explain what’s happening on Venus? LOL!
Come up with better theories.
JJBraccili
“I don’t know what the “Rotating Planet Surface Solar Irradiation Absorbing-Emitting Universal Law constant”. I looked it up and there is no such constant.”
It is a New universal law constant, that is why it is not being published yet.
JJBraccili, you have already visited my website’s home page. I have developed many more other pages that explain everything about the New equation’s terms.
It is all in the details… To view other pages – Please click on the box at the top.
https://www.cristos-vournas.com
I don’t have the time to go through all of that. I took a look at some of it. Here’s what I think.
1. Your correction for spherical planets is wrong. You use 0.47 the actual correction is 0.25. It’s already done when you divide the Stephan-Boltzmann equation by 4.
2. What happens when solar radiation is incident on the planet surface is that the radiation is converted into kinetic energy. That causes causes the surface temperature to rise. Without an atmosphere that kinetic energy raises the surface temperature and conducts heat into the planet. That is a classic heat transfer by conduction problem. That requires the thermal conductivity. In a planet with an atmosphere you also have convection to the atmosphere.
3. You came up with a 258 K temperature for Venus. That’s impossible no matter how fast the planet spins. That’s about the same as earth’s temperature. Venus is much closer to the sun. Without an atmosphere the temperature is around 60 C or 333 K.
4. You change constants and variables around for unknown reasons. It looks like you’re trying to make the equation fit.
I don’t see this as the magic bullet that is going to kill climate science, but you can make money on it. In Europe an organization called Global Warming Policy Foundation (GWPF) traffics in climate denial science. In the US the Heartland Institute is similar. Both organizations are well funded by fossil fuel interests.
If you clean up your presentations — by that I mean give more context and more guidance on how you come up the input data — one or both might be interested. I don’t think your material could be published in a mainstream climate science journal, but you could try one of the online journals. There were a couple of “journals” in China that were pay to publish. If you pay them, they’ll publish anything and claim it was peer reviewed. I don’t know if they’re still around.
Willie Soon became a millionaire by being paid to publish papers refuting climate science. He goes around claiming he’s an astrophysicist. The truth is he’s an aeronautical engineer. He claimed that climate change was due to sun spots and solar flares. He’s not in the paper scam business anymore because he was exposed. Now he goes around being paid by the Heartland Institute to give seminars on his “theories”.
Dear Dmitry,
No need for all that shadowboxing.
All you need is to support your evaluation of the 0.00001% figure with something else than personal incredulity. Yet you failed to do that so far. And that’s the only thing I asked.
Since you’re new here, you might like:
https://scienceofdoom.com/2009/11/28/co2-an-insignificant-trace-gas-part-one/
And if you had no problem with comprehension you would see the justification for 0.00001% number. But you seem to be oblivious to written texts. But just for your benefit I will repeat.
Let’s use the glossary from IPCC’s website. Global warming is ” the estimated increase in global mean surface temperature (GMST) averaged over a 30-year period, or the 30-year period centered on a particular year or decade, expressed relative to pre-industrial levels unless otherwise specified”.
Now what is GMST: “Estimated global average of near-surface air temperatures over land and sea-ice, and sea surface temperatures over ice-free ocean regions, with changes normally expressed as departures from a value over a specified reference period. When estimating changes in GMST, near-surface air temperature over both land and oceans are also used”.
So after we clear definitions let’s assess Global Warming as a proxy for climate change. So IPCC tells us that the change in GMST over the last 100 years is 1.5C. Let’s estimate the heat gain in the near-surface air temperature (While IPPC is not clear on what they mean by near-surface, 2006 US governmental report on climate gives a table where near surface is confined to 25 m).
We know the surface area of the planet (510 million km2). We know density (1.2 kg/m3) and heat capacity (1 kJ/kgK) of air. So we can estimate the heat accumulated in those layers over 100 years: 2^19 Joules for near-surface air. This number will mean more if we have a reference to compare it to. And we have this reference, HOURLY energy input from the Sun is estimated at 4.8*10^20 Joules. 100 years is 876000 hours, so our total input is 4*10^26. So the total heat build up that we are supposed to worry about is >10^7 times smaller than the energy received by Earth in the same period of time.
Now, stop behaving like a spoiled child. And engage in an adalt conversation.
> you would see the justification for 0.00001% number
I could not care less about how you calculated that number, dear Dmitry.
What I care about is how you come to the conclusion that his must imply that CO2 is insignificant in the grand scheme of how our planet is retaining more energy than it loses.
Willard,
It doesn’t matter for science what you care or not care about or what you belive and not belive in. But it does show the lack of rational through that is common trait of religious zealots. And we established that you are.
For the question of scientific debate the key is that any credible theory should not have self-contradicitng aspects in it. IPCC insists that global warming is caused by increse of CO2 concentration. They also explain it using disbalance in heat fluxes in the atmosphere, supposedly due to CO2 GHG effect. This disbalance leads to increase of heat at the surfa e of the planet. And all I did is taken their definition of Global warming given by IPCC and calculated how much heat is stored according to their definition at the surface of the planet. And that value is just 0.00001% of total energy supplied to the planet by Sun Radiation. However, based on their heat flux imaginary model the ration is >1%. Both cannot be right. So if you cannot find where my calculations are wrong than “imaginary model” with heat fluxes is flawed.
As second step I offer the solution based on latent heat flux (which IPCC Grossly miscalculated) that can remove the discrepancy. But if latent heat flux due to water vapour is the primary heat balancing mechanism, there is little room for CO2 effect. C02 is just a fine tuning mechanisms for the climate, not a driver.
Dmitry,
Once again you’re just saying.
That you find something incredible to believe does not imply it’s inconsistent.
Get real.
Climate is an emergent property of shifts in patterns of spatiotemporal chaos. Planetary energy out is always playing catchup.
e.g. https://pielkeclimatesci.wordpress.com/2011/03/07/a-new-view-of-the-climate-system-involving-spatio-temporal-chaos/
It’s not a brand new idea – it is based on the fractal field theory of fluid dynamics.
I repeat Spencer has said, I presume along with a lot of others
“Satellite estimation of outgoing IR radiation is impossible to quantify accurately”.
Can anyone here dispute this fact, go for it.
If not any discussion of cloud effects cannot make a comment on energy imbalance, agreed?
It is logical to presume that changes in Earth’s albedo are due to increases and decreases in low cloud cover…
https://evilincandescentbulb.wordpress.com/about/
The causes of global warming are not relevant for informing policy or actions. What is relevant is the impacts of global warming.
Empirical evidence shows that global warming is beneficial for all impact sectors except sea level change, for which the impacts are negligible.
Therefore, we should welcome global warming and do nothing to try to prevent or reduce it. It is beneficial, not harmful, for the world economy, human wellbeing and ecosystems.
For more, see my eight comments on the previous thread. The first one is here: https://judithcurry.com/2021/10/06/ipcc-ar6-breaking-the-hegemony-of-global-climate-models/#comment-960851
There are sound reasons to replace fossil fuels with nuclear power. But the reasons are because of the health impacts of burning fossil fuels, not the CO2 emissions.
:ang (2017) ‘Nuclear Power Learning and Deployment Rates; Disruption and Global Benefits Forgone’ https://doi.org/10.3390/en10122169
Lang and Gregory (2019) ‘Economic Impact of Energy Consumption Change Caused by Global Warming’ https://doi.org/10.3390/en12183575
The planet is in constant change in which the interaction of subsystems – ocean and atmospheric circulation, cloud, ice, biology, volcanoes, dust… – drive emergent climate states that modulate energy in and energy out at all scales in accordance with internal dynamics. The planet warms or cools and the negative Planck feedback kicks in limiting change to the more or less extreme and abrupt. The 2021 Nobel Prize for physics draws attention to the complex dynamical climate system – but there is little confidence that science yet knows its arse from its elbow is predicting outcomes of the anthropogenic experiment underway.
Lucky we can build advanced nuclear engines.
https://watertechbyrie.files.wordpress.com/2016/06/em2-summary-e1514320391410.png
And grow more cows.
When solar irradiated, planet’s surface always has a certain the energy
Emission /Accumulation ratio.
It happens so because those are different mechanism energy transfer processes.
When solar irradiation interacting with the planet’s surface there are two different physics phenomena take place.
The by the surface instant IR emission and by the surface heat accumulation (conduction).
And it is observed that when the surface’s temperature is higher, everything equals, the
Emission /Accumulation ratio is higher.
Consequently when rotating slower and having a lower cp the planet’s surface gets hotter and the planet’s surface emits more and accumulates less.
And the opposite, It is observed that when the surface’s temperature is lower, everything equals, the
Emission /Accumulation ratio is lower.
Consequently when rotating faster and having a higher cp the planet’s surface warms less and the planet’s surface emits less and accumulates more.
Thus in this simple example we have illustrated that when a planet’s surface gets warmed at higher temperatures, everything equals, the energy
Emission /Accumulation ratio is higher.
The planet’s surface accumulates less.
And when a planet’s surface gets warmed at lower temperatures, everything equals, the energy
Emission /Accumulation ratio is lower.
The planet’s surface accumulates more.
That is why sea accumulates much more heat than land.
That is why, when we have Earth and Moon having the same solar flux of So = 1361 W/m² Moon rotating slower and having a lower cp, at daytime is getting hotter and having a higher the energy
Emission /Accumulation ratio.
So Moon’s surface accumulates less.
Earth rotating faster and having a higher cp, at daytime getting less warm and having a lower the energy
Emission /Accumulation ratio.
So Earth’s surface accumulates more.
https://www.cristos-vournas.com
That’s right, just as air mixes, water under the ocean surface mixes, e.g., by ocean currents or seismic activity under the ocean floor (tsunami).
http://www.bom.gov.au/archive/oceanography/ocean_anals/IDYOC007/IDYOC007.202110.gif
Good association – turbulence!
Thank you!
https://www.cristos-vournas.com
Currently when the solar wind hits the Earth after the M1.6 flare the El Niño indices will drop quickly.
Each stronger solar wind impact adds wind energy.
https://www.tropicaltidbits.com/analysis/ocean/nino3.png
Two recent posts from The Climate Study Group:
The Great Climate Furphy
https://climatechangethefacts.org.au/2021/09/24/the-great-climate-furphy/
How the IPCC Buries Evidence of the Sun’s Climate Influence
https://climatechangethefacts.org.au/2021/10/06/how-the-ipcc-buries-evidence-of-the-suns-climate-influence/
https://climatechangethefacts.org.au/wp-content/uploads/2021/09/CSG-advertisment-The-Australian-240921.jpg
Warming due to sw radiation from changes in clouds is what you’d expect from a change in poleward ocean heat transport. No surprise at all that it lines up well with positive phases of the AMO.
Bingo. You do understand it.
Stratospheric intrusion reaches California. Overnight, temperatures will drop dramatically across the western US.
https://i.ibb.co/M6SYXTv/gfs-T2ma-us-1.png
This is the forecast for 54 hours.
https://i.ibb.co/QKmNc6H/gfs-T2ma-us-10.png
A snowstorm is approaching Las Vegas.
In an era of high galactic radiation, the protection of the geomagnetic field over North America is weakening.
http://www.geomag.bgs.ac.uk/images/charts/jpg/polar_n_df.jpg
http://www.geomag.bgs.ac.uk/data_service/models_compass/polarnorth.html
Pingback: Prof. Jyrki Kauppiselle tukea, mutta… | Roskasaitti
I have read every comment
and my conclusion is:
Climate science is not settled.
My climate prediction from 1997,
however, remains 100% accurate:
“The climate will get warmer,
unless it gets colder.”
You could predict exactly the opposite and still be right. Wonderful!
How far south will the current stratospheric intrusion in western North America reach? The air contained beneath the wave from the stratosphere does not mix with the surrounding air.
https://i.ibb.co/93CLqYL/gfs-o3mr-150-NA-f024.png
From GWPF:
Failure of Net Zero policy ‘virtually certain’, senior engineer warns
Press Release
London, 11 October – Government plans to decarbonise the economy by 2050 are set for failure. That’s according to eminent engineer Professor Gautam Kalghatgi, who warns that politicians seem blind to the sheer scale of the project to which they have committed the country.
Professor Kalghatgi’s views are set out in a new briefing paper published by the Global Warming Policy Foundation
https://www.thegwpf.org/failure-of-net-zero-policy-virtually-certain-senior-engineer-warns/
In it, he outlines the scope of the changes that will be required for full decarbonisation, looking at the energy required to run the economy, and the resources required to do so without fossil fuels. He finds that the Net Zero project is beset by wishful thinking, bad advice, and misrepresentation of the scope of the task.
He calls instead for an honest assessment of renewables technologies, and a new focus on adaptation to climate change.
Professor Kalghatgi said:
“Nobody in Westminster seems aware of just how much we depend on fossil fuels. Do they seriously think we can switch the entire economy to wind power, simply because they say so? Without any means of storing electricity in bulk? This utopian plan is almost certain to fail.”
Gautam Kalghatgi: Scoping Net Zero (pdf)
About the author
Gautam Kalghatgi is a fellow of the Royal Academy of Engineering, the Institute of Mechanical Engineers and the Society of Automotive Engineers. He has been a visiting professor at Oxford University, Imperial College, Sheffield University, KTH Stockholm and TU Eindhoven. He has 39 years of experience in combustion, fuels, engine and energy research; 31 years with Shell and 8 years with Saudi Aramco.
From GWPF:
Welcome to Net Zero Watch.
“As the energy crisis in Britain and Europe worsens, it is becoming ever more evident that current climate and energy policies are failing, and the public is paying the price.
Net Zero Watch is here to provide serious analysis of naïve and un-costed decarbonisation policies.
Our new campaign and website will shake the tree; scrutinising policies, establishing what they really cost, determining who will be forced to pay, and exploring affordable alternatives.
At Net Zero Watch, readers (and subscribers to our newsletter) will be able to examine the full spectrum of views and critical analysis, enabling our readers to access a credible reality check of official and alternative climate and energy policy research.
Following in the footsteps of the Global Warming Policy Forum, we will highlight the serious economic, societal and geopolitical impacts of poorly-considered policies, both domestically and internationally.
At the centre of our focus stands the energy crisis. … ”
Continue reading here:
https://mailchi.mp/5e3c82f049aa/welcome-to-net-zero-watch-184186
The Niño 3.4 index drops rapidly during a strong geomagnetic storm.
https://www.tropicaltidbits.com/analysis/ocean/nino34.png
https://i.ibb.co/QC9dVzw/planetary-k-index.gif
The graphic below is updated daily and shows that right now the Peruvian Current is very cold.
https://coralreefwatch.noaa.gov/data_current/5km/v3.1_op/daily/png/ct5km_ssta_v3.1_west_current.png
I have a genuine question about IPCC definitions on Global Warming.
I wonder if anyone here can explain to me the issue of orders of magnitude in perceived stored heat or explain where my argument is incorrect.
I use the glossary from IPCC’s website. Global warming is ” the estimated increase in global mean surface temperature (GMST) averaged over a 30-year period, or the 30-year period centered on a particular year or decade, expressed relative to pre-industrial levels unless otherwise specified”.
Now what is GMST: “Estimated global average of near-surface air temperatures over land and sea-ice, and sea surface temperatures over ice-free ocean regions, with changes normally expressed as departures from a value over a specified reference period. When estimating changes in GMST, near-surface air temperature over both land and oceans are also used”.
So after we clear definitions let’s assess Global Warming as a proxy for climate change. So IPCC tells us that the change in GMST over the last 100 years is 1.5C. Let’s estimate the heat gain in the near-surface air temperature (While IPPC is not clear on what they mean by near-surface, 2006 US governmental report on climate gives a table where near surfaec is confined to 25 m).
We know the surface area of the planet (510 million km2). We know density (1.2 kg/m3) and heat capacity (1 kJ/kgK) of air. So we can estimate the heat accumulated in those layers over 100 years: 2^19 Joules for near-surface air. This number will mean more if we have a reference to compare it to. And we have this reference, HOURLY energy input from the Sun is estimated at 4.8*10^20 Joules. 100 years is 876000 hours, so our total input is 4*10^26. So the total heat build up that we are supposed to worry about is >10^7 times smaller than the energy received by Earth in the same period of time. This doesn’t make sense. This does not seem like a value critical for upsetting all climate phenomena on Earth and for support of life on it. But of course we can choose the notion that “flap of the butterfly wings in Brazil can indeed cause tornadoes in Texas”.
To counter this argument I was told by one of the consensus scientists (yes, I tried talking to them) that a large portion of the excess heat is stored in the ocean and not in the atmosphere. Which is true. But first of all IPCC’s Global Warming (which is linked to CO2 emissions) is only talking about near-surface air temperature (GMST) that represents only sensible heat stored in that air layer and thus, it is unfair to move the goal posts in a discussion. Second, let’s look at the energy stored in the ocean. I take data from Ocean heat content – Wikipedia. From 1980 heat content of the top 2000 m of the ocean increased by 2.5*10^23 Joules. Not a small value, indeed. But this is 40 years or roughly 350,000 hours. Total value of heat supplied to Earth during that period of time is 1.3*10^26 Joules. So in 40 years less than 0.2% of incoming heat was stored in the Ocean. Still not something that one should make apocalyptic predictions about. But again it is not related to Global Warming as defined by IPCC. It is not me who decided to use GMST as the primary metrics. So all the complaints should be addressed to IPCC
I think the heat accumulation is considered mainly to provide an estimate of “warming in the pipeline”. That is, given enough time, the oceans would approach a new pseudo-equilibrium temperature profile, with no net heat uptake over long periods. The fraction of solar energy now accumulating in the ocean would have to be radiated to space…. meaning a higher near surface temperature for equilibrium. How much higher depends on how much total net “forcing” changes in GHGs have caused….. something only very imprecisely known.
In other words, the current total GHG forcing (and any knock-on influences like changes in clouds, vegetation, ice/snow albedo) less the current ocean heat uptake, is what has caused the current measured warming. If the ocean uptake stopped, then surface warming with the same forcing would be higher. This all falls under the question of rapid response versus equilibrium response…. the higher the “true sensitivity” to forcing, the lower the short term temperature increase compared to the equilibrium temperature increase.
The average heat ginned by the oceans daily is used to melt the ice which is breaking off of the ice blocks at the poles.
This heat is equal to that radiated to the black sky daily
Ummm… no. The amount of ice loss multiplied by the heat of fusion, is far less than the accumulated ocean warming.
My main point is the value of warming. In terms of thermodynamic system there is nothing happening, no catastrophe. And again IPCC is talking about near-surface air temperature, not ocean temperature. They cannot move that goalpost. As their energy disbalance calculations are based on surface temperature. What I’m pointing here is that when they make their radiative forcing calculations in W/m2 something goes wrong. They assume ~300W/m2 averaged flux from the Sun and RCP between 3W/m2 to 8.5 W/m2. So more than 1% impact. And this >1% imbalance should have translated into heat stored. But we actually have only 0.00001%. Something is wrong here.
And as I pointed in the first post, even if we take ocean heating into account (which we should not based on IPCC definition of Global Warming) it only gives us 0.2% of heat stored.
Let me know if we agree here.
The order of magnitude issues in energy balance can be resolved by taking water cycle into account and this will put GHG hypothesis out of business
GHG are a necessary component of the atmosphere and are present in the amount that equates with our temperature.
That they result in back radiation is true. However they produce no new energy in doing so.
Ok. I think it will be best if I provide the estimate for alternative that does not have issues with order of magnitude in energy balance. Total water vapor content in the atmosphere is 1.6*10^16 kg. Latent heat of vaporization for water at 1atm is 2000 kJ/kg. So you get 3.2*10^22 Joules of water that was used to gat all that vapour there. This is roughly 100 times larger than hourly heat input from the sun. But water is constantly evaporated and condensed in a cycle. So what those numbers tell us is that just 1-2% of water in the atmosphere is cycled around in an hour. And it is enough to compensate heat input.
Let me preempt claims that due to evaporation and condensation the net energy transfer is Zero. JJBraccili was claiming this earlier. This is incorrect. To condense water large amounts of energy have to be released. Although upper troposphere is older than the ground it is still not cold enough due to low pressure. The only suitable way for water to loose energy is through IR radiation to the universe. Water is the great emitter of LWIR and on top of troposphere there is nothing to stop it. So the whole process is Visible and SWIR radiation heat up the surface. Equivalent amount of water is evaporated and is transferred up due to lower water vapour density (buoyancy effect). At top of the troposphere energy is emitted to the universe and water is condensed and energy balance is restored. Participation of GHG is just a minor fine tuning mechanism, not the primary driver.
It is also worth noting here that heat from the Sun was effectively used to increase potential energy of large mass of liquid water that is now bought to 5-10km height. This potential energy is later used to drive multitude of processes that represent the climate.
Our problem is that we disturbed this cycle. To me the biggest culprit is oil/lubricant contamination of the surface of the ocean and seas. Nanoscopic layer of such lubricants reduces evaporation rate by >10 times (I’ve done experiments myself). It is also fun to see 3 graphs together: 1) warming; 2) co2 concentration; 3) volume of sea freight. Number 1 and 3 correlate much better than 1 and 2.
Let me reiterate, 1-2% of water vapour in atmosphere is ensuring energy balance on Earth. It is disturbance to this value that causes disruption of the climate. Good news is that cleaning ocean surface from lubricants is cheaper than renewable energy initiatives that are based on wrong correlation of GHG to climate change.
Do you have a source that shows that energy released in the atmosphere by water condensation primarily becomes IR. That sounds like speculation on your part to fit your narrative.
What’s your point? Climate change can’t be happening because water is balancing the energy out by water vapor radiating it into space?
Changes in earth’s energy balance are small. The earth absorbs about 240W/m2 from the sun. The imbalance is about 0.6 W/m2. 99%+ the of the energy absorbed from the sun is radiated into space. The size doesn’t matter. Energy can’t be destroyed. As long as any imbalance exists, energy will build up on the planet. There is plenty of evidence that energy is accumulating on the planet. The imbalance exists.
So far I’ve seen a theory that say that as temperature rises the albedo effect falls. If atmosphere temperature is rising. the atmosphere holds more water. It seems counterintuitive. More water should mean more clouds, albeit higher in the atmosphere. Of course, it can’t be verified. We don’t have enough satellites to quantify the albedo effect.
Then we have the theory that the temperature of the earth is solely determined by the rotation of the earth. Laughable on its face. An equation which I can’t figure out where it came from and claims that it matches 4 planets with the planet Venus conspicuously left out. I think I know why.
Now we have the water balance theory that relies on all or most of the energy from water condensation converting to IR. I just looked and I can’t find any reference that says that’s true. Does some convert to IR? Sure. H2O takes kinetic energy and converts it into IR. It’s just as likely that the latent heat warms the atmosphere and the amount that becomes IR is relatively small.
All these pet theories that are destined to go nowhere. Of, course its a giant conspiracy between climate scientists and the MSM to prevent the “truth” from coming out. To what end?
Climate change has been consensus science for 40 years. It has been accepted by generations of scientists, by scientists from different countries, political and religious beliefs, etc. It’s hard to find a scientific finding that has more acceptance. Yet, here we are.
JJBraccili
“Then we have the theory that the temperature of the earth is solely determined by the rotation of the earth. Laughable on its face. An equation which I can’t figure out where it came from and claims that it matches 4 planets with the planet Venus conspicuously left out. I think I know why.”
JJBraccili, you have already visited my website’s home page. I have developed many more other pages that explain everything about the New equation’s terms.
Of course, you haven’t yet visited the page I devoted to planets with atmosphere Venus, Earth, Titan.
It is all in the details… To view other pages – Please click on the box at the top.
https://www.cristos-vournas.com
to JJBraccili.
So first, you have no issue that Global Warming according to IPCC is 0.00001% of the heat supplied into thermodynamic system. Above in the chat you had the whole post dedicated to laws of thermodynamics, so you should have enough knowledge to understand how ridiculous that sounds.
Second, interesting that you decided to use the lowest boundary of radiative forcing 0.6 W/m2 that IPCC claims. In IPCC report they give the range of 0.6 to 2.4 W/m2 with average of 1.6W/m2. While their worst scenario projection is RCP8.5 W/m2. Why would you do that?
Third, 0.6 is still 0.25% of the input energy, while I showed to you that actual Global Warming (based IPCC definition) is 0.00001%. So something is wrong still. And if you believe IPCC so much, why don’t you explain what is happening.
Fourth, why IPCC and you are using a strange for of First Law of Thermodynamics, where Heat input minus heat output is only equal to the gain in internal energy, where internal energy is solely thermal energy. You know thermodynamics, you should know that this is not true. Let’s ignore mass loss and gain an consider Earth closed thermodynamic system. Then first law will give us that heat input minus heat output will be equal to work done by the system plus change in internal energy, which include both thermal component (change in temperature) and chemical storage.
You are chemist, so you should know that many complex molecules on this planet contain energy inside them. And the stored chemical energies are released back on very different time scales. Until we started burning oil, it was not even releasing the energy. Maybe, IPCC thinks that conversion of Sun light into chemical energy is small value that can be ignored, but I didn’t see them even trying to assess it. According to Wiki theoretical maximum efficiency of solar energy conversion in photosynthesis is approximately 11%. Is it really something that should be ignored.
But for me, more important part would be work done. As I estimated earlier 1-2 percent of water vapor in the atmosphere is continuously cycled, so we can assume similar timescales with heat input. So we get 10^14 kg of water that is constantly brought to a height of 10000 m. This is 10^19 Joules equivalent potential energy. And with Sun input being 5*10^20, the generated potential energy corresponds to 2% of the heat input. Way larger than even your 0.25% radiative forcing. How is it that you ignore this component in your energy balance equation.
Fifth, let’s talk about energy release by H2O through IR radiation. As proponent of “consensus science” you are fine with CO2 releasing heat energy through IR. Even IPCC and oh boy, original Arrhenius paper is saying that H2O is the most critical/potent gas in the atmosphere for IR heat transfer. But you are not able to find any reference about it. Very strange. Now if we consider your claim that H2O is condensing by loosing kinetic energy to surrounding air and not by radiation, then the question is how that surrounding air would loose the energy? N2 and O2 are really bad IR emitters. Are you seriously not seeing the problem in your logic?
Sixth, “All these pet theories that are destined to go nowhere. Of, course its a giant conspiracy between climate scientists and the MSM to prevent the “truth” from coming out. To what end?”. You can surely treat me as conspiracy theories. But you can also consider why Global Warming through CO2 theory is promoted so aggressively, even if it is inconsequential (0.00001%) for the energy balance or climate. And the key word will be greed. You can calculate how much money was spent by government on renewables and thus, absorbed by parties that feed consensus scientists. And the greed is only increasing year by year with culmination into this https://www.forbes.com/sites/davidrvetter/2020/04/20/how-a-110-trillion-green-recovery-can-save-the-world-new-report/
We are all treated as imbeciles and you are helping them to get rich ;)))
Also, notice that my theory is not absolving humans from the problems of climate change. We did screw up. But the key problem is not CO2 emissions but water surface contamination with oil based lubricants. My key argument is not of some “climate change skeptic”. My argument is that solution to the problem is different from what we are trying to do now. And from my perspective cleaning the oceans, that we should do in any case, will be cheaper than 130 Trillion $. Just consider it.
to JJBraccili.
So first, you have no issue that Global Warming according to IPCC is 0.00001% of the heat supplied into thermodynamic system. Above in the chat you had the whole post dedicated to laws of thermodynamics, so you should have enough knowledge to understand how ridiculous that sounds.
Second, interesting that you decided to use the lowest boundary of radiative forcing 0.6 W/m2 that IPCC claims. In IPCC report they give the range of 0.6 to 2.4 W/m2 with average of 1.6W/m2. While their worst scenario projection is RCP8.5 W/m2. Why would you do that?
Third, 0.6 is still 0.25% of the input energy, while I showed to you that actual Global Warming (based IPCC definition) is 0.00001%. So something is wrong still. And if you believe IPCC so much, why don’t you explain what is happening.
Fourth, why IPCC and you are using a strange for of First Law of Thermodynamics, where Heat input minus heat output is only equal to the gain in internal energy, where internal energy is solely thermal energy. You know thermodynamics, you should know that this is not true. Let’s ignore mass loss and gain an consider Earth closed thermodynamic system. Then first law will give us that heat input minus heat output will be equal to work done by the system plus change in internal energy, which include both thermal component (change in temperature) and chemical storage.
You are chemist, so you should know that many complex molecules on this planet contain energy inside them. And the stored chemical energies are released back on very different time scales. Until we started burning oil, it was not even releasing the energy. Maybe, IPCC thinks that conversion of Sun light into chemical energy is small value that can be ignored, but I didn’t see them even trying to assess it. According to Wiki theoretical maximum efficiency of solar energy conversion in photosynthesis is approximately 11%. Is it really something that should be ignored.
But for me, more important part would be work done. As I estimated earlier 1-2 percent of water vapor in the atmosphere is continuously cycled, so we can assume similar timescales with heat input. So we get 10^14 kg of water that is constantly brought to a height of 10000 m. This is 10^19 Joules equivalent potential energy. And with Sun input being 5*10^20, the generated potential energy corresponds to 2% of the heat input. Way larger than even your 0.25% radiative forcing. How is it that you ignore this component in your energy balance equation.
Fifth, let’s talk about energy release by H2O through IR radiation. As proponent of “consensus science” you are fine with CO2 releasing heat energy through IR. Even IPCC and oh boy, original Arrhenius paper is saying that H2O is the most critical/potent gas in the atmosphere for IR heat transfer. But you are not able to find any reference about it. Very strange. Now if we consider your claim that H2O is condensing by loosing kinetic energy to surrounding air and not by radiation, then the question is how that surrounding air would loose the energy? N2 and O2 are really bad IR emitters. Are you seriously not seeing the problem in your logic?
Sixth, “All these pet theories that are destined to go nowhere. Of, course its a giant conspiracy between climate scientists and the MSM to prevent the “truth” from coming out. To what end?”. You can surely treat me as conspiracy theories. But you can also consider why Global Warming through CO2 theory is promoted so aggressively, even if it is inconsequential (0.00001%) for the energy balance or climate. And the key word will be greed. You can calculate how much money was spent by government on renewables and thus, absorbed by parties that feed consensus scientists. And the greed is only increasing year by year with culmination into this https://www.forbes.com/sites/davidrvetter/2020/04/20/how-a-110-trillion-green-recovery-can-save-the-world-new-report/
We are all treated as imbeciles, and you are helping them to get rich ;)))
Also, notice that my theory is not absolving humans from the problems of climate change. We did screw up. But the key problem is not CO2 emissions but water surface contamination with oil-based lubricants. My key argument is not of some “climate change sceptic”. My argument is that solution to the problem is different from what we are trying to do now. And from my perspective cleaning the oceans, that we should do in any case, will be cheaper than 130 Trillion $. J
I’m going to go through your post in order and comment on what you said.
I used a radiative forcing number of 0.6 W/m2 because that’s what I remembered. Your implying a small radiative forcing to absorbed solar radiation number is somehow significant. It isn’t. Energy cannot be destroyed. Any imbalance will cause energy to accumulate on the planet. Smaller numbers means it takes more time to see the effects.
I’m not going to comment on the IPCC numbers. If you have spotted an inconsistency, you need to bring that to their attention.
You asked about why work isn’t accounted for in earth’s energy balance. The earth is a closed thermodynamic system. No mass enters or leaves the system. The boundary of the system is outer space. The only energy that has to be accounted for is energy that crosses the boundary. There is no conduction or convection into space because there is no mass in outer space to conduct or convect to. Heat entering or leaving the system must be by radiant energy transfer. Outer space is a vacuum. You cannot do work into a vacuum. Therefore, there is no work term.
Regarding photosynthesis. Worldwide energy generation contributes 20 TW to earth’s energy balance. Geothermal contributes 50 TW to earth’s energy balance. Photosynthesis contributes -130 TW to earth’s energy balance. The net contribution is -60 TW. The sun contributes 120,000 TW to earth’s energy balance. The net contribution is too small to matter. It is ignored.
Next you wonder why we neglect water’s potential energy in the earth’s energy balance. That’s because it has no impact. Remember the only energy that matters is energy that crosses the system boundary. The earth is a closed system. No water leaves the system. The potential energy that the water gains as it rises in the atmosphere is returned when the water condenses and is returned to the earth. Net impact is zero.
What happens when water condenses in the atmosphere? The process is isothermal. Constant temperature means that there is no change in the kinetic energy of a water molecule as it transitions from the vapor phase to the liquid phase. What you want is that all of the latent heat gets converted to IR. That doesn’t happen. If it did, we wouldn’t have thunderstorms, hurricanes, or tornadoes. The only way a H2O molecule obtains the energy to radiate a photon is from kinetic energy or from absorbing a compatible photon. If the kinetic energy of H2O molecules is constant the latent heat isn’t going to cause the H2O molecule to radiate IR. In order to transfer the energy to surrounding molecules the kinetic energy of those molecules has to be lower than the kinetic energy of the H2O molecules. What happens to the transferred energy? It increases the kinetic energy of the surrounding molecules. It only transfers the amount of energy that keeps the kinetic energy of he surrounding molecules < the kinetic energy of the water molecules. It can't transfer more than that because the condensation process will stop.
Where does the energy go. It's distributed within the earth system. Don't forget the same amount of energy was removed from the earth so the temperature of the earth would be slightly cooler. The atmosphere is now slightly warmer so some is returned to the earth. Some, but I doubt much gets radiated into space. Some may melt ice.
Your analysis doesn't prove climate science is wrong. You didn't apply the science correctly and came to erroneous conclusions.
There is no conspiracy. Just the correct application of science by some very good scientists.
Apologies for double posting, Internet is misbehaving. And there is no delete/edit function here
> you should have enough knowledge to understand how ridiculous that sounds
Don’t hide behind someone else’s knowledge, Dmitry.
Show how ridiculous that is.
Willard, not sure what you mean by this. Nothing in my post is hiding behind someone else knowledge.
If you read the whole post you will actually see the explanation of why I find it rediculous as I discuss all the components of energy balance based on first law of thermodynamics
(Let’s try again:)
Nothing you said supports your argument, which rests on the idea that a very small amount can’t have a very big impact, Dmitry.
Chemists above all should know that it’s patently false.
Willard, let’s try again indeed.
Please read through the whole argument. Notice that two theories are compared in description of a thermodynamic system. (not sure why you bring chemistry into the topic. I’m physist and constantly work with thermodynamic systems and know how rediculous 0.00001% heat storage sounds). First theory claims that a considered thermodynamic system describing Earth is a piece of paper in vacuum that is in thermal equilibrium between radiative heat input from the Sun and radiative heat loss to the universe. It also claims that in the last 100 years the paint on the piece of paper degrade so badly that 0.00001% of Sun input is additionally stored in it. And because of that value the piece of paper will catch fire…
Second theory shows that Earth is a proper thermodynamic system (as an approximation we can consider closed system). In this system the difference between heat source and heat sink is used for work and energy storage. The later includes both temperature increase (0.00001%) and chemical storage (this were the chemist Braccili should be arguing against the “consensus science” but he is not). Now the usuful work is bringing large mass of liquid water to a height of 10km. School training should be sufficient to understand that this is very energy intensive. Now the way Earth is achieving it is by converting energy from the Sun Into latent heat of water (evaporation). Then due to lower density of water vapour in comparison with Nitrogen and oxygen, buoyancy pushes water vapour to the top of the troposphere. Their water is exposed to uninterrupted radiant heat sink of the universe and it capitalize on the fact that Water is an ideal IR absorber/emitter (orders of magnitude stronger than CO2). So latent heat is lost by IR radiation and water condenses into droplet nuclei, from whiblch the clouds are formed later.
Now question to you. What are you arguing about? Is the question about how small things can bring big changes? Or is the question about focusing on paper cut, while your head is chopped off? Are you familiar with allegory of the gave from Plato? ;) try to turn your head and stop trying to distinguish patterns in the shadows on the wall
> I’m physist and constantly work with thermodynamic systems and know how rediculous 0.00001% heat storage sounds
You can add as much zero as you like, Dmitry. Invoke all the energy that is on this planet for all I care. An argument from incredulity remains an argument from incredulity. It has no scientific merit.
The Tyndall effect implies that there is more energy in than energy out of the system. Humans are increasing that effect. This effect carries risks.
That’s all there is to it, really, and nothing you said defeats that simple argument.
Willard,
It is funny that you would talk about incredulity while being religiously zealous and not even entertaining the thought that something is wrong after numbers are show to you.
To summarize your argument : Bible is true because Bible says its true. 🤣🤣🤣
Didn’t get why Tyndall effect about light scattering in colloid solution is brought in. Did you make a typo? Or is it very deep allegory and my ant brain is incapable to comprehend it?
Wow. This Chat system is really inconvenient here.
to JJBraccili
Don’t understand why you bring “energy cannot be destroyed”, where did I claimed otherwise? All I say is that so called Global Warming has such a minor effect on the energy balance that it should be the one ignored.
“Smaller numbers means it takes more time to see the effects.” – we are told by activists that apocalypses will happen in 12 years. What is your range of “more time”?
You somehow are not denying that my calculations are wrong. What stops you? Why it is not bothering you that based on heat flux IPCC using gets forcing that is close to 1% of heat input, but when we consider actual stored heat we get a value of 0.00001%? How can we explain such discrepancy? We know (at least you are refusing to prove me wrong) second value is based on well measured and well understood science. But the first value is actually based on a hypothetical construct of back radiation and even more bewildering is the hypothesis that due to CO2 the upper boundary of the adiabatic lapse is shifting and that causes heating. The later is usually unknown among general public but is actually the cornerstone of GHG theory as pushed by James Hansen from 70s.
“I’m not going to comment on the IPCC numbers. If you have spotted an inconsistency, you need to bring that to their attention”
It is a very common phenomenon among supporters of “consensus science”. The moment you have no arguments you demand that all the questions should be addressed to a higher authority or first be published in a peer reviewed journal. Why is it like this? What stops you from taking the numbers or the definitions/assumptions that I use and see if they are correct? You were so brave to fight the skeptics so far with the treasure of your knowledge so far. Why do you surrender authority in this case?
“You asked about why work isn’t accounted for in earth’s energy balance.”
So, you are totally not able to distinguish the following 2 scenario:
1) heat is applied to a chunk of metal for long enough that the heat source balances the heat sink.
2) heating up a boiler with water (assuming same thermal mass as chunk of metal). And the generated of steam is used to perform work first before energy is dissipated into the heat sink when steam condenses.
Heat source and heat sink are the same in both scenarios. Are these scenarios equivalent for you? It seems like yes. Then why wouldn’t you use the first scenario when you estimate temperature inside the boiler? There should be no problem for you.
“Photosynthesis contributes -130 TW to earth’s energy balance. … The sun contributes 120,000 TW to earth’s energy balance. ”
Assuming your values are correct, photosynthesis absorbs 0.1% of input energy. Still much more than 0.00001% that goes into Global Warming. So why do you count the small one and dismiss the larger one. Illogical.
You understanding of how water looses energy is quite sad. At least you should know why there are terms for IR water window for atmosphere transparency. It is the most critical GHG effect vene by accounts of your religion. You can even read (I guess you never did) the original paper by Arrhenius (Bible for climate science) and most of GHG effect is attributed to water vapour there. It is IR emission from top of the atmosphere from water vapour that is responsible for most of the heat loss into the cold universe. How to argue with you if you do not know such basics? Very frustrating actually. Please stop talking theology, start talking science.
Either disprove my calculations or provide your own. Science has to be verifiable and falsifiable. Climate science is the only branch that is not. It is really just another form of religion.
JJBraccili | October 13, 2021 at 12:40 pm |
“Do you have a source that shows that energy released in the atmosphere by water condensation primarily becomes IR.”
I believe the images of the earths radiation budget show latent heat as 80W/M2 and evapotranspiration as 17W/m2 as sources for water condensation becoming latent heat. Would that do?
“”What’s your point? Climate change can’t be happening because water is balancing the energy out by water vapor radiating it into space?”
The climate is changing all the time despite the radiation out to space being in balance
“Changes in earth’s energy balance are small. The earth absorbs about 240W/m2 from the sun. The imbalance is about 0.6 W/m2. 99%+ the of the energy absorbed from the sun is radiated into space. The size doesn’t matter. Energy can’t be destroyed. As long as any imbalance exists, energy will build up on the planet. There is plenty of evidence that energy is accumulating on the planet. The imbalance exists.””
You are postulating storage of energy.
Energy cannot be stored as it is always in motion.
There is no imbalance.
There is no evidence of imbalance.
The error bars are too wide and TOA always means energy in equals energy out.
“So far I’ve seen a theory that say that as temperature rises the albedo effect falls. If atmosphere temperature is rising. the atmosphere holds more water. It seems counterintuitive. More water should mean more clouds, albeit higher in the atmosphere. Of course, it can’t be verified. We don’t have enough satellites to quantify the albedo effect.””
you get a pass on the first bit and a fail on the second.
I agree albedo could go up.
We have more than enough satellites to make albedo estimations. There is a large margin of error but we can certainly determine albedo and its effects.
“”Then we have the theory that the temperature of the earth is solely determined by the rotation of the earth. “”
Wikipedia disagrees with you for obvious reasons, as does Dr R Spencer.
“”Now we have the water balance theory that relies on all or most of the energy from water condensation converting to IR. I just looked and I can’t find any reference that says that’s true. Does some convert to IR? Sure. H2O takes kinetic energy and converts it into IR. It’s just as likely that the latent heat warms the atmosphere and the amount that becomes IR is relatively small.”
Derision.
First you deny it exists and ask for a source, then you admit it exists.
Whether it works or not you cannot deny that energy released goes into IR.
“All these pet theories that are destined to go nowhere.”
Sadly true.
“Of, course its a giant conspiracy between climate scientists and the MSM to prevent the “truth” from coming out. To what end?”
“”Climate change has been consensus science for 40 years. “”
Science is determined by fact, not consensus
Isakov Dmitry
“…and even more bewildering is the hypothesis that due to CO2 the upper boundary of the adiabatic lapse is shifting and that causes heating. The later is usually unknown among general public but is actually the cornerstone of GHG theory as pushed by James Hansen from 70s.”
Very well said! Thank you.
https://www.cristos-vournas.com
Dmitry,
Let me see if I can simplify my argument even if it’s already quite simple:
(P1) A toaster only generates a few watts.
(P2) It is only a tiny fraction of the energy that we can trace on the Earth.
(C) Therefore it is absurd to think that my toaster can make toasts.
That should be enough to see why your argument does not work.
You are reinventing “but trace gas” using physics armwaving.
No wonder the scientists to whom you allegedly spoke shrugged it off.
Willard,
“Let me see if I can simplify my argument even if it’s already quite simple”
I think you need to gather yourself. Read through all your posts. There is no argument there. Do you even understand the meaning of the word “argument”?
“(P1) A toaster only generates a few watts.
(P2) It is only a tiny fraction of the energy that we can trace on the Earth.
(C) Therefore it is absurd to think that my toaster can make toasts.”
What are you smoking? I cannot even imagine how to discuss anything with you. You are scaring me. Please seek help.
> There is no argument there
You might have missed it, Dmitry. Here it is again:
Your argument takes the same form. It is invalid. Just like any other silly appeal to incredulity.
You are new here. “But Trace Gas,” “But religion,” and “But Consensus” are nothing new.
Get over yourself.
Willard.
The Tyndall effect implies that there is more energy in than energy out of the system. Humans are increasing that effect. This effect carries risks.
That’s all there is to it, really,
Every effect carries both risk and reward, Willard.
That is something ignored on every occasion by people worrying about the GHG effect.
What risks are inherent in proposing actions without full understanding?
What rewards might come from a warming of the atmosphere, if it was to occur.
A one sided approach, risks death destruction and what about the children approach is countered by rewards, understanding, construction and won’t the children have better lives with food fuel health and education.
Something I fell is worth discussion and pondering on by all.
> Every effect carries both risk and reward,
Thank you, Doc Obvious.
You might prefer:
https://andthentheresphysics.wordpress.com/2021/10/12/science-communication-4/#comment-200817
Willard.
The Tyndall effect implies that there is more energy in than energy out of the system. Humans are increasing that effect.
There are several schools of thought here and multiple outre ideas.
The comments I have been making trying to stimulate some scientific discussion are a bit too outrageous , I guess, for some to take apart.
If the Tyndall effect implies more energy in than out I think that this itself is an outrageous statement that cannot go unchecked.
I think the GHG effect can be described in terms that does not violate the basic laws of physics.
A lot of people do not wish to acknowledge a GHG effect which is a shame.
Others use it, like you do. to violate the laws of physics, Renowned San Diego-based climate scientist Veerabhadran Ramanathan being the prime proponent.
The basic laws of physics do not allow radiation imbalance and storage to occur in an open system. These can only be accomplished by artifice in a closed system.
Willard,
get a cold shower an do some exercises. You are really loosing it and you are not able to follow discussion or your own statements.
Let’s look through them so you know what I mean:
Your first comment:
“Don’t hide behind someone else’s knowledge, Dmitry.
Show how ridiculous that is.”
Funnily that the whole post that you referred to was dedicated to showing the ridiculousness. But either you didn’t read or you lack comprehensions skills.
Your second post:
“(Let’s try again:)
Nothing you said supports your argument, which rests on the idea that a very small amount can’t have a very big impact, Dmitry.
Chemists above all should know that it’s patently false”
Again no substance. Just putting words into my mouth that I didn’t say. Again you have show that you didn’t read or not capable to comprehend my post.
Your third post:
“You can add as much zero as you like, Dmitry. Invoke all the energy that is on this planet for all I care. An argument from incredulity remains an argument from incredulity. It has no scientific merit.
The Tyndall effect implies that there is more energy in than energy out of the system. Humans are increasing that effect. This effect carries risks.
That’s all there is to it, really, and nothing you said defeats that simple argument”
I hope you do understand the meaning of incredulity – the state of being unwilling or unable to believe something. Believing has no place in scientific debate, it should be confined only to theological studies. I really hope that we want to KNOW and UNDERSTAND things, instead of BELIEVING.
I don’t know which Tyndall effect you are talking about. The only one I’m aware of is “Tyndall effect, also called Tyndall phenomenon, scattering of a beam of light by a medium containing small suspended particles—e.g., smoke or dust in a room, which makes visible a light beam entering a window”. https://www.britannica.com/science/Tyndall-effect
Please check your definitions before your through things around. Unless there is another Tyndall effect, please enlighten me.
Your fourth post:
“Let me see if I can simplify my argument even if it’s already quite simple:
(P1) A toaster only generates a few watts.
(P2) It is only a tiny fraction of the energy that we can trace on the Earth.
(C) Therefore it is absurd to think that my toaster can make toasts.
That should be enough to see why your argument does not work.
You are reinventing “but trace gas” using physics armwaving.
No wonder the scientists to whom you allegedly spoke shrugged it off”
Which argument were you trying to simplify? There was nothing that can be described argument in any of your previous posts. And by argument I mean – a reason or set of reasons given in support of an idea, action or theory.
If you thing that your simple argument contains an actual argument you will need to provide equivalence of P1, P2 and C to statements and logic train that I’ve made in my posts. All you demonstrating again is that you are missing faculties for comprehension. That is why I suggested that you are probably smoking something strong.
Your Fifth post:
“> There is no argument there
You might have missed it, Dmitry. Here it is again:
(P1) A toaster only generates a few watts.
(P2) It is only a tiny fraction of the energy that we can trace on the Earth.
(C) Therefore it is absurd to think that my toaster can make toasts.
Your argument takes the same form. It is invalid. Just like any other silly appeal to incredulity.
You are new here. “But Trace Gas,” “But religion,” and “But Consensus” are nothing new.
Get over yourself.”
f
Here you just confirm again that you have problem with comprehensions. My full statement was “I think you need to gather yourself. Read through all your posts. There is no argument there.” Meaning that it was referring to your posts #1-3. You cannot bring post #4 in reply to this.
Then again your P1, P2 and C can have any meaning only if you provide equivalence to any of my statement. But because we establish that you lack comprehensions capabilities I cannot assess what you are referring to. It seem to be all in you head and not connected to anything I wrote earlier.
I think you need help. But I still try to debate with you if only you can formulate an actual argument, with strict definitions and quantifiable claims. I do not care about your beliefs.
https://judithcurry.com/2021/10/10/radiative-energy-flux-variations-from-2000-2020/#comment-961479
I like how you decided to ignore my demonstration that you have no comprehension capability and you probably lack logic.
But it’s OK. Blissfully ignoring facts is a standard strategy for people like you.
In return, dear Dmitry, please rest assured that your furious armwaving is duly noted:
https://xkcd.com/793/
You got nothing more than an appeal to incredulity, and there’s no amount of shadowboxing that will hide it.
Did you know that our breathing was regulated by a cluster of a few thousand cells? Out of trillions of cells. I kid you not.
Incredible, isn’t it?
Willard, there is not enough face pulm emojis in the world to express my emotions in regards your lack of basic logic skills. And there are so many of you in the world now. We are all doomed.
Dear Dmitry,
Considering that you just spent a day writing walls of words that fall under your lack of support for your own incredulity, you are in no position to pontificate on logic.
Willard
Face pulm^84
I’m done arguing with a child.
Arguing would be a good idea, my beloved Dmitry.
Try it sometimes.
Didn’t they teach you in school on how to debate and form logical arguments? I’m really shocked and flabbergasted that you cannot follow your own flow of arguments, forget about mine.
I can follow my argument quite alright thank you, dear Dmitry. It’s a very simple one, so simple in fact even you could get it. It can we worded in a sentence: you are arguing from incredulity, and it sucks.
Willard,
I see that you learned a new word in school – incredulity. And now you wish to use it everywhere. Good boy. Try hard and play around. But it is time to start paying attention on when it makes sense to use it. Hint: scientific debates are the last place for it.
However, don’t worry. Learning the vacabluray is a very important part of your studies. Next year you will hopefully start taking classes in logic and rules of debate. They will teach you what it means to make a valid argument. But it is OK. Today it is too early for you. Go have a candy
My dear Isaac,
To back up one’s position on incredulity is very different than scepticism. Since there’s no ism word for it, I created one:
https://web.archive.org/web/20121031114939/http://planet3.org/2012/08/24/incredibilism/
That’s very different from pointing out an inconsistency. Here’s how the latter works:
[DMITRY] You are not able to debate beyond ad hominem, distractions and goal post movement.
[ALSO DMITRY] I’m done arguing with a child.
See? It’s very simple to point out an inconsistency, and it does not involve incredulity. You have yet to do that regarding AGW.
Best of luck!
Willard,
I see. Right .
“[ALSO DMITRY] I’m done arguing with a child.
See? It’s very simple to point out an inconsistency, and it does not involve incredulity. You have yet to do that regarding AGW.”
There is indeed a reason to call me inconsistent. And it doesn’t absolve me that I asked you to provide a logical argument or at least some kind of cohesive. Or at least explain why you accuse me of incredulity and how anyone believes matter in a scientific discussion.
Your failure to behave like a mature person is not an excuse to equate you with a child. It is indeed unfair to children. I met quite many that can have logical discussion and behave maturely when they discuss serious topics. I apologize to them. My bad.
I should have just used the rules of this blog and from now on I will follow them precisely.
“Only respond to comments that you feel are deserving of your attention, and ignore the rest. By being ignored, commenters who are not deemed interesting by others will give up and go elsewhere.”
Good luck to you, and go annoy other commenters.
Lets take a cup of water in a room that Mr JJBraccili
has hit with a number of watts to get a few simple points across.
The first is that we are not just discussing the cup of water and the energy injection.
This is a simplified example that ignores the rest of GHG, entropy and science.
In effect we have an object, already heated from 0 Kelvin to 293 Kelvin [20 Celsius] room temperature, surrounded by air at 101,325 Pa equivalent to 760 mm Hg, 29.9212 inches Hg, or 14.696 psi.
It is being acted upon by Gravity at 9.8 m/s²,
It is composed of atoms and energy.
Matter and force.
Matter and energy share a common link but are not interchangeable.
If the atoms of the cup and water were to be at 0 Kelvin, alone in space with only their own gravity to consider there would be no action.
In this state both the cup and the water [now ice of some sort] are colloquially the bucket. They are pure matter without any energy or motion to consider.
In this setting one could send some energy to the object and assess what happens.
This actually occurs in real life as comets approach and recede from the sun.
Two scenarios a short burst of low energy will be absorbed and emitted with no real change.
A longer burst will lead to motion of the particles as they absorb, start moving, then emit the energy.
Enough energy and the cup will heat up, the water melt and dissipate as steam around the cup.
Once paused the water will return to the cup but not necessarily into it and all will be as before.
0 Kelvin and no stored energy.
None.
The water despite being a GHG will not have stored a single drop of energy.
Time wise? a 1 second burst of energy? No more. Should all be over in a second.
Why does a cup of water stay warm when all the energy that went into it has come out of it in 1 second?
Because the cup of water is now being back radiated by the air and room around it. that it heated up.
Not because it has retained heat [energy in it].
That has already radiated out.
The whole room is responsible for the little bit of heat that had to go out
Angech,
“This is a simplified example that ignores the rest of GHG, entropy and science.”
I really hope that we stop ignoring science in the discussions. So far it is what I’m witnessing in most of the comments in regards my arguments. Why can’t all of you just focus on science and stop using unfalsifiable arguments.
But ok let me try to follow your argument.
You start with numbers but never even use them. And what was that: air at “101,325 Pa equivalent to 760 mm Hg, 29.9212 inches Hg, or 14.696 psi.”
Did you just copy paste from somewhere? Why do you need all those 4 digits after comma? You are not even using the approximate values in our arguments. Also, why didn’t you give 4 digits for mm Hg (759.9999 mm Hg)? This is very strange. Not a good sign. But let’s ignore it.
“It is composed of atoms and energy. Matter and force. Matter and energy share a common link but are not interchangeable”
Sounds profound, particularly “matter and force” but has little utility or value in the discussion. I really do not understand why are you saying these things.
“In effect we have an object, already heated from 0 Kelvin to 293 Kelvin [20 Celsius] room temperature, surrounded by air” and then “If the atoms of the cup and water were to be at 0 Kelvin, alone in space with only their own gravity to consider there would be no action”.
So which scenario do you actually want to discuss? I do not know what you mean by “no action”. 0 Kelvin is referring to the state where there is no motion of molecules, minimum for thermodynamic system only. It doesn’t mean that there are no actions. Electrostatic forces do not cease to exist at 0K. More to this it doesn’t even mean that there is no motion. Because 0K is specifically defined for ideal gas case. Let me quote encyclopedia https://www.britannica.com/science/absolute-zero: “The concept of absolute zero as a limiting temperature has many thermodynamic consequences. For example, all molecular motion does not cease at absolute zero (molecules vibrate with what is called zero-point energy), but no energy from molecular motion (that is, heat energy) is available for transfer to other systems, and it is therefore correct to say that the energy at absolute zero is minimal.”
Please, consider being more scientific and careful in your statements.
“In this setting one could send some energy to the object and assess what happens.
Two scenarios a short burst of low energy will be absorbed and emitted with no real change”.
I hope that you are just using a clumsy way in describing reflection when you say “absorbed and emitted with no real change”.
“A longer burst will lead to motion of the particles as they absorb, start moving, then emit the energy” – ok let’s just proceed and see what is your argument. I’m very suspicious about what you actually mean by “Longer burst”.
“Enough energy and the cup will heat up, the water melt and dissipate as steam around the cup. Once paused the water will return to the cup but not necessarily into it and all will be as before. 0 Kelvin and no stored energy.”
What do you mean by enough? If energy is absorbed, by definition the cup will heat up, no matter how much energy above the ground state. You seem to miss the difference between different states of matter and what is thermodynamic definition of temperature. It might by a surprise for you but phenomena responsible for temperature in solid and gas are very different. Temperature value as measured by thermometer can give you the same value but the fundamental phenomena is different. There is no translational movement in solids, only vibrations, while molecular vibrations in gas molecules have little effect on the thermodynamic temperature of the gas – BY DEFINITION. Also phase transitions (melting and evaporation) are not covered by Maxwell-Boltzmann distribution. You have to be careful there.
“water will return to the cup ” – what do you mean by this? Where did energy go? “but not necessarily into it and all will be as before” – what? how? This is self-contradictory. I’m lost.
May I suggest that you revised your whole argument to become scientific. Otherwise it is pointless to discuss.
Or better, instead of making up scenarios and analogies, why not to focus on my argument, which is based on strict definitions and quantifiable effects?
angech
“Why does a cup of water stay warm when all the energy that went into it has come out of it in 1 second?
Because the cup of water is now being back radiated by the air and room around it. that it heated up.
Not because it has retained heat [energy in it].
That has already radiated out.
The whole room is responsible for the little bit of heat that had to go out”.
Very well said! Thank you.
Now let’s instead of a cup of water have a thermometer. Thermometer measures its own temperature. When in the room thermometer is “capable” measuring indoors air temperature…
But when outdoors, thermometer cannot measure outdoors air temperature.
https://www.cristos-vournas.com
Isakov Dmitry | October 15, 2021 at 2:29 am |
Angech,
ok let me try to follow your argument.
You start with numbers but never even use them. And what was that: air at “101,325 Pa equivalent to 760 mm Hg, 29.9212 inches Hg, or 14.696 psi.”
That was using numbers.
Did you just copy paste from somewhere?
Yes.
Why do you need all those 4 digits after the comma?
I don’t.
“It is composed of atoms and energy. Matter and force. Matter and energy share a common link but are not interchangeable”
Sounds profound,
“In effect we have an object, already heated from 0 Kelvin to 293 Kelvin [20 Celsius] room temperature, surrounded by air” and then “If the atoms of the cup and water were to be at 0 Kelvin, alone in space with only their own gravity to consider there would be no action”.
I do not know what you mean by “no action”.
0 Kelvin is referring to the state where there is no motion of molecules.
That will do
minimum for thermodynamic system only.
It doesn’t mean that there are no actions
If there is no motion there is no action.
“The concept of absolute zero as a limiting temperature has many thermodynamic consequences. For example, all molecular motion does not cease at absolute zero (molecules vibrate with what is called zero-point energy), but no energy from molecular motion (that is, heat energy) is available for transfer to other systems,
Basically, if no motion exists, and none does as no heat is produced, then there is no energy at absolute zero.
If there is then you are not at absolute energy.
Vibrations, if they exist and are detectable can only be detected if they produce heat or energy.
Please, consider being more scientific and careful in your statements.
I hope that you are just using a clumsy way in describing reflection when you say “absorbed and emitted with no real change”.
No Reflection is different to absorption and emission and a very difficult concept.
“A longer burst will lead to motion of the particles as they absorb, start moving, then emit the energy” – [more energy than a shorter burst]
“ If energy is absorbed, by definition the cup will heat up,
You seem to miss the difference between different states of matter.
No energy cold and solid, more energy, liquid gas phases, more energy.
more separation.
Also phase transitions (melting and evaporation) are not covered by Maxwell-Boltzmann distribution. You have to be careful there.
Thank you that might be useful if true.
“water will return to the cup but not necessarily into it and all will be as before”.
If you look at an icy comet you can see it as it approaches the sun due to a tail of hot water vapour and dust. When it goes away from the sun and stops receiving energy the steam falls back onto the surface of the comet and ices up.
May I suggest that you revise your whole argument to become scientific.
Have to start somewhere , is a work in progress with lots of holes in the argument as you point out.
Otherwise it is pointless to discuss.
No you have been helpful in pointing out some of the problems.
Why not to focus on my argument, which is based on strict definitions and quantifiable effects?
Too long and not easy to follow.
You need to shorten it and make your points easy and readable.
Christos
“Now let’s instead of a cup of water have a thermometer. Thermometer measures its own temperature.
When in the room a thermometer is “capable” measuring indoors air temperature…
But when outdoors, a thermometer cannot measure outdoors air temperature.”
–
You do have to be careful when you make statements like this.
You can maneuver your words around and then claim you meant it in a different way.
–
Thermometers, unspecified, are devices that measure temperature.
Thermometers can definitely be set up to measure what everyone else here would call outdoors air temperature.
–
By trying to be cute, not specifying your terms clearly, you can make a lot of claims, not proofs.
> it doesn’t absolve me that I asked you to provide a logical argument or at least some kind of cohesive.
You are begging a question that as been answered many times, dear Dmitry. Your argument against AGW is a variant of “But Trace Gas.” That silly line works like this:
(Fact) CO2 is a trace gas.
(Incredulity) A trace gas cannot be the control knob of the atmosphere.
(Conclusion) AGW cannot be true.
Compare and contrast with a claim you repeated many times:
Notwithstanding the unsubstantiated appeal to authority, your assertion is powered by your own incredulity.
Ridiculousness isn’t a natural kind. If you don’t want your opinion to matter, drop the “redeculous”!
Oh, and there’s no inconsistency between your number and the IPCC’s. Different calculations lead to different results. How you calculate all the energy everywhere just shows that you are new here, and don’t realize that the energy from the Earth core transfers to the surface very, very, very, very, very slowly. We should be thankful for that.
A big problem with this Vahrenholt and Dubal paper is the near absence of error analysis.
Why are there no error bars on the numbers in the Abstract?
None of the figures have error bars or uncertainty bands. Over only 20 years of data these are going to be large. None of the trends seem to take into account autocorrelation, making the uncertainties even larger over such a short period.
BTW Reviewer 2 points out this deficiency in his report.
The numbers in the Abstract don’t have error bars. Bad scientific practice, unacceptable in higher standard journals.
Table A1 gives the “Error” of the intercept and slope, but doesn’t say how they’re calculated or what they represent — one-sigma, two-sigma, 95% confidence limit, do they include autocorrelation, if so with what model? Again poor scientific practice.
Why weren’t these errors folded into the final numbers? Without them we really have no idea what the final numbers in the Abstract are or what they represent.
—
Finally, in the blog post, third paragraph, the authors cite a paper by Antero Ollila in “Physical Science International Journal.” Look at the laughable junk that’s also found in that journal:
Errors Related to General Relativity, Repulsive Gravitation and the Question of Black Holes
C. Y. Lo
Physical Science International Journal, Page 29-47
DOI: 10.9734/psij/2021/v25i330247
Published: 5 July 2021
Abstract
Galileo and Newton considered gravity to be independent of temperature, while Einstein claimed that the weight of metal will increase as temperature increases. Further, Maxwell maintained that charge is unrelated to gravity. Experiments show, however, that the weight of a metal piece is reduced as its temperature increases. Thus, charge-initiated repulsive gravitation exists. In fact, repulsive gravity has been demonstrated by the use of a charged capacitor hovering over Earth. Further, it is expected that a piece of heated metal would fall more slowly than a feather in a vacuum. Einstein developed an invalid notion of gravitational mass, and failed to establish the unification of gravitation and electromagnetism since he overlooked repulsive gravitation. Moreover, photons are a combination of the gravitational wave and the electromagnetic wave. For electromagnetic energy is invalid, and is in conflict with the Einstein equation. The non-linear Einstein equation has no bounded dynamic solution, Space-time singularity theorems are based on an invalid implicit assumption that all the couplings have a unique sign. Since gravity is no longer always attractive, the existence of black holes is questionable. The fact that Penrose was awarded the 2020 Nobel Prize in Physics for the derivation of black holes is due to that the Nobel Prize Committee for Physics did not sufficiently understand the physics of general relativity. A distinct characteristic of Penrose’s work, as usual, is that it is not verifiable.
Come on.
Average error bars for CERES measurements are of the order of 0.2 W/m2. The rest of David’s comment is piffle as well.
Robert I. Ellison wrote:
Average error bars for CERES measurements are of the order of 0.2 W/m2. The rest of David’s comment is piffle as well.
Someone completely failed to understand how science is done.
Not surprising.
David calls what he does science?
This is a quote:
You called me “nuts” when I told you that number didn’t account for the significant lag in the official recording of deaths.
Your refusal to just acknowledge your error is bizarre
Why is it so difficult for you? Inquiring minds want to know.
This is a quote to.
https://judithcurry.com/2021/10/10/radiative-energy-flux-variations-from-2000-2020/#comment-961817
He is nuts because of extreme obsessive repetitions of the same misrepresentations.
Robert I. Ellison commented:
David calls what he does science?
Why doesn’t the paper that is the topic of this original post have error bars on its results? Isn’t that proper science?
CERES is publicly available data. NASA doesn’t provide confidence limits on its products but the is very good nonetheless.
> This is a quote to[o].
That ain’t it, Chief.
Robert I. Ellison commented:
CERES is publicly available data. NASA doesn’t provide confidence limits on its products but the is very good nonetheless.
The point is, the Vahrenholdt and Dubal paper that is the topic of this post doesn’t provide confidence limits, as proper science must. That makes its claims worthless.
I’m amazed Judith ignored this. Willingly.
Get over your pompous self righteousness David. The paper does specify uncertainties.
I’m waiting to see “error bars” on the usual, always wrong, wild guesses of the climate in 100 years, that are smaller than +/- 50% range used with the unverified claim of +3.0 degree ECS, popular since the 1970’s, (and a foundation of all climate computer games that over predict the rate of global warming).
Leftist climate rule number one = the future climate can only get worse.
Leftist “solution” = You must do everything we say without question”
Leftist man of “science” = Mr. Appleman
A major snowstorm is approaching Rapid City.
https://www.accuweather.com/en/us/rapid-city/57701/weather-radar/330685
22″ fell
Thank you.
There are some very nice charts of what has happened to sunshine over Europe, since 1983, in the European State of the Climate report :
https://climate.copernicus.eu/ESOTC/2020
-Scroll down the page and click the ‘Clouds and sunshine duration’ link :-)
The data is incontrovertible. Low level cloud changes are traced to sea surface temperature variability in the eastern Pacific.
https://www.mdpi.com/climate/climate-06-00062/article_deploy/html/images/climate-06-00062-g002-550.jpg
https://www.mdpi.com/2225-1154/6/3/62
The source of variability is fluid dynamical shifts in spatiotemporal chaotic patterns in the global flow field.
e.g. https://pielkeclimatesci.wordpress.com/2011/03/07/a-new-view-of-the-climate-system-involving-spatio-temporal-chaos/
‘We are living in a world driven out of equilibrium. Energy is constantly delivered from the sun to the earth. Some of the energy is converted chemically, while most of it is radiated back into space, or drives complex dissipative structures, with our weather being the best known example.’ https://www.ds.mpg.de/LFPB/chaos
The math and science of spatiotemporal chaos is intriguing, key to understanding and predicting weather and climate but not yet up to describing the global fluid dynamic fractal flow field.
‘Weather and climate are manifestations of spatio temporal chaos of staggering complexity because there is not only Navier Stokes equations, but there are many more coupled fields. ENSO is an example of a quasi standing wave of the system…
You can see spatio-temporal chaos if you look at a fast mountain river. There will be vortexes of different sizes at different places at different times. But if you observe patiently, you will notice that there are places where there almost always are vortexes and they almost always have similar sizes – these are the quasi standing waves of the spatio-temporal chaos governing the river. If you perturb the flow, many quasi standing waves may disappear. Or very few. It depends.’ Tomas Milanovic
Navier-Stokes equations unpack into millions of equations at all scales from micro-eddies to planetary waves evolving as coupled global fluid dynamics. Hence fractal. Eyeballing one pattern or other – or simply handwaving at some piece of visualised data – may be one way to go. Although I doubt that it will lead to anything useful. There are simple rules at the heart of chaos but they do not provide certainty. Some humility in the face of staggering complexity may be in order.
Policy on the other hand is simple. We are driving the planet towards the next shift in global spatiotemporal pattern – with unforeseeable consequences. We can build resilient infrastructure, conserve and restore agricultural lands and ecosystem and deploy advanced nuclear fission engines.
https://watertechbyrie.files.wordpress.com/2015/12/ga-em2.jpg
RIE writes “We are driving the planet towards the next shift in global spatiotemporal pattern”.
If there is driving going on, how do we know if it is towards greater or less complexity? Geoff S
We are making changes to a dynamically complex system that has internal responses characteristic of such systems.
https://watertechbyrie.com/2014/06/23/the-unstable-math-of-michael-ghils-climate-sensitivity/
Robert I. Ellison wrote:
We are making changes to a dynamically complex system that has internal responses characteristic of such systems.
We?
Robert I. Ellison wrote;
The data is incontrovertible. Low level cloud changes are traced to sea surface temperature variability in the eastern Pacific.
LOL. The planet doesn’t go on a long-term pattern of absorbing more energy than it emits because clouds rearrange, without energy somewhere else decreasing.
Where is that somewhere else, “C-H-I-E-F?”
Closed marine stratocumulus cloud cells persist for longer over cooler oceans before raining out to leave open cells – increasing domain albedo.
e.g. https://aip.scitation.org/doi/10.1063/1.4973593
https://earthobservatory.nasa.gov/images/87456/open-and-closed-cells-over-the-pacific#:~:text=Closed%2Dcell%20clouds%20look%20similar,leaving%20the%20centers%20cloud%2Dfree.
https://watertechbyrie.files.wordpress.com/2014/06/clement-et-al-e1512080464744.png
https://watertechbyrie.files.wordpress.com/2018/03/clement-figure-3-e1618626575638.jpg
https://www.science.org/doi/abs/10.1126/science.1171255
This changes the energy reaching the planet. Duh.
Robert I. Ellison commented on Radiative energy flux variations from 2000 – 2020.
in response to David Appell:
Closed marine stratocumulus cloud cells persist for longer over cooler oceans before raining out to leave open cells – increasing domain albedo.
LOL you are so completely blind to cause and effect.
Stratospheric intrusion will bring snowstorms to North and South Dakota in the coming hours.
https://i.ibb.co/Bqbhd5h/gfs-hgt-trop-NA-f024.png
Perhaps the policymakers have gone too far in reducing the sulphur that was circulating in the Northern hemishphere’s atmosphere ?
https://ourworldindata.org/grapher/so-emissions-by-world-region-in-million-tonnes.
-By slaying one bogeyman they have allowed another to grow bigger(?)
This part is really weird:
“This contrasts with the assumption made by the IPCC in its most recent report that the warming caused by the increase in long-wave back radiation was due solely to the anthropogenic greenhouse effect. The IPCC attributes 100% of the warming to this effect and justifies this with model calculations.”
It’s very strange to imply that this data supports anything outside the IPCC reports. They’re explicit that low clouds are a big cause of the spread in ECS, and that means mostly shortwave cloud radiative effect.
Here’s a 2006 paper pointing this out.
https://journals.ametsoc.org/view/journals/clim/19/14/jcli3799.1.xml
The CERES results don’t seem surprising and the new Loeb paper does a great job of decomposing what’s going on.
The EUMETSAT cloud changes need further investigation – it seems like there’s a good chance it’s to do with inter-satellite, overpass time change or calibration issues more than anything though, doesn’t it?
From the Loeb et al 2021 paper.
‘We consider CERES TOA EEI trends for 09/2002–03/2020 and examine the underlying contributions from different atmospheric and surface variables available over that time period. Trends are determined from a least squares regression fit to deseasonalized monthly anomalies with uncertainties given as 5%–95% confidence intervals.
For this period, the observations show a trend in net downward radiation of 0.41 ± 0.22 W m−2 decade−1 that is the result of the sum of a 0.65 ± 0.17 W m−2 decade−1 trend in absorbed solar radiation (ASR) and a −0.24 ± 0.13 W m−2 decade−1 trend in downward radiation due to an increase in OLR.’ https://agupubs.onlinelibrary.wiley.com/doi/10.1029/2021GL093047
Comparing models to ERA20 about half of the surface warming of the past 40 years was caused by the radiative feedback of internal decadal variability.
https://www.nature.com/articles/s41612-018-0044-6
And that’s supposedly consistent with the IPCC?
The original post says:
“IPCC in its most recent report that the warming caused by the increase in long-wave back radiation was due solely to the anthropogenic greenhouse effect. The IPCC attributes 100% of the warming to this effect”
The blog sounds like it’s suggesting that warming caused by increased GHGs would only change net LW heating and not SW, right?
But *net* longwave mixes emissivity (“the greenhouse effect”) and warming. The Loeb et al. paper is much clearer IMO, Figure 3 shows +0.53 W m-2 heating from greenhouse effect changes and -0.56 W m-2 LW cooling from increased temperature.
And SW changes are expected from changes in clouds and water vapour too, which can be feedbacks and ultimately caused by GHG changes.
The interesting question is how much SW change is feedback and how much is variability. The IPCC have a whole section on this, to quote one part:
“In particular, changes in the global TOA radiative energy budget can be induced by changes in the regional variations of surface temperature, even without a change in the global mean temperature (Zhou et al., 2016; Ceppi and Gregory, 2019)”
Nothing you said supports your argument that rests on the idea that a very small amount can’t have a very big impact, Dmitry.
Chemists above all should know that it’s patently false.
“…FREEZE WARNING REMAINS IN EFFECT UNTIL 9 AM MDT /10 AM CDT/ THURSDAY…
* WHAT…Sub-freezing temperatures as low as 27 expected.
* WHERE…Portions of northwestern, south central and southwestern South Dakota. This includes the Tribal Lands of the Cheyenne River Reservation, the Pine Ridge Reservation and the Rosebud Reservation.
* WHEN…Until 9 AM MDT /10 AM CDT/ Thursday.
* IMPACTS…Frost and freeze conditions will kill crops, other sensitive vegetation.
PRECAUTIONARY/PREPAREDNESS ACTIONS…
Take steps now to protect tender plants from the cold. To prevent freezing and possible bursting of outdoor water pipes they should be wrapped, drained, or allowed to drip slowly. Those that have in-ground sprinkler systems should drain them and cover above- ground pipes to protect them from freezing.”
Let me formulate my argument in reverse. Let’s take IPCC radiative forcing for the last 100 years.
First let’s define the terms https://en.wikipedia.org/wiki/Radiative_forcing:
Radiative forcing is quantified in units of watts per square meter, and often summarized as an average over the total surface area of the globe.
The atmospheric burden of greenhouse gases due to human activity has grown especially rapidly during the last several decades (since about year 1950). The 50% increase (C/C0=1.5) for CO2 realized as of year 2020 corresponds to 2.5 W/m2.
So we have 2.5W/m2 constant addition of heat into atmosphere over 70 years or 2*10^9 seconds. Surface area of the globe 5*10^12 m2. So should be straight forward on how to count added heat. We get 1.6*10^24 Joules. But if on average the temperature increased by 1.5C it gives only 10^19 Joules (assuming IPCC definition of global warming). Something is wrong and someone is not consistent in their definitions and/or numbers. Imagine if all that perceived heat was actually stored in the atmosphere. We are toasted. Ok. Sometimes they jump to 0.6 W/m2 in their pictures, there is a lot of inconsistency. Still doesn’t help.
Even if we take ocean heat build up over the same period we get only 3*10^23 added heat. https://www.epa.gov/climate-indicators/climate-change-indicators-ocean-heat.
But if Ocean is the reason why this heat storage is not part of the energy balance equation that IPCC is using in forcing their 1.5C “predictions”.
I really do not understand why such inconsistencies are accepted by “97% consensus” .
What’s wrong is you have no idea what you are talking about.
What happens when you put a pot of water on the stove and you want the pot to boil? Let’s say you add heat equivalent to the latent heat of water for a particular steam rate. In your world the water should immediately start boiling and if it doesn’t then there is something wrong. In the real world that doesn’t happen. The water has to be brought to boiling temperature. That takes time. The system is in an unsteady state during that process. When a system is in an unsteady state things may not balance out. The system has inertia. When the system attains steady state everything balances out.
If a radiative forcing number is not zero, the earth is not at steady state. At steady state everything will balance out and the radiative forcing will be zero.
BTW unless something is keeping the radiative forcing at X it will decrease toward zero as the temperature rises. It’s your numbers that don’t add up.
I hope you are not distracted here. Please, go up and answer my reply to you previous arguments. It is more important there.
Unfortunately here, you immediately showing that you have problem distinguishing 2 processes: 1) evaporation and 2) boiling. First is the surface effect and second is the volumetric effect. I hope you do know that puddle on the street will disappear without a need of reaching boiling temperature.
But good that you talk about inertia. There are indeed different time constants for different processes happening on Earth after heat from the Sun is absorbed. Trying to claim balance between input and output is totally ridiculous in those scenarios.
But then you spoil everything with your steady state claim and ruin any hope.
“It’s your numbers that don’t add up.” – stop using theology. It is supposedly science here, not religion. Prove either that use wrong definitions or that I make wrong calculations. Why is it so difficult for you?
It’s true that if I just let let the pot sit there without heating it the water will evaporate. That’s not the point which you seem incapable of understanding.
“Trying to claim balance between input and output is totally ridiculous in those scenarios.”
Yet, there you are trying to make some point based on energies balancing out. Did you memorize that or is it something you read somewhere and have no clue what it means?
““It’s your numbers that don’t add up.” – stop using theology. It is supposedly science here, not religion. Prove either that use wrong definitions or that I make wrong calculations. Why is it so difficult for you?”
What’s that got to do religion? I already showed what you did wrong. Didn’t you understand it? The only things you have proved so far is that you don’t understand thermodynamics or the difference between steady and unsteady state. That doesn’t say anything about climate science, but says everything about you.
This is getting frustrating.
You are not able to debate beyond ad hominem, distractions and goal post movement. It is you who is incapable to understand basic thermodynamics it seems.
It was a very simple task for you, if you were a scientist. You just could check if my definitions that I took from IPCC are correct (Global Warming, Near-surface temperature, etc) and then verify that calculations didn’t have a mistake. You know that this is a beauty of science, definitions are fixed, assumptions clearly stated and values in questions are quantified. So that everyone can verify.
Unfortunately you prefer to debate like a priest based on mysticism and sacred knowledge. You mention the scientific terms but never elaborate the meaning that you specifically out inside them and you never make quantifiable predictions, so that anyone can assess validity of your statements. And if you are challenged you only defense that the opponent is reading scripture wrongly or you just run away from the argument. Quite pathetic actually. And making it pointless to debate.
So let’s go back to the beginning and ignore all your distractions. Let’s see if you can disprove 0.00001% finding that I’ve made. Then we can examine your knowledge of thermodynamics and radiative physics (like Kirchhoff law in regards water vapour in the atmosphere).
I use the glossary from IPCC’s website. Global warming is ” the estimated increase in global mean surface temperature (GMST) averaged over a 30-year period, or the 30-year period centered on a particular year or decade, expressed relative to pre-industrial levels unless otherwise specified”.
Now what is GMST: “Estimated global average of near-surface air temperatures over land and sea-ice, and sea surface temperatures over ice-free ocean regions, with changes normally expressed as departures from a value over a specified reference period. When estimating changes in GMST, near-surface air temperature over both land and oceans are also used”.
So after we clear definitions let’s assess Global Warming as a proxy for climate change. So IPCC tells us that the change in GMST over the last 100 years is 1.5C. Let’s estimate the heat gain in the near-surface air temperature (While IPPC is not clear on what they mean by near-surface, 2006 US governmental report on climate gives a table where near surface is confined to 25 m).
We know the surface area of the planet (510 million km2). We know density (1.2 kg/m3) and heat capacity (1 kJ/kgK) of air. So we can estimate the heat accumulated in those layers over 100 years: 2^19 Joules for near-surface air. This number will mean more if we have a reference to compare it to. And we have this reference, HOURLY energy input from the Sun is estimated at 4.8*10^20 Joules. 100 years is 876000 hours, so our total input is 4*10^26. So the total heat build up that we are supposed to worry about is >10^7 times smaller than the energy received by Earth in the same period of time.
Quit whining! It’ not my fault you don’t understand the science. BTW I’m not a chemist. I’m a chemical engineer.
Let me repeat. It doesn’t matter how small the radiative forcing is. Energy cannot be destroyed. Any value of radiative forcing > 0 will cause energy to accumulate on the planet.
You did an idiotic calculation where you took a radiative forcing said it was a constant over 70 years calculated the energy then compared that to the energy required to heat the planet and you claimed because they were different there was something terribly wrong with the IPCC report. One problem is that that if the radiative forcing is not 0, the system is not a steady state. The second problem, which I didn’t mention, is that you can’t assume radiative forcing is constant and certainly not over 70 years. If there is an energy imbalance the earth will drive it to zero. If you’re adding CO2 at the same time, it will be driving the radiative forcing higher. All the other greenhouse gases and solar radiation variation may impact the radiative forcing as well. CO2’s impact is non-linear. What that means is determining radiative forcing at any point in time is difficult, but you decided that it was constant over 70 years. That’s ridiculous.
Let’s look at the calculation you made in the post I’m replying. You seemed enamored with comparing big numbers to little numbers and claiming that the little numbers are too small to have an impact. What a crock! You took the total energy the earth absorbed over 100 years and compared that to the energy retained by the earth. Here’s your the problem with that “calculation” The earth doesn’t retain all the energy it absorbs from the sun. What affects the climate is the retained energy. That increases the internal energy of the planet, the temperature, etc.
Now let’s look back on your other “arguments”.
You whined about work not be included in the energy balance. It doesn’t need to be because you can’t do work into the vacuum of outer space.
Then you whined about potential energy not be included in the energy balance. It doesn’t have to be because no water crosses the earth system boundary. No matter how much water moves between the atmosphere and the earth potential energy balance has no impact on the energy balance.
Then you whined about photosynthesis not being taken into account. I said it was too small to impact the energy balance. When I was trying to find one of your posts, I found one post that, for some unknown reason, I didn’t receive. You asked why the small amount of energy for photosynthesis energy is insignificant but radiative forcing is significant. I already explained why even a small amount of radiant forcing is a problem.
Let’s look at an example. Let’s say photosynthesis subtracts 1 W/m2 from the solar radiation absorbed by the earth. Solar radiation absorbed is 240 W/m2. Input to earth’s energy balance from solar radiation and photosynthesis is 239 W/m2. Let the system come to equilibrium so the output from the energy balance is 239 W/m2. The difference in earth’s temperature between 240 and 239 W/m2 will be small. So will the difference between the amount of radiation that greenhouse gases can absorb. Introduce the greenhouse effect and lets say the back radiation is 1 W/m2. Now the input to the earth, not the energy balance is 240 W/m2. The output from the earth is still 239 W/m2 because the temperature of the earth initially is the same. The output from the earth’s energy balance is 238 W/m2. The initial radiative forcing is 1 W/m2. The radiative forcing increases the temperature of the earth putting out more radiation and decreasing the radiative forcing. At steady state the temperature of the earth is such that the earth outputs 240 W/m2 energy. The input to the energy balance is 239 W/m2. The input energy to the earth is 240 W/m2. The output energy from the earth is 240 W/m2. The output from the energy balance is 239 W/m2. Photosynthesis had little impact on the process, but radiative forcing drove the temperature of the earth higher.
The last item was the whether latent heat can convert to IR. I talked to a physicist friend this afternoon. His answer was no. The reason is that in order for water to condense kinetic energy has to be removed from the molecules in the vapor phase. In order to do that the surrounding molecules must have less kinetic energy than the water molecules. In order to generate IR the surrounding molecules must have more kinetic energy than the water molecules. There is no IR generated and what I originally said that evaporation-condensation has no impact on earth’s energy balance is valid.
That refutes all your “points”. Your principle problem is that you have a poor understanding of the science behind climate change. Then you make ridiculous assumptions and make up your own science to fit your conclusions. You then claim you have refuted climate science. This a typical approach taken by climate denialists.
BTW show me where I’m wrong about anything I said concerning thermodynamics. Don’t do what you usually do and make stuff up.
“BTW I’m not a chemist. I’m a chemical engineer”
Yes, indeed. This is what you originally claimed on October 11 and I was wrong to call you chemist. My fault.
“Let me repeat. It doesn’t matter how small the radiative forcing is. Energy cannot be destroyed.”
Let me repeat, that nowhere in my posts I claimed that energy can be destroyed. Your claims of the opposite are just sophistry. Actually most of your posts are pure sophistry.
“You did an idiotic calculation”
Good one. Not problem, I have acknowledge in the other posts how ridiculous are some/most of the explanations by “consensus scientists” to idiots like me.
” where you took a radiative forcing said it was a constant over 70 years calculated the energy then compared that to the energy required to heat the planet and you claimed because they were different there was something terribly wrong with the IPCC report One problem is that that if the radiative forcing is not 0, the system is not a steady state. The second problem, which I didn’t mention, is that you can’t assume radiative forcing is constant and certainly not over 70 years. If there is an energy imbalance the earth will drive it to zero. If you’re adding CO2 at the same time, it will be driving the radiative forcing higher. All the other greenhouse gases and solar radiation variation may impact the radiative forcing as well. CO2’s impact is non-linear. What that means is determining radiative forcing at any point in time is difficult, but you decided that it was constant over 70 years. That’s ridiculous.”.
This is a progress here, you are not against the comparisons of energy build up and radiative forcing, you are just not happy that I assumed it to be constant. It is shame that after such an outburst you decided not to help me with such an egregious mistake. Why wouldn’t you provide the correct value of radiating forcing? …….. I know that you cannot, that will require logical thinking. But I’ll help myself. Let’s use the following source: https://science2017.globalchange.gov/chapter/2/. Specifically we will use Figure 2.6. Time evolution of forcings. Indeed it is not constant. Let’s look at the period of interest from 1950 to 2020. And we will be kind and focus only on the red dotted line that represents purely anthropogenic Effective radiative forcing. In this period ERF is changing from ~0.6W/m2 to around 2.4W/m2. It is roughly linear, so we can just take an average, which will be 1.5W/m2. Do you really think that this helps your argument? ;)))))))))
“You seemed enamored with comparing big numbers to little numbers and claiming that the little numbers are too small to have an impact. What a crock! ”
Very mature, as usual.
“You took the total energy the earth absorbed over 100 years and compared that to the energy retained by the earth. Here’s your the problem with that “calculation” The earth doesn’t retain all the energy it absorbs from the sun. What affects the climate is the retained energy. That increases the internal energy of the planet, the temperature, etc.”
As usual you have serious lack in understanding thermodynamic problems or even general comprehension of reality. Climate of the planet encompasses multitude of energy intensive phenomena. To drive these phenomena 4.8*10^20 Joules of heat is supplied from the Sun each HOUR. What you are arrogantly suggesting is that 99.99999% of this heat is immediately re-radiated back to the universe and just the remaining 0.00001% is actually used to drive all the climate phenomena. It is mind blowing that people can have such dissonance between reality and their imagination. Which again confirms that you are the member of a religious cult. And there are so many of you.
“You whined about work not be included in the energy balance. It doesn’t need to be because you can’t do work into the vacuum of outer space.”
It is getting frustrating. But I probably see where you are struggling. We wrongly assigned the discussion of thermodynamic system to the whole planet. While IPCC defines Global Warming as heating up of the atmosphere? And thus thermodynamic system that they are exploring is purely the atmosphere. Maybe that will help you to finally understand. So now the heat from the Sun is supplied to this system. And the system is performing work on lifting water to high altitude. After precipitation water is not in the atmosphere, so it is not part of the atmosphere. It is an external object that work is performed on. And it is energy from the Sun that is used to perform this work.
I’ll skip the rest of your post, as it is pointless to discuss broad topics with cult members. I mistakenly assumed originally that you are scientist/engineer and thus, a meaningful discussion is possible on broad range of topics. My bad.
The 288 K – 255 K = 33 oC difference does not exist in the real world.
There are only traces of greenhouse gasses.
The Earth’s atmosphere is very thin. There is not any measurable Greenhouse Gasses Warming effect on the Earth’s surface.
There is NO +33°C greenhouse enhancement on the Earth’s mean surface temperature.
https://www.cristos-vournas.com
Radiative forcing is defined as the change in forcing assuming no planetary response. In the real world warming or cooling changes emissions exponentially. The negative Planck feedback drives the system to energy equilibrium at TOA. But the point of the post – that no one discusses – is that there are other things happening in the real world.
Speaking of the real world – there is a difference between surface temperature and the temperature of the atmosphere at the average height of emission.
Hey Dmitry,
Have you heard of the Planck Law or the Stefan-Boltzmann Law?
https://en.wikipedia.org/wiki/Planck%27s_law
https://en.wikipedia.org/wiki/Stefan%E2%80%93Boltzmann_law
As objects get hotter they emit more infrared radiation. You need to account for that in your calculations of heat uptake. The science used in the IPCC uses these laws.
MarkR,
What makes you feel that I’m unaware of Stefan boltzmann law?
You seem to be missing the difference between total heat accumulation in joules and dynamic heat flux in W/m2=(Joule/s)/m2.
If you flux disbalance is >1%, and as IPCC claims this disbalance goes into Global Warming, than the total accumulation of heat over 100 years should match that ratio. Why do they not match? I thought it is a very simple argument. Why so many people here have problem with following it?
Isakov Dmitry,
When heat goes into something it gets hotter. Hotter things emit more radiation, reducing the energy imbalance.
Your calculations assume that hotter things don’t emit more, so that’s why I didn’t think you’d heard of the Stefan-Boltzmann Law.
Try calculating atmospheric heat in and out after you add a radiative heating of some kind and include the S-B law. Calculate heat in/heat out every day and see what happens, keeping track of heat out and heat in at each timestep.
Visible north polar vortex blockage throughout the stratosphere.
https://www.cpc.ncep.noaa.gov/products/stratosphere/strat-trop/gif_files/time_pres_HGT_ANOM_OND_NH_2021.png
The start of winter will be unusual.
https://i.ibb.co/jMsXsBD/gfs-t30-nh-f00.png
Cloud temperature measured in the infrared. Cloud tops that reach the tropopause emit infrared radiation into space.
https://i.ibb.co/6Z8mw27/f67fc9df-f7f9-43b0-9da6-2fe2d86d8985.jpg
https://i.ibb.co/H4J6JYf/0b576520-c94e-4ad9-8bbf-1f72a20561b2.jpg
Clouds that manage to cross the polar vortex barrier in winter radiate the most infrared radiation into space. Therefore, every weakening of the polar vortex means a loss of heat in the overall balance of the Earth.
The goal is to end energy poverty. Right now the cheap energy reality is fossil fuels – with zilch taxes – with use of wind, solar, biomass or hydro resources. Cost competitive deployment of renewables is limited by technical practicalities. Of existing low carbon technologies – only advanced nuclear engines can provide sufficient energy for electricity, industrial processes and transport fuels into a high energy, high growth future.
https://watertechbyrie.files.wordpress.com/2015/12/ga-em2.jpg
‘1. Global electricity demand will more than double by 2050, with this growth almost entirely in emerging markets.
Over 90% of new demand by 2050 will be outside High-Income countries.
We identify 62 “Demand Engines,” which are countries whose electricity consumption will more than triple. Of those, 14 are in Asia, 35 in Africa, and none are in western Europe or North America.
2. These same fast-growing emerging markets are ready—or nearly ready—for advanced nuclear technology to help meet part of their future energy demand
37 countries (green) are ready for advanced nuclear power right now with an additional 11 countries (light green) potentially ready by 2030.
86% of new global electricity demand in 2050 is projected to occur in these green/light green countries.
By 2050, another 46 markets (yellow) could be ready for advanced nuclear technology if their governments continue to take preparatory steps.
3. The global market for nuclear power could triple by 2050
Based on conservative projections (20% of future demand in green markets, 10% in light green, and 5% in yellow), the total world market for nuclear power could triple to 7,500 TWH per year.
Under these conditions, new nuclear power could produce up to $400 billion worth of electricity annually.’
https://www.thirdway.org/memo/mapping-the-global-market-for-advanced-nuclear
Sorry – meant this for an earlier post.
Yes, the goal is to end energy poverty…
Question, is there enough uranium for doing so?
https://www.cristos-vournas.com
https://watertechbyrie.files.wordpress.com/2016/06/em2-summary-e1514320391410.png
https://watertechbyrie.files.wordpress.com/2016/06/em2-waste-reduction.png
https://watertechbyrie.files.wordpress.com/2014/06/em2-fuel-cycle.jpg
https://watertechbyrie.files.wordpress.com/2015/05/em2-cycle.jpg
Thank you for the Links.
To angech
I have no problem debating within your framework.
“CO2 is increasing.
CO2 produced by humans is increasing.
CO2 is one of the GHG
Temperatures increase with GHG increase.
If the temperature increases too much some of the consequences may be bad.
Now there is a framework to build a discussion on”
Yes. CO2 is increasing, as confirmed by multiple measurements. CO2 is produced by humans through breathing 24/7 :))) and through industrious activities. And rate of production is increasing exponentially. CO2 is indeed on of the GHG, even if Green house is a misnomer. Restricted convection is more critical in green houses. I worked with a Green house company that used PE sheets as roofing. PE is >80% transparent in LWIR but it was still very hot inside.
Temperatures increase with GHG increase. Yes in absolute terms but I have problems with quantification of this effect. That is what I was trying to do in my posts above. I take IPCC definition of Global warming due to GHG effect. Please notice that I’m not adding any new physics, just what is written in IPCC. You can check my analysis and if I made a mistake you should be able to point it out clearly. As of now, the ratio between Global Warming (calculated in Joules based on IPCC data) and heat input from the Sun
does not match the hypothetic ratio between GHG radiative forcing (calculated in W/m2) and the averaged heat flux from the Sun. At the same time IPCC claims that global warming is a results of flux mismatch, which in tern is the result of CO2 increase. Hence, if my calculations are correct the IPCC claim is invalid.
I also offer an alternative to CO2 explanation that removes the found discrepancy. But we can discuss it separately after you verify that my assessment of Global warming is correct.
Radiative forcing – some 3.7 W/m2 with feedbacks – is a hypothetical construct. Radiative forcing is defined as the change in forcing assuming no planetary response. In the real world warming or cooling changes emissions exponentially. The negative Planck feedback drives the system to energy equilibrium at TOA. But the point of the post – that you are not discussing – is that there are other things happening in the real world.
Greenhouse gases in the troposphere are subject to convection (this applies to moist air – a water vapor molecule is lighter than air) and mixing by wind (carbon dioxide, whose molecule is heavier than air). Of course, in the troposphere, the gases are well mixed, and the temperature decreases with pressure.
Greenhouse gases act very differently in the stratosphere, where they absorb ionizing UV and GCR radiation.
In the graphic below, it is clear that the troposphere heats up from the surface.
https://www.cpc.ncep.noaa.gov/products/stratosphere/strat-trop/gif_files/time_pres_TEMP_MEAN_ALL_NH_2021.png
Even if you put a thick layer of CO2 over the Arctic Circle in winter, the temperature still won’t rise.
Ireneusz Palmowski,
Can you clarify the point that you are trying to make? i’m not sure which point are you trying to address/argue in the original post.
Isakow Dmitrij I agree with you that an increase in CO2 doesn’t change much because it is still a trace gas and doesn’t affect air circulation in the upper troposphere (unlike water vapor).
Greetings.
So, now you’re claiming that CO2 can’t have an impact because it a trace gas. This is a old argument. How can CO2 with a concentration in the ppm have an impact on climate?
It’s really simple. The greenhouse effect doesn’t depend on a relative concentration term like ppm. It depends on an absolute concentration like moles/liter. It’s unfortunate that we equate the effect of CO2 on climate with ppm. Venus and mars both have atmospheres are 95% CO2. Venus has a massive greenhouse effect. Mars has little. the pressure on Mars is 0.06 ATM. The pressure on Venus is 90 ATM. Venus has a massive amount of CO2 in its atmosphere. Mars has little.
We could increase the ppm of CO2 in the atmosphere by removing the other gases and the impact of CO2 on climate wouldn’t change. You could make the atmosphere pure CO2 and the impact on climate wouldn’t change.
Noted. thanks.
Appreciate if you can actually look through the numbers that I provided in other posts and see if I make any make any mistake. Which is possible, but so far all the attack on me is not addressing issue at hand – IPCC has 2 contradicting descriptions of the same phenomenon.
And my second calculation that proper accounting of water cycle removes contradiction and at the same time removes the need for CO2 as the driving agent in climate change.
I have no problem of being found to be wrong, as long as valid arguments in disproving me are provided ;)
Regards
I think you checked your calculations several times. Although I studied math, actual observations are more important to me. I think people should worry more about arctic air attacks to the south during a low solar cycle that can destroy agricultural crops.
https://cosmicrays.oulu.fi/
Let’s look at the current ocean surface temperature. It is clear that it does not exceed 32 degrees C.
https://coralreefwatch.noaa.gov/data_current/5km/v3.1_op/daily/png/coraltemp_v3.1_global_current.png
JJBraccili | October 13, 2021 at 2:58 pm |
“1. Your correction for spherical planets is wrong. You use 0.47 the actual correction is 0.25. It’s already done when you divide the Stephan-Boltzmann equation by 4.”
The total “energy in” (W) is estimated as πr²*S – (SW reflected).
The (SW reflected) = (SW diffusely reflected) + (SW specularly reflected) (W)
The Φ(1 – a)πr²*S is the total not (SW reflected) portion of the incident on planet total solar energy (W).
Thus it is the portion of the energy which is the planet surface total outgoing IR emission EM energy.
It is not the same as in the case of using the factor 4 when refering to the entire sphere’s surface area…
https://www.cristos-vournas.com
You just make this stuff up as you go along, don’t you?
Isn’t the reflected sw radiation what the “a” term in your equation is for. Is this some type of reflected radiation that no one else knows about? Here I thought the reflected radiation was the albedo effect which we measure from the amount sw radiation in the earth’s radiant spectrum. Who knew???
The 4 factor accounts for the sun radiating to a flat plane. A sphere has more surface area and therefore the solar irradiation has to be corrected.
BTW in all the equations I’ve seen on absorbed solar radiation, I’ve never seen a correction like yours. So, what’s your source or did this come to you by divine inspiration?
Now you’ve explained it in two different ways. I’m pretty sure there will be a third explanation coming as soon as you think it up. Then another and another and another until you run out of explanations.
JJBraccili
“You just make this stuff up as you go along, don’t you?”
JJBraccili, I am not surprised, it is all so much new and unheard of for you. Nevertheless I have explained everything in my website, in the various different pages… It is all there.
You may also visit Ron Clutz’s blog “Science Matters”.
https://rclutz.com/2021/07/21/how-to-calculate-planetary-temperatures/
Ron has done a very good summary of my findings.
Thank you JJBraccili for your interest in my work. I am always willing to explain everything about the Planet Surface Rotational Warming Phenomenon.
https://www.cristos-vournas.com
JJBraccili | October 13, 2021 at 2:58 pm |
“2. What happens when solar radiation is incident on the planet surface is that the radiation is converted into kinetic energy. That causes the surface temperature to rise. Without an atmosphere that kinetic energy raises the surface temperature and conducts heat into the planet. That is a classic heat transfer by conduction problem. That requires the thermal conductivity. In a planet with an atmosphere you also have convection to the atmosphere.”
What happens when solar radiation is incident on the planet surface is that the (SW not reflected portion) radiation when interacting with planet’s surface gets transformed into a (LW outgoing from surface) IR EM radiation.
Only a very small fraction of the total incident on planet surface solar radiation is converted into kinetic energy.
The outgoing from planet surface IR EM energy is not being stored first as a heat and then emitted, it is IR emitted at the same very instant solar energy hits planet’s surface.
https://www.cristos-vournas.com
You need to read up on black body radiation. That doesn’t happen at all. All the energy the earth’s absorbs is converted to kinetic energy. It’s that energy that generates IR.
Your explanation is as nutty as your plant spin theory and nothing more than BS. You don’t want to deal with the conductivity problem. Why not make up your own science? You did it with your spin theory.
Here’s a video that should be titled black body radiation for dummies.
https://www.bing.com/videos/search?q=How+does+a+black+body+convert+solar+radation+to+kinetic+energy&docid=608051435221353392&mid=9338F50F9BB2855E73129338F50F9BB2855E7312&view=detail&FORM=VIRE
Because molecules in a solid can only vibrate (a form of kinetic energy) Solar energy absorbed makes the molecules vibrate and they emit a blackbody spectrum. Hence all the solar radiation absorbed is converted to kinetic energy.
JJBraccili
“Your explanation is as nutty as your plant spin theory and nothing more than BS. You don’t want to deal with the conductivity problem. Why not make up your own science? You did it with your spin theory.”
“Why not make up your own science? You did it with your spin theory.”
Thank you.
https://www.cristos-vournas.com
So what part of black body radiation don’t you understand? It seems like all of it.
JJBraccili
“You just make this stuff up as you go along, don’t you?”
I am not surprised, it is all so much new and unheard of for you. Nevertheless I have explained everything in my website, in the various different pages… It is all there.
You may also visit Ron Clutz’s blog “Science Matters”.
Ron has done a very good summary of my findings.
Thank you for your interest in my work.
Link to Ron Clutz’s blog page:
https://rclutz.com/2021/07/21/how-to-calculate-planetary-temperatures/
Willard | October 14, 2021 at 7:29 pm |
> Every effect carries both risk and reward,
You might prefer:
CO2 is increasing. CO2 produced by humans is increasing.
CO2 is one of the GHG Temperatures increase with GHG increase.
If the temperature increases too much some of the consequences may be bad. Now there is a framework to build a discussion on.
No need for a preference .
some of the consequences may be bad always carries a corollary inherent and implicit in it.
Which is , some of the consequences may be good.
That is what the word some is used for.
On the other hand some people only see gloom, despair and hopelessness as outcomes, missing the good outcomes.
That however is your burden, the one you and others gloomily bear and try to put on to everyone else as well.
Well I don’t buy it.
I want real scientific proof before putting one foot onto a slippery slope of misery and despair, thank you.
Instead of speculating about PREDICTED effects of adding more CO2 to the atmosphere in the future …
How about discussing the ACTUAL effects of the +100 ppm CO2 increase during the past 120 years?
The benefits versus the costs.
I can’t see that anyone, or anything,
has been harmed in any way.
The answer to your rhetorical question is simple, RG: One does not simply backcast future risks. Even frogs know that:
https://www.youtube.com/watch?v=APxGubAkOz0
It takes a special mind to be a Troglodyte.
Really? Tell that to the people in CA experiencing wild fires. Wild fire season used to be 4 months. Now it’s six. How about the people in China who experienced 29″ of rain in 24 hours. What used to be 100yr, 500yr, 1000yr extreme weather events are now commonplace.
Dumping CO2 into the atmosphere is one of the worst things you could do. It has the ability to wipe out all life on the planet. Keep on increasing CO2 in the atmosphere and the planet will become Venus. That’s the end point.
One of the critical proofs by IPCC of GHG hypothesis is the weighted correlation between different effects and average global temperature anomaly. And those correlation analysis always lead to the conclusion that increase in CO2 concentrations has the best match.
One can open ourworldindata.org and explore the graphs and notice how poor that correlation is.
Obviously there is a scaling problem. Why would anyone compare anomaly/variation against change in absolute numbers. By idea it should be change in absolute average temperate in Kelvin with both graphs having Y axis locked to 0. But ok, let’s ignore this manipulation.
Most common feature that is frequently noticed and debated is the flat lining between 1940s and 1980s. And this is how it is explained by “wise and enlightened” to “idiots” like me.
“The mid-century cooling APPEARS to have been largely due to a high concentration of sulphate aerosols in the atmosphere, emitted by industrial activities and volcanic eruptions. Sulphate aerosols have a cooling effect on the climate because they scatter light from the Sun, reflecting its energy back out into space.
The rise in sulphate aerosols was largely due to the increase in industrial activities at the end of the second world war. In addition, the large eruption of Mount Agung in 1963 produced aerosols which cooled the lower atmosphere by about 0.5°C, while solar activity levelled off after increasing at the beginning of the century”
The reason, why the unconfident word APPEARS is used, is because this effect was proven only by tweaking models, which are always correct until they are not but after small adjustments they are always correct again.
Can this explanation be true? Maybe yes, maybe not. Additional evidence to support sulphate hypothesis through eruption of Mount Agung is funny. As it happened in 1963, but the flat lining starts with the start of WW2. In regards industrial pollution, temperature was rising up to 1940s but then stops till 1980s. Global manufacturing recovered to pre-war levels by early 1950s and then expanded exponentially. Then how can this industrial aerosols be a solid argument.
And yes, apparently there was some data correction (UK vs US ships) that removed too sharp dip in temperature. I’m aware of it, in case someone wants to point it out. But the flat lining between 1940s and 1980s is still there even after correction.
Was this discussed on this blog earlier? If yes I can shift this comment to a more relevant post.
It is getting more and frustrating that climate science is showing all the traits of a religion, when priests quickly reinterpret the bible if inconvenient questions are asked about its absurdity. And zealots with burn you at he stake for daring not to believe. Scary times we live in
You should read the post I made to Quora a couple of years ago that discusses the science behind climate change. I show that climate change is real and CO2 is the cause.
https://www.quora.com/If-climate-change-is-a-hoax-why-do-so-many-scientists-say-its-happening?top_ans=155488291
The problem with the climate issue is not the science — that’s solid. The problem is people like you who don’t understand the science, but think they do. Then they feel compelled to display their ignorance for the world to see.
There will always be the dim-witted who will believe believe people like you. Get enough of them and the conspiracy theories start. That’s enough to prevent action on the real science until the pseudo science is exposed. Unfortunately, climate change is not the type of problem which will sort itself out. Action has to be taken.
It’s corrupt warmists (and the naive public who believe them) who don’t accept that climate change is real.
What????
“The problem with the climate issue is not the science — that’s solid.”
There are wide range of estimates in the anticipated rate of future warming and what may happen as a result of any warming which does occur. That is hardly solid science.
> It’s corrupt warmists (and the naive public who believe them) who don’t accept that climate change is real.
If only they had your wisdom and intelligence (let alone humility)….
Joshua,
If only… but it’s very difficult to get them to understand it when their salary depends upon them not understanding it. Cooling will do the trick though.
Cooling? You think we’re headed for another ice age? Good Luck with that!
JJBraccili
It really getting pointless to discuss anything with you. You seem to be incapable of logically following any argument and you love to claim you self-appointed superiority in some sacred knowledge without sharing and proving that you have it.
My post above was very specific. It was looking at the data provided by “consensus science”. Specifically flat-lining of temperature anomaly between 1940s and 1980s. “Consensus science” original models could not predict it. So they tweaked the model with aerosols. Tweaking in itself is not a problem. It is the amount of tweaking to the models that “consensus science” has to do that is getting suspicious. BECASUSE THE ONLY REAL PROOF THAT OF GLOBAL WARMING, AS YOU IMAGINE IT, ARE YOU MODELS.
In this particular example, sulphate aerosols are used to explain the data. I even say that it can be true. But what makes the explanation suspicious is that beyond the MODEL, the physical evidence was not matching the reality. The dates do not match. So yes, indeed, WHY DO SO MANY SCIENTISTS SAY IT IS HAPPENING? Are they really scientists or are they campaigners?
“The problem with the climate issue is not the science — that’s solid.”
This is a statement of a cult member not a scientists. It is impossible to prove that any science is “solid”. There can only be evidence in support of a particular theory. And while it is critical to have as much support for the theory as possible, even evidence against the theory makes it a “jelly” and not “solid” science. You seem to be incapable of grasping this concept. But there is no wonder, as we know you are a cult member, not a scientists.
Wow! I never saw anybody backpedal so fast and try to change the subject.
None of what you said in that post was true. No post you ever addressed to me contained anything about temperatures flatlining between 1940-1980. Nor did you ever say anything about the models.
We discussed items that you claimed were items that were left out of the earth energy balance by those evil climate scientists. You claimed that your “discoveries” proved climate science was a hoax. They involved the water cycle, potential energy, and work. None of which has any impact on earth’s energy balance. All you proved is that you don’t understand thermodynamics.
You haven’t addressed a single point I made. I wouldn’t if I were you either. It hard to imagine anything you would say that would be any dumber than what you already said. Let’s see if your dumb enough to try.
Then there was the two calculations you did which was suppose to point up discrepancies in the IPCC report. In one calculation you didn’t take into account the inertia of the earth. Even more egregious was your assumption that the radiative forcing is constant over a 70 year period. Where’s your source for that assumption? You don’t have any. You just decided to do it because it conformed with the conclusion you wanted. Of course, you chose the largest radiative forcing to use because that just strengthened the case you wanted to make.
The second calculation you demanded I comment on was even more ridiculous than the first. You wanted to compare the total amount of energy that the earth absorbed from the sun with the retained or accumulated energy by the earth and because the retained energy is a lot less than the absorbed energy this proves climate change is a hoax? The retained energy has everything to do with climate change. The amount of solar energy that passes through the earth has nothing to do with climate change. An apple and orange comparison.
Do you want to answer for any of that? I guess not; because now you want to change the subject. Now you are demanding that I account for temperature flatlining between 1940-1980. Okay.
Take a look at the my post on Quora and look at the graphs. From 1940-1960 temperature change tracks solar irradiance. From 1960 on it tracks with CO2 ppm. We didn’t start dumping massive amounts of CO2 into the atmosphere until 1950. The reason for the lag is inertia.
I don’t know what data your looking at but I haven’t seen any that shows any flatlining of temperature change data after 1960. Generally, when climate denialists starting quoting numbers out of the IPCC report, they are cherry-picked.
I never mention the models and I don’t use them to prove climate change is happening and CO2 is the cause because I don’t have to. My opinion of the models is they understate the peril and we need to stop using fossil fuels long before what IPCC recommends.
Yes, you can say science is solid. I’d say the Laws of Thermodynamics, Relativity, Newton’s laws of motion are pretty solid.
I’m not a cultist. I understand the science. It’s not my fault you don’t.
Isakov has misunderstood radiative forcing. As I have said twice now. And fails to understand that natural variability on any scale including decadal does not falsify the observed – not modeled – physics of greenhouse gases.
https://www.atmos.washington.edu/~dennis/321/Harries_Spectrum_2001.pdf
JJBraccili
You should read the post I made to Quora a couple of years ago that discusses the science behind climate change.
I show that climate change is real and CO2 is the cause.
–
You are commenting on a blog where the view expressed is uncertainty on the science of climate change.
Perhaps you would be better taking those points into consideration.
Climate change occurs all the time, nothing new.
CO2 changes might effect the climate, big deal.
Nail your colors to the mast and declare clearly what you actually mean .
As in terrible humans cause nasty things only to happen to the world by making CO2 that nothing else is responsible for that will last in the air for millions of years and kill civilization as we know it plus all life on earth and all children through incredibly high rates of warming.
That is what you mean, I guess, unless you care to narrow it down a bit?
> BECASUSE THE ONLY REAL PROOF THAT OF GLOBAL WARMING, AS YOU IMAGINE IT, ARE YOU MODELS.
As a ninja, Dmitry, all I can say is that you’re a gift that keeps on giving:
https://climate.nasa.gov/evidence/
to Robert I. Ellison
“Isakov has misunderstood radiative forcing. As I have said twice now. And fails to understand that natural variability on any scale including decadal does not falsify the observed – not modeled – physics of greenhouse gases.”
Said twice to whom? What did I misunderstand? Why can’t you people be more specific? Where did I deny that physics of greenhouse gasses? What natural variability has to do with it?
You people should really humble down and contain your arrogance.
My argument is not that GHG do not exists or that they have no effect in the climate. My argument is that CO2 is a fine tuning mechanism, while most of climate phenomena is driven by water cycle. And there is many orders of magnitude difference in impact. And if water cycle is the primary driver, isn’t it logical that disbalance in climate is likely a consequence of a disbalance in water cycle. Isn’t it also logical to look if human activity caused disturbance to the cycle? It is obvious that we did, and we have means to correct those actions. But all those actions has nothing to do with CO2 concentration control.
As I said, you are becoming unhinged.
The water cycle has NO impact on earth’s energy balance as I have shown. No impact on earth’s energy balance, no impact on climate.
I looked up an article that will explain it to you.
http://www.atmo.arizona.edu/students/courselinks/fall16/atmo336s2/lectures/sec1/water.html
I know you badly want water’s latent heat to leave the atmosphere as IR, but that doesn’t happen.
“The water cycle has NO impact on earth’s energy balance as I have shown. No impact on earth’s energy balance, no impact on climate.”
This is getting fun. This is brilliant beyond anything I could imagine. You seriously claim that water cycle has no impact on climate. ;))))))))))
Now let’s look at your link that you provided. Are you sure it is supporting your claim that water cycle has no impact on climate? They are quite melodramatic about the importance of that cycle ;)))))))
This is obviously a lecture for school kids. Maybe you should try grown up staff some times. The do say about large quantities of energy transferred from surface to troposphere by evaporation. And source of energy is clear – Sun. unfortunately they are not quantifying the amount of energy, which makes it useless for our discussion.
But even worse they make the same not-smart claim as you like to do. I see why you like them.
“Rising air currents carry water vapor up into the atmosphere, which cools the air, causing the water vapor to condense into tiny droplets of liquid water (or tiny ice crystals), forming clouds. This process, condensation (gas to liquid), releases energy up in the atmosphere where clouds form.”
What is the mechanism of loosing energy “up in the atmosphere” by water vapour? Condensing is a very hard process in terms of energy transfer. The reason why air-conditioning is so energy hungry is that we use compression in order to achieve meaningful condensation. And even after compression we need large area condensers to get anything done. Now up in the troposphere, not only we lack compression, we get an opposite effect. Pressure is dropping. Making condensation even harder, e.g. drop in temperature of surrounding air is not helping due to the simultaneous drop in pressure. And yeah, we can blame school program for misleading so many people about the process.
Now let’s examine your logic or lack off. You state that water vapour looses energy to surrounding air. From you description you obviously imply conduction. Let’s ignore the fact that air has poor heat capacity and low thermal conductivity (both drops with pressure), which makes heat transfer very inefficient. But let’s assume that this is what happens, where does this energy go? Most of the molecules around are Nitrogen and oxygen. Those on itself cannot loose energy by radiation. So they will need to then, according to you, find CO2 molecule, which in tern will loose the energy by radiation. Such a complex process. Or, maybe, I know heretical though, but listen, what if Occam’s razor was useful, and there is a simpler explanation.
And oh miracle, they is such explanation. We just use a common knowledge even for “consensus science” that water vapor is the largest contributor to the Earth’s greenhouse effect. On average, it probably accounts for about 60% of the warming effect. This means that water vapour is a strongest IR absorber in the atmosphere. Then we use such scientifically established (really solid) facts called Kirchhoff’s law of thermal radiation and conclude that if water vapour is a good absorber it is equivalently good emitter. And or miracle, doesn’t it mean that even in “consensus science” they know that most if IR radiation from the top of the troposphere into the universe is actually accomplished by energy release from water vapour, not from CO2.
I know, it might be hard for you to swallow, but even consensus science say that you need to study the subject a bit more and stop saying stupid things like : “I know you badly want water’s latent heat to leave the atmosphere as IR, but that doesn’t happen.”
Now, in our water cycle discussion, all we need to do is just a small step further. When water vapour releases energy by radiation it fulfills the condition necessary for condensation, as long as it can find surface to attach to. Now water is changing phases back into liquid. Through this process most of the energy from the Sun was removed from the surface of the planet preventing it from overheating and as a biproduct we’ve got large chunk of the potential energy to drive the multitude of processes on the planet. If you were careful reader you will also notice that to accomplish this process only 1-2% of total mass of water vapour in the atmosphere is sufficient. The rest does not require loss of energy by radiative means at the top of the atmosphere. And more detailed analysis will require a much deeper understanding of what is actually the latent heat. Specifically it will require the knowledge (not taught at your level) about the different in Maxwell-Boltzmann distributions for gases and liquids.
Hint, the distribution as actually given for fluids in general. But to use it correctly you will have to think about what is the difference between gas and liquid and ignore erroneous notion that you were taught in school about that difference.
“This is getting fun. This is brilliant beyond anything I could imagine. You seriously claim that water cycle has no impact on climate. ;))))))))))”
YES!!!!!!!!!!!!!!!!! The water cycle impacts weather – not climate. Why am I not surprised you don’t know the difference.
This is going to be fun, but not for you. Putting you and the word “brilliant” in the same sentence as you is an oxymoron.
“This is obviously a lecture for school kids. Maybe you should try grown up staff some times. The do say about large quantities of energy transferred from surface to troposphere by evaporation. And source of energy is clear – Sun. unfortunately they are not quantifying the amount of energy, which makes it useless for our discussion.”
I chose this material because it’s the only material you have a chance of understanding. The amount of energy transferred between evaporation and condensation could be a gazillion TW, and it still wouldn’t impact the Earth’s energy balance.
“What is the mechanism of loosing energy “up in the atmosphere” by water vapour? Condensing is a very hard process in terms of energy transfer. The reason why air-conditioning is so energy hungry is that we use compression in order to achieve meaningful condensation. And even after compression we need large area condensers to get anything done. Now up in the troposphere, not only we lack compression, we get an opposite effect. Pressure is dropping. Making condensation even harder, e.g. drop in temperature of surrounding air is not helping due to the simultaneous drop in pressure. And yeah, we can blame school program for misleading so many people about the process.”
Let’s test your BS hypothesis.
The dewpoint – the point at which water condenses – occurs when the partial pressure of water in the atmosphere equals the vapor pressure of water. At the top of the troposphere the pressure is 4.06 psia, and the temperature is -55 C. The atmosphere is 1-3% water vapor. Let’s split the difference and use 2%. The partial pressure of water is 0.02 * 4.06 = 0.08 psia. From the steam tables the dewpoint temperature of water is 0 C. At low pressure, the troposphere is more than capable of condensing water vapor in the atmosphere.
Guess those school programs aren’t misleading people after all. You definitely need to sign up for a course.
“Now let’s examine your logic or lack off. You state that water vapour looses energy to surrounding air. From you description you obviously imply conduction. Let’s ignore the fact that air has poor heat capacity and low thermal conductivity (both drops with pressure), which makes heat transfer very inefficient. But let’s assume that this is what happens, where does this energy go? Most of the molecules around are Nitrogen and oxygen. Those on itself cannot loose energy by radiation. So they will need to then, according to you, find CO2 molecule, which in tern will loose the energy by radiation. Such a complex process. Or, maybe, I know heretical though, but listen, what if Occam’s razor was useful, and there is a simpler explanation.”
I didn’t imply anything. Heat transfer from H2O molecules to surrounding molecules is by forced convection.
The energy transfer from H2O molecules to surrounding molecules is a kinetic energy or sensible heat transfer. Radiation has NOTHING to do with it, and there is nothing more simple than that.
“And oh miracle, they is such explanation. We just use a common knowledge even for “consensus science” that water vapor is the largest contributor to the Earth’s greenhouse effect. On average, it probably accounts for about 60% of the warming effect. This means that water vapour is a strongest IR absorber in the atmosphere. Then we use such scientifically established (really solid) facts called Kirchhoff’s law of thermal radiation and conclude that if water vapour is a good absorber it is equivalently good emitter. And or miracle, doesn’t it mean that even in “consensus science” they know that most if IR radiation from the top of the troposphere into the universe is actually accomplished by energy release from water vapour, not from CO2.”
So all the latent heat is magically converted into IR? By what mechanism does that happen? I know the energy fairy does the conversion. Latent heat is stored as kinetic energy. The only way kinetic energy is converted into vibrational kinetic energy is by collision with other molecules. The bulk of those molecules are N2 and O2. N2 and O2 molecules would have to have higher kinetic energy than the H2O molecules for an energy transfer. The N2 and O2 molecules would have to transfer the exact amount of kinetic energy equal to the latent energy. All of that energy would have to go to vibrational energy and not to translational and rotational energy. The IR would be released, and kinetic energy from the H2O molecule would have to replace the energy lost by the N2 and O2 molecules for this to work. I’m pretty sure this is impossible and would violate the second law of thermodynamics somewhere in the process. Simple it is not.
There are some other problems with this scenario. Where does the energy come from for thunderstorms, hurricanes, and tornadoes? If all the latent heat winds up as IR leaving the Earth, what about the energy deficit on the planet? All of this started with evaporation on the surface of the Earth, and that energy is now gone. I don’t know how significant the number is, but I think it will be noticeable.
What happens is that surrounding molecules of lower kinetic energy cause the transfer of kinetic energy from the H2O molecules. This energy is transferred to other molecules in the atmosphere. The speed of transfer is controlled by the kinetic energy of the surrounding molecules. If the kinetic energy gets too high, condensation slows or stops until conditions are suitable for condensation. Since energy transfer is to the surrounding molecules, no additional IR is produced by H2O molecules. It is more likely that vibration energy is transferred from H2O molecules resulting in less IR from H2O molecules.
“Now, in our water cycle discussion, all we need to do is just a small step further. When water vapour releases energy by radiation it fulfills the condition necessary for condensation, as long as it can find surface to attach to. Now water is changing phases back into liquid. Through this process most of the energy from the Sun was removed from the surface of the planet preventing it from overheating and as a biproduct we’ve got large chunk of the potential energy to drive the multitude of processes on the planet. If you were careful reader you will also notice that to accomplish this process only 1-2% of total mass of water vapour in the atmosphere is sufficient. The rest does not require loss of energy by radiative means at the top of the atmosphere. And more detailed analysis will require a much deeper understanding of what is actually the latent heat. Specifically it will require the knowledge (not taught at your level) about the different in Maxwell-Boltzmann distributions for gases and liquids.”
That is ridiculous. What are you going to do? Collect the water in the atmosphere and drive a turbine with the potential energy? The latent heat is kinetic energy period.
You have nothing, and all you do is keep saying the same things repeatedly despite being shown your “theories” are junk science. You need better junk science. Without a doubt, this is the dumbest discussion I’ve had on climate change.
I’m still waiting for a reply to all arguments I made discrediting your “theories”. I must conclude you don’t have any. All you’re doing is trolling this board.
JJ
It is getting really awkward. You should probably stop.
“YES!!!!!!!!!!!!!!!!! The water cycle impacts weather – not climate. Why am I not surprised you don’t know the difference.”
This climate vs weather is a very common talking point of of “consensus science” trolls that sit on the debate forums to attack anyone that questions your religion. Do you have a brochure with those? I don’t understand why all of you like it so much and try to put regardless if it is relevant or not.
Here the explanation from NASA for you
https://science.nasa.gov/earth-science/oceanography/ocean-earth-system/ocean-water-cycle
” This cycling of water is intimately linked with energy exchanges among the atmosphere, ocean, and land that determine the Earth’s climate and cause much of natural climate variability.”
I don’t need to even anything else.
Will not copy here your whole dew point analysis here. Great job. You get “A” for your school project of evaluating closed box scenario. Unfortunately for you atmosphere is not a closed box controlled by dew point.
Here is a read for you. https://journals.ametsoc.org/view/journals/clim/27/19/jcli-d-14-00255.1.xml
You will be surprised to see and maybe learn, that in tropics where evaporation triggered by Sun input is highest, Humidity is nearly constant through the whole atmosphere and varies between 70 and 90%. Never reaching dew point condition. Amazing, isn’t it. It reaches 100% only at 15 km for the models. In actual atmosphere it is different, but you might be surprised on how they explain this behavior:
“At a height of 11 km, the RADIATIVE COOLING and associated subsidence lead to a halving of the relative humidity ”
Should be mind-blowing. Even worse they call it Radiative-Convective Equilibrium .
“There are some other problems with this scenario. Where does the energy come from for thunderstorms, hurricanes, and tornadoes?”
I’ll give you a scenario. You are a petty criminal after t shipwreck. You floating on a small raft in the middle of the ocean fried by an unforgiving Sun. Due to heat from Sun ocean around you is obviously evaporating and at height rate. But with your world view, you should not worry. This evaporated water should go up and quickly condense into cloud and provide you with shading. So you should not worry with making any shade of your own. ;)))) RIP.
Now, thunderstorms and hurricanes are indeed gaining energy from latent heat transfer from evaporated water. You are right. But here is your home task, what is the different in scenario when they receive that boost vs the scenario when you are fried on your raft?
“I’m still waiting for a reply to all arguments I made discrediting your “theories”. I must conclude you don’t have any. All you’re doing is trolling this board.”
Which theories? In which post? Most of your statement do not amount to theories. Theories have to be falsifiable. Quoting scripture is not useful in the scientific debate.
If you want to complain, you should first at least admit that you screwed up with mixing posts and then wrongly accused me of trying to ” backpedal so fast and try to change the subject”. You made a silly mistake of answering in the wrong thread of posts. Nothing much, happens. Own it.
Actually, I waste too much time on you. Is it really worth it? It is impossible to convince religious zealots.
““YES!!!!!!!!!!!!!!!!! The water cycle impacts weather – not climate. Why am I not surprised you don’t know the difference.”
This climate vs weather is a very common talking point of of “consensus science” trolls that sit on the debate forums to attack anyone that questions your religion. Do you have a brochure with those? I don’t understand why all of you like it so much and try to put regardless if it is relevant or not.”
I misspoke I should have said climate change and not climate. I was laughing too hard at your post. In fact. the first time I read a post of yours I spend the first 5 minutes laughing. I find myself looking forward to them.
If we took away the water cycle today would the climate change? Of course! If water vapor started drifting off into space, we’d have a problem. Last I checked water is being evaporated in the oceans, and condensed in the atmosphere. The rising temperatures due to climate change causes more evaporation and condensation which cause more extreme weather events. The changes in the water cycle are due to climate change — not the cause.
Then there is your idiotic theory that through some unknown mechanism the latent heat of water is being converted into IR and radiated into space and that’s what is making up earth’s long wave radiant profile. The spectrographs of earth’s radiant energy shows no such thing.
Now let’s talk about your NASA reference. Once again, you demonstrate your reading comprehension skills are abysmal.
I think you would agree the following is the key paragraph:
“This cycling of water is intimately linked with energy exchanges among the atmosphere, ocean, and land that determine the Earth’s climate and cause much of natural climate variability. The impacts of climate change and variability on the quality of human life occur primarily through changes in the water cycle. As stated in the National Research Council’s report on Research Pathways for the Next Decade (NRC, 1999): “Water is at the heart of both the causes and effects of climate change.””
The common definition of climate change is a permanent long term change in climate. The key phrase is in the first sentence “NATURAL climate variability. The sun does not warm the earth evenly. The water cycle isn’t uniform across the planet. It’s the reason we have variability in climate across the planet. That says nothing about long term changes in climate which are NOT caused by the water cycle.
The key phrase in the second sentence is “The impacts OF climate change” What that says is climate change causes the water cycle to change and that affects climate. Of COURSE!!!!!!!!!! What it doesn’t say is that changes in the water cycle causes climate change.
In the third paragraph it says that “WATER” not the water cycle is at the heart of both the causes and effects of climate change.” OF COURSE!!!!!!!!! Water is a greenhouse house. As CO2 causes the temperature of the earth to rise, there is more water in the atmosphere which increases its greenhouse effect. You need water to have a water cycle. I’m saying that because you may not have realized it.
Let’s talk about my dew point calculation. You were trying to justify your idiotic latent heat direct to IR theory by saying that water vapor condensation couldn’t occur by sensible heat transfer because the pressure drops with height in the atmosphere and the temperature where water condenses goes lower with pressure drop. All I did was a dew point calculation at the top of the troposphere taking into account atmospheric pressure. The dewpoint temperature was well above the atmospheric temperature at the top of the troposphere. Condensation can occur in the troposphere by sensible heat transfer. The point you were trying to make is BS.
“You will be surprised to see and maybe learn, that in tropics where evaporation triggered by Sun input is highest, Humidity is nearly constant through the whole atmosphere and varies between 70 and 90%. Never reaching dew point condition. Amazing, isn’t it. It reaches 100% only at 15 km for the models. In actual atmosphere it is different, but you might be surprised on how they explain this behavior:
“At a height of 11 km, the RADIATIVE COOLING and associated subsidence lead to a halving of the relative humidity ”
Should be mind-blowing. Even worse they call it Radiative-Convective Equilibrium”
Never gave it much thought to what happens to the latent heat after it transferred by sensible heat transfer. If that energy is disposed by radiant heat transfer, so be it. I have already proven that latent heat can only be removed by sensible heat transfer to the surrounding molecules. Molecules can only generate IR by photon absorption and kinetic energy transfer. Only greenhouse gas molecules are capable of IR production. The latent heat energy is transferred to them and they radiate it. They will radiate it in all directions some will get radiated back to earth.
Your original claim was that the water cycle will have an impact on earth’s energy balance. Even if the latent heat is transferred by radiation, it won’t. Here’s why. Let’s start with the earth in energy balance absorbing 240 W/m2. Let’s say 1 W/m2 is being evaporated and condensed. The earth’s surface is emitting 239 W/m2 to account for the loss of energy from evaporation. In the atmosphere 1 W/m2 is added to the earth’s radiant energy output because of condensation. That makes 240 W/m2 in an out. The earth remain in energy balance. No energy accumulation. No impact on climate change. The only scenario where the water cycle would impact climate change is if water vapor were drifting off into outer space. Of course, you’d have a much bigger problem than just an energy imbalance.
Your example of a criminal in a shipwreck is stupid. I never claimed that evaporated water goes up in the atmosphere and immediately condenses. If the atmospheric conditions are suitable it could. Eventually it will. It’s called an unsteady state. Apparently, you learned nothing from the example I provided.
“Now, thunderstorms and hurricanes are indeed gaining energy from latent heat transfer from evaporated water. You are right. But here is your home task, what is the different in scenario when they receive that boost vs the scenario when you are fried on your raft?”
They’re gaining energy from sensible heat transfer from condensing water. It would be a neat trick if they could gain energy from evaporated water. Only in your world can that happen.
“Which theories? In which post? Most of your statement do not amount to theories. Theories have to be falsifiable. Quoting scripture is not useful in the scientific debate.”
How about mostly all of your theories in all your posts. Is the First Law of Thermodynamics is a religion? Where do I sign up? Does violation of the First Law of Thermodynamics not falsify your arguments? You pretty much trash it in every post.
You are hopeless. I’m done arguing with people that have rudimental understanding a basic physics.
Here is good description of you condition.
The Dunning-Kruger effect is a type of cognitive bias in which people believe that they are smarter and more capable than they really are. Essentially, low ability people do not possess the skills needed to recognize their own incompetence. The combination of poor self-awareness and low cognitive ability leads them to overestimate their own capabilities
I’m done talking to you. Hopeless.
What no answers? Hard to answer when your peddling junk science?
Wait till you read my 4 part answer to your other posts. Your going to like it even less. Your just another fraud that is now exposed. I’ve dealt with a lot better than you.
I said in my last post:
“The latent heat is kinetic energy period.”
That is wrong. The liquid and vapor during the vaporization/condensation are at the same temperature and the same kinetic energy.
You said:
“And more detailed analysis will require a much deeper understanding of what is actually the latent heat. Specifically it will require the knowledge (not taught at your level) about the different in Maxwell-Boltzmann distributions for gases and liquids.”
I know what Maxwell-Boltzmann distributions are. It is not above my “level”. It is certainly is above yours because it has nothing to do with latent heat, but it does sound good and makes you “appear” that you know what you are talking about.
What exactly is latent heat? Why does a pure liquid boil at a constant temperature. I researched it. Amazingly, there isn’t one good explanation. When I first learned about it, it was how to use it. Until now, I just used it and didn’t think about it.
Here what happens when you boil a pure liquid. A liquid is a liquid because there are forces of attraction between molecules that hold the molecules close to each other. Think of them as chemical bonds but weaker. The best example is hydrogen bonding between water molecules. You apply heat that increases the kinetic energy of the liquid. The molecules of the liquid move faster and when they collide the collisions are more energetic. You keep heating the liquid and you reach a point where the collisions are so energetic that the bonds are at the point of breaking. The next incremental amount of heating increases the kinetic so the bonds start breaking. Breaking the bonds requires energy which comes from the kinetic energy of the molecules. That energy is the latent heat. As the bonds break all the energy you add makes up for the kinetic energy that was used to break the bond. The actual kinetic energy of the molecules remains constant and so does the temperature.
The only thing that prevents the molecules from separating was the bonds. At the kinetic energy level of the liquid the molecules should be much further apart. With the bonds gone the molecules separate to a point in line with average kinetic of the liquid. The density drops and the vapor phase forms. The kinetic energy and the temperature of the vapor are the same as the liquid.
In condensation the reverse happens. Remove heat from the vapor to take kinetic energy from the molecules. The molecules move closer. Eventually the molecules are close enough to reform the bonds. The bonds reform at constant kinetic energy (temperature). The latent heat is taken from the liquid’s kinetic energy and the added heat keeps the kinetic energy of the liquid constant. The molecules draw close together, the density increases, and the liquid phase forms.
That all happens with sensible heat transfer. There is no IR radiation involved and never will be. This theory, like all your theories and calculations, is BS.
“Here what happens when you boil a pure liquid. A liquid is a liquid because there are forces of attraction between molecules that hold the molecules close to each other. Think of them as chemical bonds but weaker. The best example is hydrogen bonding between water molecules. You apply heat that increases the kinetic energy of the liquid. The molecules of the liquid move faster and when they collide the collisions are more energetic. You keep heating the liquid and you reach a point where the collisions are so energetic that the bonds are at the point of breaking. The next incremental amount of heating increases the kinetic so the bonds start breaking. Breaking the bonds requires energy which comes from the kinetic energy of the molecules. That energy is the latent heat. As the bonds break all the energy you add makes up for the kinetic energy that was used to break the bond. The actual kinetic energy of the molecules remains constant and so does the temperature.”
HAHAHAHAHAHAHAHAHAHAHHAHAHAHAHAH
You are a school pupil. Stay there. This is not what happens in liquids. School physics really screwed up a lot of people on this topic. I even gave you a hint on Maxwell-Boltzmann distribution. It is applicable to liquid and you would be surprised (oh the magic of the real world) that even at room temperature there is a finite probability for molecules in liquid water to have speed close to 1000 m/s. And this is those molecules that are responsible for evaporation. That is why the puddle on the street does not need to boil in order to disappear.
Ok. we are done here. You should be ignored from now on. You do not even know the difference between evaporation and boiling. Face palm.
Reading comprehension is not your strong suit.
Where in what I posted did I say anything about evaporation? The piece was on latent heat.
That piece was in response to what you said:
“And more detailed analysis will require a much deeper understanding of what is actually the latent heat. Specifically it will require the knowledge (not taught at your level) about the different in Maxwell-Boltzmann distributions for gases and liquids.”
What you said is that latent heat is dependent on differences between Maxwell – Boltzmann distributions of gases and liquids. Apparently, you don’t know that latent heat is a property of a chemical species.
Whose laughing now?
Let’s talk about Maxwell-Boltzmann distributions. If you have a mixture of air and liquid water it’s not surprising that a “speedy” molecule could brake the air liquid interface. It’s more likely that the “molecule strikes another molecule at the air-liquid interface and “pushes” that molecule into the vapor phase. Either way the intermolecular bonds have to be broken. That’s not inconsistent with what I said.
It doesn’t work so well for condensation. What happens if no liquid phase exists? A “speedy” molecule of H2O can’t create a liquid phase.
Maxwell-Boltzmann distributions were developed for gases. A liquid is a whole different animal. A lot more molecular collisions in a liquid. I suspect the distribution is a lot flatter.
Instead of running away, why don’t you try addressing my points refuting your BS theories and calculations. Based on your track record, it’s highly unlikely you’ll say something intelligent But, who knows? Even a blind squirrel finds an acorn once in awhile.
I’m tired of demonstrating that you do not know basic concepts. And in contrast to you, I demonstrate it using proper references to scientific literature. Stop relying on rudimental understanding that you have about science.
Try scientific debate for a change. And stop running away from subjects when you are shown to be wrong, like moisture profiles in the atmosphere. and more importantly the basic fact that radiative transfer from Earth in to universe is based on IR radiation from water vapour, so called the most potent GHG. READ IPCC AT LEAST.
In regards, different in Maxwell-Boltzmann distributions between gas and liquid, the main aspect is activation energy. It has similarity to chemical reactions indeed, except for difference in consequences.
In any case, I was recommended this blog as a platform with some reasonable debate culture. This is not. I’m done wasting time here. Will ignore at least you 3.
I replied to the last post you sent to me, but for some reason it wasn’t posted. I wonder if there is a length limit on posts. It wouldn’t let me post it again. I posted to a post you made not addressed to me. Hopefully that will work.
“I’m tired of demonstrating that you do not know basic concepts. And in contrast to you, I demonstrate it using proper references to scientific literature. Stop relying on rudimental understanding that you have about science.”
Really? Said the guy who thought work could be done into the vacuum of space. What basic concepts do I not know? What references? Most of what you post is your BS theories and calculations. When anyone points out your errors, you just ignore what they say and keep posting the same nonsense.
“Try scientific debate for a change. And stop running away from subjects when you are shown to be wrong, like moisture profiles in the atmosphere.”
I never run away from anything and I always admit if I make a mistake. The exact opposite to your behavior. I have plenty to say about your last post. You’re not going to like it when you read it.
“and more importantly the basic fact that radiative transfer from Earth in to universe is based on IR radiation from water vapour, so called the most potent GHG. READ IPCC AT LEAST.”
Here goes that BS theory that what we see at TOA is radiation from water vapor. So CO2 plays no role? It’s benign? What happened to the energy that doesn’t show up under the 15 mm CO2 absorption band on earth’s IR spectrograph:
https://earthzine.org/wp-content/uploads/2013/12/6.1.jpg
Here what an IR spectrograph from water looks like:
https://webbook.nist.gov/cgi/cbook.cgi?ID=C7732185&Type=IR-SPEC&Index=1#IR-SPEC
Does the actual spectrograph look like the spectrograph of water? The actual spectrograph looks like a radiation profile of a blackbody. The spectrograph of the water doesn’t. Why do you think that is? It’s because water is NOT a blackbody.
Right now water is not the most potent GHG — CO2 is. The amount of CO2 in the atmosphere is increasing and the only reason the amount of H2O in the atmosphere is increasing is because of CO2 raising the planet’s temperature. It’s CO2 that’s driving climate change.
“In regards, different in Maxwell-Boltzmann distributions between gas and liquid, the main aspect is activation energy. It has similarity to chemical reactions indeed, except for difference in consequences.”
You think latent heat is like an activation energy? It’s not. You recover activation energy . Latent heat is like a heat of reaction. You supply it when you vaporize and you get it back when you condense.
“In any case, I was recommended this blog as a platform with some reasonable debate culture. This is not.
What you were looking for was a forum that would agree with your nutty “theories”. You should try and publish this garbage in a real scientific journal and see how far you get.
“I’m done wasting time here. Will ignore at least you 3.”
Promises! Promises! That would be wonderful. You’ll become my punching bag.
You are pathetically hopeless
https://airs.jpl.nasa.gov/mission/overview/
“It comes as a surprise to many, but water vapor is the most dominant greenhouse gas in the Earth’s atmosphere. It accounts for about 60% of the greenhouse effect of the global atmosphere, far exceeding the total combined effects of increased carbon dioxide, methane, ozone and other greenhouse gases.”
Yes. Surprise indeed. We are witnessing one here. Just go back to school and stop bothering grown ups
So CO2 has no impact? What happened to the energy under the CO2 15 mm absorption in earth’s IR spectrograph? Did the energy fairy eat it? I know you’re aware of the energy fairy because some of your “theories” rely on her. She lives at the North Pole with Santa, the Easter Bunny, and the Great Pumpkin.
Whose running away now? Answer the questions! Respond to the points.
Does CO2 cause climate change or not?
Do you believe activation energy is the same as latent heat?
Why doesn’t the IR spectrograph of water match the IR spectrograph of the earth?
The questions are based on your statements. Defend yourself or stop posting nonsense.
to JJ,
Hm. My long post didn’t go through and disappeared, probably it was too long. So much effort wasted. Ok Will try again. Probably will split into several.
Let’s start with your last statement:
‘The questions are based on your statements. Defend yourself or stop posting nonsense.”
I have no problem defending myself. My arguments are based on clear definitions, stated assumptions and supported by relevant references. Unfortunately you are not able to match the grown up conversation and use some childish arguments. And the worst part is you attribute statements to me that I never made. It is just information filtered and twisted by your framework. That is why you often argue with what you imagine I said and not what I actually said.
“So CO2 has no impact? What happened to the energy under the CO2 15 mm absorption in earth’s IR spectrograph? Did the energy fairy eat it?”
When did I say that CO2 has NO effect? I always clearly stated that CO2 is a GHG. The thing is that it is not anywhere as critical as often claimed. You were given multiple sources of this argument from IPCC, NASA, NOAA etc. But you just refuse to see. Maybe I can give you something from less scientific source where it is digested for general public. Here is what Forbes is reporting https://www.forbes.com/sites/marshallshepherd/2016/06/20/water-vapor-vs-carbon-dioxide-which-wins-in-climate-warming/?sh=43bcc7d63238
‘If, for instance, CO2 concentrations are doubled, then the absorption would increase by 4 W/m2, but once the water vapor and clouds react, the absorption increases by almost 20 W/m2 — demonstrating that (in the GISS climate model, at least) the “feedbacks” are amplifying the effects of the initial radiative forcing from CO2 alone” Even most ardent supporters of consensus science do not claim that CO2 is the main driver. They claim that it is the trigger, but most of Radiative Forcing is done my water vapour in the atmosphere.
“Does CO2 cause climate change or not?” CO2 is a fine tuning mechanism for climate that helps to get certain optimal conditions but it is not responsible for the big changes that we see right now. It is disbalance to the water cycle that drives the main potent phenomena broadly described as climate change.
“Do you believe activation energy is the same as latent heat?” Again you attribute to me things that I didn’t say. What I was explaining to you is that latent heat during evaporation (not boiling) is governed by activation energy. Maxwell-Boltzmann distributions are valid for all fluids, not just gases. When you plot M-B for liquid water and for water vapour the shape will be generally the same, just shifted. But liquid water distribution will have a distinct kinetic energy value, called activation energy. Molecules that have translational kinetic energy above activation energy can escape the surface. Activation energy in thermodynamic system is not directly related to chemical bonds, as you claim, but only to the surface tension. And surface is the primary distinguishing property between gasses and liquids. Unfortunately school education confused generations of students regarding this fact, with stupid stronger chemical bonds in liquids.
“Why doesn’t the IR spectrograph of water match the IR spectrograph of the earth?” – Counter question. Why would you bring up the spectrograph of liquid water into discussion? It is very clearly stated there: Condensed Phase Spectrum. In the Notes to the spectrum they even give details:
LIQUID (NEAT); DOW KBr FOREPRISM-GRATING; DIGITIZED BY NIST FROM HARD COPY (FROM TWO SEGMENTS); 4 cm-1 resolution.
You obviously not understanding how massive is absorption spectrum from water vapour. You can use here for rough comparison. https://www.e-education.psu.edu/meteo3/sites/www.e-education.psu.edu.meteo3/files/images/lesson5/absorptivity_wv.png
In your spectrograph for the Earth you are clearly not noticing H2O on both sides of the peak. And seems to be hard for you to estimate relative impacts. But if you read proper sources from NASA or even IPCC, you will find that they quantify it to >60% of the total absorption.
In the next post I will ask the questions of my own.
‘Said twice to whom? What did I misunderstand? Why can’t you people be more specific? Where did I deny that physics of greenhouse gasses? What natural variability has to do with it?’
It you are discovering new science – it is always useful – as Feynman said – to check your assumptions. And I expect ably designed experiments and more sophisticated quantitative analysis. Hence the need for referencing authoritative sources and real science. Instead we have from both sides the fallacy of relying on their own negligible authority.
https://judithcurry.com/2021/10/10/radiative-energy-flux-variations-from-2000-2020/#comment-961488
If they cannot get the simple bits right – what hope for the interesting stuff – dynamical complexity and perpetual change? Or even clouds?
Robert,
I’m not discovering any new science here. I take the existing science and assumptions provided by IPCC and make a quantitative estimates of energies involved.
“Hence the need for referencing authoritative sources and real science.’
What you seem to be missing here is that I’m referencing to the most authoritative source in the subject of climate change – IPCC report. I also use the formula for heat capacity of near-surface air, but I assumed that is a basic and fundamentally established formula that does not require additional references. You are all got to full of your self in your arrogance. You need to humble down. All my discussion is within the framework (assumptions, definitions, actual measured data) of what you call “climate science”, no new concepts are introduced. I only show that there is a self-contradictory conclusions within your framework
All I’m doing is comparing the Global Warming (as defined by IPCC) measured in Joules based on the measurements of averaged temperature anomaly (it is not my assumption, this is based on definitions from IPCC) to other known values.
First, is the obvious contradiction, when same Global Warming is calculated using effective radiative forcing (disbalance in radiative transfer). There is many orders of magnitude mismatch there. While minor details can be lost in such estimate the general value should at least be within the order of magnitude.
Second, is a huge different between Global Warming value and the average heat input from the Sun. While the total heat input from the Sun has obvious and strong effect on the climate phenomena every hour, it is strange that value that is 0.00001% of that input gets so much attention. It is illogical.
And only as final part of my argument, I offer water cycle as a mechanism that can match Sun input in order of magnitude. Anthropogenic destructive impact of that cycle is obvious and easily observed. And while the total impact is hard to measure (mainly because no one is trying with so much resources diverted to CO2), it is clear that 1% disturbance will have huge ramifications and disbalance to the whole climate system. And it is a very high probability that this is what we observe now. The problem is that huge resources are placed into mitigating CO2 and not on repair the damage to the water cycle (independent of CO2 concentration).
Tell me again how you use the radiative forcing concept to invalidate something or other to do with the global energy balance.
Hi Robert,
“Tell me again how you use the radiative forcing concept to invalidate something or other to do with the global energy balance”
Again you are twisting my word a bit. But ok. Let’s just put the argument here. I’ll use the following source that is linked to IPCC https://science2017.globalchange.gov/chapter/2/. I’m using Figure 2.6 Time Evolution of Forcing. Let’s also just consider anthropogenic Effective Radiant Forcing (ERF). From 1900 the value increased form roughly 0.5 W/m2 to 2.4 W/m2. At least this is what I see from this graph. The slope is linear, so mean and average are roughly the same values. So for cumulative effect over that period we get roughly 1.5W/m2. The assumption by IPCC we can conclude that this ERF is causing Global Warming. Now, the averaged heat flux from the sun (according to IPCC) is 240 W/m2, so extra heat that stayed on Earth due to this forcing is 0.6% of the average heat input from the Sun, correct.
Now, next step. We take definition of Global Warming from IPCC (I use their Glossary). Global warming is ” the estimated increase in global mean surface temperature (GMST) averaged over a 30-year period, or the 30-year period centered on a particular year or decade, expressed relative to pre-industrial levels unless otherwise specified”. Now what is GMST: “Estimated global average of near-surface air temperatures over land and sea-ice, and sea surface temperatures over ice-free ocean regions, with changes normally expressed as departures from a value over a specified reference period. When estimating changes in GMST, near-surface air temperature over both land and oceans are also used”. So after we clear definitions let’s assess Global Warming as a proxy for climate change. So IPCC tells us that the change in GMST over the last 100 years is 1.5C. Let’s estimate the heat gain in the near-surface air temperature (While IPPC is not clear on what they mean by near-surface, 2006 US governmental report on climate gives a table where near surface is confined to 25 m).
We know the surface area of the planet (510 million km2). We know density (1.2 kg/m3) and heat capacity (1 kJ/kgK) of air. So we can estimate the heat accumulated in those layers over 100 years: 2^19 Joules for near-surface air. This number will mean more if we have a reference to compare it to. And we have this reference, HOURLY energy input from the Sun is estimated at 4.8*10^20 Joules. 100 years is 876000 hours, so our total input is 4*10^26. So the total heat build up that we are supposed to worry about is 0.00001% of the heat input from the Sun.
So based on heat flux values provided by IPCC we get a value of 0.6% of energy input trapped in Global Warming. At the same time based on the definition of global warming through temperature anomaly we get a value of 0.00001%. Both cannot be true at the same time.
Just to preempt. One argument against my assessment of the discrepancy is to say that most of the heat goes into the ocean.
But first of all it is not me who made definitions by IPCC. They are specifically not including it. They also do not add this storage component in the heat flux calculations that establish radiative forcing. I really do not understand why they prefer to leave their arguments incomplete.
Second, the worming in the ocean also does not match ERF. Here is the paper that NOAA is referring for their data in ocean warming. https://www.ncei.noaa.gov/data/oceans/woa/PUBLICATIONS/grlheat12.pdf
The warming is is 0.4W/m2 for top 2000 m of the ocean and 0.27W/m2 for total ocean volume for period between 1950-2012. Period between 1900 to 1950 would increase this value but still will be smaller than 1.5W/m2. The remaining should then stay in the atmosphere and we again end up with many orders of magnitude mismatch.
Finally, I offer alternative that removes the discrepancy in energy balance analysis if water cycle is properly accounted for. The issue comes that when water cycle is accounted for the true issue of climate change becomes clear and it has little to do with CO2 concentration. And now if CO2 part is removed from the discussion it is revealed that we are spending huge resources on solving wrong problem (130$ trillion on renewables ;)))).
‘Again you are twisting my word a bit.’
No saying that you compare radiative forcing to a surface increase is apt and shows that you misunderstand basic and fundamental concepts.
‘But ok. Let’s just put the argument here. I’ll use the following source that is linked to IPCC https://science2017.globalchange.gov/chapter/2/. I’m using Figure 2.6 Time Evolution of Forcing. Let’s also just consider anthropogenic Effective Radiant Forcing temperature (ERF). From 1900 the value increased form roughly 0.5 W/m2 to 2.4 W/m2. At least this is what I see from this graph. The slope is linear, so mean and average are roughly the same values. So for cumulative effect over that period we get roughly 1.5W/m2. The assumption by IPCC we can conclude that this ERF is causing Global Warming. Now, the averaged heat flux from the sun (according to IPCC) is 240 W/m2, so extra heat that stayed on Earth due to this forcing is 0.6% of the average heat input from the Sun, correct.’
W/m2 is a power flux – heat is in Joules mostly as heat gained from a power flux over time in oceans. If the energy imbalance at TOA in a period is positive the world warms and power flux and energy out exponentially increases. Heat gained is the Earth Energy Imbalance (EEI) – and not the change in radiative forcing.
‘Now, next step. We take definition of Global Warming from IPCC (I use their Glossary). Global warming is ” the estimated increase in global mean surface temperature (GMST) averaged over a 30-year period, or the 30-year period centered on a particular year or decade, expressed relative to pre-industrial levels unless otherwise specified”. Now what is GMST: “Estimated global average of near-surface air temperatures over land and sea-ice, and sea surface temperatures over ice-free ocean regions, with changes normally expressed as departures from a value over a specified reference period. When estimating changes in GMST, near-surface air temperature over both land and oceans are also used”. So after we clear definitions let’s assess Global Warming as a proxy for climate change. So IPCC tells us that the change in GMST over the last 100 years is 1.5C. Let’s estimate the heat gain in the near-surface air temperature (While IPPC is not clear on what they mean by near-surface, 2006 US governmental report on climate gives a table where near surface is confined to 25 m).’
The surface temperature is nominally measured in standardised enclosures at 2m. Most of the global energy content – some 90% – is in oceans with some terrestrial surface heat content and latent heat in liquid and water vapor. The surface temperature change may be caused by global warming but the numerical comparison to radiative forcing is insupportable.
‘We know the surface area of the planet (510 million km2). We know density (1.2 kg/m3) and heat capacity (1 kJ/kgK) of air. So we can estimate the heat accumulated in those layers over 100 years: 2^19 Joules for near-surface air. This number will mean more if we have a reference to compare it to. And we have this reference, HOURLY energy input from the Sun is estimated at 4.8*10^20 Joules. 100 years is 876000 hours, so our total input is 4*10^26. So the total heat build up that we are supposed to worry about is 0.00001% of the heat input from the Sun.’
If the surface is warming so are oceans and land along with melting ice and increased water vapour.
‘So based on heat flux values provided by IPCC we get a value of 0.6% of energy input trapped in Global Warming. At the same time based on the definition of global warming through temperature anomaly we get a value of 0.00001%. Both cannot be true at the same time.’
Both are false and based on an inadequate understanding of simple radiative physics concepts. Let alone of the staggering complexity of the climate system. Both of you are wasting our time.
Robert, don’t be like this. Why do you have to be that irrational?
Fine let’s explore your arrogance.
“W/m2 is a power flux – heat is in Joules mostly as heat gained from a power flux over time in oceans” You should have been a bit smarter to understand that when I take proportion between stored energy vs input energy the area and time parts in the flux will negate each other and it will be just Joules divided by Joules. What, even algebra need to be explained? Face palm
“Heat gained is the Earth Energy Imbalance (EEI) – and not the change in radiative forcing. ”
Let’s check our definitions https://council.science/current/news/where-does-the-heat-go-a-new-report-on-the-earth-energy-imbalance/:
The Earth Energy Imbalance (EEI), is described as the difference between the amount of energy from the sun arriving at the Earth and the amount returning to space.
https://www.climate.gov/maps-data/climate-data-primer/predicting-climate/climate-forcing:
“Incoming Energy – Outgoing Energy = Radiative Forcing”
Definitions are equivalent. You obviously assume something more under EEI. But is it really my fault or the fault of self-contradicting ‘consensus science” that cannot keep its story straight. The problem that you all have is that you bring the term Global Warming and profess that “Global warming occurs when carbon dioxide (CO2) and other air pollutants collect in the atmosphere and absorb sunlight and solar radiation that have bounced off the earth’s surface. Normally this radiation would escape into space, but these pollutants, which can last for years to centuries in the atmosphere, trap the heat and cause the planet to get hotter”. You literally have an imbedded definition of RF or EEI inside the term Global Warming.
That is why you are laughing stock of science, if you are not even able to be clear about your definitions and assumptions. That is why you have little credibility, you are a cult and demand submission based on believes not understanding. And I would petty you but your behavior is similar to Roman inquisition in middle ages, and all have to fear you instead. And you just rely that majority of the public will not bother to read your “holy scriptures”.
The weakest part of the whole house of card is the forced link between the term Global warming (defined though global average temperature anomaly) and CO2 concentration. This is the link that is critical to make money out of this topic. I know that by EEI you are trying to imply heat accumulated on Earth that is currently estimated at 3.6*10^23 Joules. You are for some reason incapable of expressing yourself clearly, nothing new among your crowd.
The problem for you is that while accumulated heat is real it is disconnected from your radiant heat balance equation. What you all forget is that timescales of different phenomena cannot be average in your simplified form. Also Sun light is not absorbed at the surface of the Ocean but penetrates down to 1000 m and only then heat can start travelling upwards.
However, a bigger problem for you is that the measured heat gain on earth can be much better accounted for by considering disruption to the water cycle, instead of radiative forcing. But solving disbalance in water cycle would actually be much cheaper than carbon trading and renewable energy craze. So you are wishfully blind to it. Let’s hope that current energy crisis will really hit your lot hard to the level of full discredit among general public will be achieved. Fingers crossed.
You asked and and I gave you simple and concise responses. It is just as an instance simply not heat flux – it is power flux. It is a matter of getting the terminology right to precisely define the concepts. And then you go into a full blown contrarian meltdown.
Robert, why do you want to emberras yourself even further?
“You asked and and I gave you simple and concise responses. It is just as an instance simply not heat flux – it is power flux. It is a matter of getting the terminology right to precisely define the concepts. And then you go into a full blown contrarian meltdown.”
https://www.hukseflux.com/products/heat-flux-sensors/heat-flux-meters
There are definitions and tools used by us real scientists to explore the world the way it is. For example this one is called Heat Flux Meter and it measures exactly what I’m talik g about in W/m2.
Unfortunately the Internet is full of armchair scientists like you with Wikipedia level of just conceptual understanding. And you are used as an angee mob to hunt down heretics.
Do I have a meltdown? Maybe I did overreact. Didn’t expect the vile welcome on this blog, as it was recommended to me as more balanced one. But gate keepers like YOU, WILLARD and JJ went berserk on me. I should have been smarter and ignored you.
I corrected your misunderstanding of radiative forcing and elements of radiative physics and you take it as an affront and mount silly attacks based on misguided stereotypes. I suggest you get your act together before trying again.
Learn how to debate with evidence. WIthout relying to accusations that opposing party just doesn’t know the subject as good as you and thus, it is beneath you to explain further. Humble down and people might start liking you.
Amazing how out of three of you, none is using any proper references to scientifically established facts. Just shows the level of crowd I’m dealing with here.
‘Incoming Energy – Outgoing Energy = Radiative Forcing’
Radiative forcing is determined from the change in concentration of greenhouse gases – inter alia – in the atmosphere relative to a reference point. Commonly 1750 or 1850.
The real world energy imbalance is due to forcing and feedbacks – including clouds, water vapour, lapse rate and the Planck feedback. The change in planetary heat and work is equal to energy in less energy out in a period.
d(W&H) = Ein – Eout
Completely different concepts.
Robert,
You are hopeless.
I provided you with definitions from IPCC, NASA, NOAA and so on. We even established that you do not know basic concept, like heat flux. I have a strong suspicion that you do not even know what is temperature.
I provide the exact definitions that I use, explain the assumption and even give exact calculation that lead to the my conclusions. You know, the way the scientific debate is done.
And in response I get only that I’m wrong, and the only evidence that I’m wrong, according to Robert I. Ellison, is that Robert I. Ellison thinks that I’m wrong.
Don’t you see how stupid you sound? Really pathetic and hopeless.
I give you the distinction between radiative forcing and energy imbalance that can be found in any textbook. These are the simplest ideas at the foundation of climate science.
http://www.dgf.uchile.cl/~ronda/GF3004/pie09.pdf
And you behave like a troll and a bore.
““YES!!!!!!!!!!!!!!!!! The water cycle impacts weather – not climate. Why am I not surprised you don’t know the difference.”
This climate vs weather is a very common talking point of of “consensus science” trolls that sit on the debate forums to attack anyone that questions your religion. Do you have a brochure with those? I don’t understand why all of you like it so much and try to put regardless if it is relevant or not.”
I misspoke I should have said climate change and not climate. I was laughing too hard at your post. In fact. the first time I read a post of yours I spend the first 5 minutes laughing. I find myself looking forward to them.
If we took away the water cycle today would the climate change? Of course! If water vapor started drifting off into space, we’d have a problem. Last I checked water is being evaporated in the oceans, and condensed in the atmosphere. The rising temperatures due to climate change causes more evaporation and condensation which cause more extreme weather events. The changes in the water cycle are due to climate change — not the cause.
Then there is your idiotic theory that through some unknown mechanism the latent heat of water is being converted into IR and radiated into space and that’s what is making up earth’s long wave radiant profile. The spectrographs of earth’s radiant energy shows no such thing.
Now let’s talk about your NASA reference. Once again, you demonstrate your reading comprehension skills are abysmal.
I think you would agree the following is the key paragraph:
“This cycling of water is intimately linked with energy exchanges among the atmosphere, ocean, and land that determine the Earth’s climate and cause much of natural climate variability. The impacts of climate change and variability on the quality of human life occur primarily through changes in the water cycle. As stated in the National Research Council’s report on Research Pathways for the Next Decade (NRC, 1999): “Water is at the heart of both the causes and effects of climate change.””
The common definition of climate change is a permanent long term change in climate. The key phrase is in the first sentence “NATURAL climate variability. The sun does not warm the earth evenly. The water cycle isn’t uniform across the planet. It’s the reason we have variability in climate across the planet. That says nothing about long term changes in climate which are NOT caused by the water cycle.
The key phrase in the second sentence is “The impacts OF climate change” What that says is climate change causes the water cycle to change and that affects climate. Of COURSE!!!!!!!!!! What it doesn’t say is that changes in the water cycle causes climate change.
In the third paragraph it says that “WATER” not the water cycle is at the heart of both the causes and effects of climate change.” OF COURSE!!!!!!!!! Water is a greenhouse house. As CO2 causes the temperature of the earth to rise, there is more water in the atmosphere which increases its greenhouse effect. You need water to have a water cycle. I’m saying that because you may not have realized it.
Let’s talk about my dew point calculation. You were trying to justify your idiotic latent heat direct to IR theory by saying that water vapor condensation couldn’t occur by sensible heat transfer because the pressure drops with height in the atmosphere and the temperature where water condenses goes lower with pressure drop. All I did was a dew point calculation at the top of the troposphere taking into account atmospheric pressure. The dewpoint temperature was well above the atmospheric temperature at the top of the troposphere. Condensation can occur in the troposphere by sensible heat transfer. The point you were trying to make is BS.
“You will be surprised to see and maybe learn, that in tropics where evaporation triggered by Sun input is highest, Humidity is nearly constant through the whole atmosphere and varies between 70 and 90%. Never reaching dew point condition. Amazing, isn’t it. It reaches 100% only at 15 km for the models. In actual atmosphere it is different, but you might be surprised on how they explain this behavior:
“At a height of 11 km, the RADIATIVE COOLING and associated subsidence lead to a halving of the relative humidity ”
Should be mind-blowing. Even worse they call it Radiative-Convective Equilibrium”
Never gave it much thought to what happens to the latent heat after it transferred by sensible heat transfer. If that energy is disposed by radiant heat transfer, so be it. I have already proven that latent heat can only be removed by sensible heat transfer to the surrounding molecules. Molecules can only generate IR by photon absorption and kinetic energy transfer. Only greenhouse gas molecules are capable of IR production. The latent heat energy is transferred to them and they radiate it. They will radiate it in all directions some will get radiated back to earth.
Your original claim was that the water cycle will have an impact on earth’s energy balance. Even if the latent heat is transferred by radiation, it won’t. Here’s why. Let’s start with the earth in energy balance absorbing 240 W/m2. Let’s say 1 W/m2 is being evaporated and condensed. The earth’s surface is emitting 239 W/m2 to account for the loss of energy from evaporation. In the atmosphere 1 W/m2 is added to the earth’s radiant energy output because of condensation. That makes 240 W/m2 in an out. The earth remain in energy balance. No energy accumulation. No impact on climate change. The only scenario where the water cycle would impact climate change is if water vapor were drifting off into outer space. Of course, you’d have a much bigger problem than just an energy imbalance.
Your example of a criminal in a shipwreck is stupid. I never claimed that evaporated water goes up in the atmosphere and immediately condenses. If the atmospheric conditions are suitable it could. Eventually it will. It’s called an unsteady state. Apparently, you learned nothing from the example I provided.
“Now, thunderstorms and hurricanes are indeed gaining energy from latent heat transfer from evaporated water. You are right. But here is your home task, what is the different in scenario when they receive that boost vs the scenario when you are fried on your raft?”
They’re gaining energy from sensible heat transfer from condensing water. It would be a neat trick if they could gain energy from evaporated water. Only in your world can that happen.
“Which theories? In which post? Most of your statement do not amount to theories. Theories have to be falsifiable. Quoting scripture is not useful in the scientific debate.”
How about mostly all of your theories in all your posts. Is the First Law of Thermodynamics is a religion? Where do I sign up? Does violation of the First Law of Thermodynamics not falsify your arguments? You pretty much trash it in every post.
NASA is correct – but Isakov has confused radiative forcing for energy imbalance and instead of clarifying the physics for himself behaves abominably.
New evidence from Robert I. Ellison. Let’s hope that finally he will share his sources and provide logical explanations……..
Ah. Neh… It is the Usual crap. e.g., Robert Ellison is right because Robert Ellison is right.
I’m done with you. Hopeless case
These are simple notions covered in any textbook on climate.
http://www.dgf.uchile.cl/~ronda/GF3004/pie09.pdf
“These are simple notions covered in any textbook on climate.”
Why didn’t your textbook on climate teach you such notions like heat flux? 🤣🤣🤣🤣🤣
A minor point that ignorant scoundrels try to make make something of. It is a power flux – in W/m2. It translates into kinetic energy and other forms in the climate system. To be useful scientific terminology must be precise.
I have tried to be nice but the simple minded nonsense combined with rude is just a little too much. Isakov strikes me as a boor and a misguided amateur.
‘All aspects of the essential chemistry, radiative physics and thermodynamics underlying the prediction of human-caused global warming have been verified in numerous laboratory experiments
or observations of the Earth and other planets. Other aspects of the effect of increasing greenhouse gases rely on complex collective behavior of the interacting parts of the climate system; this includes behavior of clouds and water vapor, sea ice and snow, and redistribution of heat by atmospheric
winds and ocean currents. ‘ op. cit. p 77
What, don’t you even know how to make a proper citation?
What is you full paragraph supposed to mean? How does it help you in your argument? Don’t you see that it is equivalent of saying “Bible is true because Bible says it is true?”.
Pathetic as usual
Isakov confuses radiative physics with planetary responses. These simple concepts are so foundational to climate science as to be common knowledge. If he does not comprehend even this he cannot make any meaningful contribution to informed discussion. And he hasn’t.
Radiative forcing is a metric at the foundation of climate science. It is determined from the change in atmospheric concentration of greenhouse gases from that of a reference point – typically 1750 or 1850.
The energy imbalance is the difference between energy in and energy out as a result of forcing and feedbacks – including clouds, lapse rate, water vapor and the Planck feedback.
The heat in the planetary system is largely as kinetic energy of ocean water molecules. Isakov compares the nominal radiative forcing metric with the increase in surface temperature that he implicitly attributes to greenhouse gases. Then says it doesn’t add up and handwaves at the hydrological cycle to explain the supposed discrepancy.
It is naïve error and buried under disparaging rants.
If you read the IPCC AR6 wg1 – the Science Basis – you will see that the science is very far from solid with endless qualifications and doubts but strangely these do not appear in the SPM.
The science behind climate change is really simple. If the earth absorbs more energy from the sun than it radiates into space the planet warms and the climate changes. Anything that happens on the planet doesn’t matter.
The complexity comes in when you try to determine what is happening on the planet and the timing. The sun doesn’t heat the earth evenly. That causes mini energy imbalances across the globe. Weather is the earth trying to resolve all the energy imbalances. How the earth deals with the energy accumulation is what the models are about. That’s where the uncertainty comes in. That the earth is accumulating energy and CO2 is the cause is not that hard to figure out.
> They are specifically not including it.
Read again:
https://www.ipcc.ch/report/ar6/wg1/downloads/report/IPCC_AR6_WGI_Full_Report.pdf
What’s your point? I don’t disagree with that.
> What’s your point?
You must be new here, JJ.
I suppose you are asking me, but it’s not clear since you haven’t addressed anyone or quoted anything.
Here’s an How To Read Comment threads:
Step 1. Spot the quote. In our case, it is:
The “>” character designates a quote in emails and in Markdown.
Step 2. Ask yourself: have you written “They are specifically not including it” somewhere in that sub-thread? No. Then go to 3.
Step 3. Search who did. All should become clear.
Hope this helps.
Just spit it out. I don’t have the time to deal with cryptic posters. There is nothing in my post on Quora that contradicts what you said. If you understood what I said, you would realize that.
> Just spit it out.
*Spits*.
It has been a pleasure to do business with you, JJ.
Stay safe.
JJBraccili, we’re already in an ice age (the Quaternary glaciation, Holocene interglacial, late stage also known as neoglacial, the coldest period of the whole Holocene). What I mean by cooling is the cooling phase of the ~60 year climatic cycle.
Again. Good luck with that!
Good luck with your AGW, a.k.a. “climate change”.
JJBraccili,
Are you nuts? Do you even see which post thread you are posting in? Just read the original post in this particular thread. Can’t you distinguish different posts and follow the same discussions?
Pathetic
What are you talking about? You have become completely unhinged.
I’ve been replying to your posts. You are in serious need of psychiatric help.
JJBracilli,
Do not be lazy? Just look in which thread you are replying. 2 different topics. Currently you are focused on the original post form October 15, 2021 at 5:49 that discussed temperature anomaly flat-lining between 1940-1980. (source was provided)
Post regarding Radiative forcing in the last 70 years is from October 14, 2021 at 10:11 am . And it is a different thread.
While the discussion on Global warming based on IPCC definitions using global mean surface temperature was in the post thread that started on October 12, 2021 at 7:09 am .
It is not my problem that you are confused in the mechanics of this blog.
I got a post addressed to me. I generally don’t answer posts not addressed to me.
Don’t blame me if you don’t know who you are replying to.
TO JJBRACCILLI.
“I got a post addressed to me. I generally don’t answer posts not addressed to me.
Don’t blame me if you don’t know who you are replying to.”
So the fact you are lazy and illogical is somehow my problem.
Plus you are obviously twisting facts here, let’s not call it a blatant lie ;). The post from October 15, 2021 at 5:49 am, was a general post and it was in no way addressed to you. Hence, you just got triggered by my name on your own. Probably not even reading the post that you are replying to.
Grow up. Admit that you screwed up here. It is a minor technical mistake not affecting your “great knowledge in science” credentials. What are you so hysterical about? ;))))
I didn’t screw up anything. When I receive post with “in response to JJBraccili” I assume its addressed to me. Who am I suppose to think it is addressed to? I have many talents. Mindreading isn’t one of them.
Very frustrating. You like snake on the hot plate.
Let me repeat to you a simple fact: The post from October 15, 2021 at 5:49 am, was a general post and it was in no way addressed to you.
You cannot use an excuse that you are just responding to posts addressed to you specifically. You commented on that post on your own and then got confused when discussions about different posts were taking place in parallel.
angech | October 15, 2021 at 6:14 am |
“Thermometers can definitely be set up to measure what everyone else here would call outdoors air temperature.”
How to set up a thermometer to measure the outdoors air temperature?
Please explain.
https://www.cristos-vournas.com
Another wave of Arctic air reaches Western Europe.
http://tropic.ssec.wisc.edu/real-time/mtpw2/webAnims/tpw_nrl_colors/europe/mimictpw_europe_latest.gif
Due to a decrease in the temperature of the stratosphere in the south and a strong polar vortex, the ozone hole over Antarctica is growing.
In 2019, the ozone hole was very small due to the strong sudden warming of the stratosphere that occurred then. This is evidence that the ozone hole depends on the strength of the polar vortex.
Because stratospheric polar vortex is weaker in the north, the ozone hole usually does not appear.
https://i.ibb.co/qnhQkTj/ozone-hole-plot.png
https://www.cpc.ncep.noaa.gov/products/stratosphere/strat-trop/gif_files/time_pres_TEMP_ANOM_OND_SH_2021.png
“The altitude of the troposphere most similar to Earth is near the tropopause—the boundary between troposphere and mesosphere. It is located slightly above 50 km. According to measurements by the Magellan and Venus Express probes, the altitude from 52.5 to 54 km has a temperature between 293 K (20 °C) and 310 K (37 °C), and the altitude at 49.5 km above the surface is where the pressure becomes the same as Earth at sea level. As manned ships sent to Venus would be able to compensate for differences in temperature to a certain extent, anywhere from about 50 to 54 km or so above the surface would be the easiest altitude in which to base an exploration or colony, where the temperature would be in the crucial “liquid water” range of 273 K (0 °C) to 323 K (50 °C) and the air pressure the same as habitable regions of Earth. As CO2 is heavier than air, the colony’s air (nitrogen and oxygen) could keep the structure floating at that altitude like a dirigible.”
https://en.wikipedia.org/wiki/Atmosphere_of_Venus
“A minimum atmospheric temperature, or tropopause, occurs at a pressure of around 0.1 bar in the atmospheres of Earth1, Titan2, Jupiter3, Saturn4, Uranus and Neptune4, despite great differences in atmospheric composition, gravity, internal heat and sunlight. In all of these bodies, the tropopause separates a stratosphere with a temperature profile that is controlled by the absorption of short-wave solar radiation, from a region below characterized by convection, weather and clouds5,6. However, it is not obvious why the tropopause occurs at the specific pressure near 0.1 bar.”
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.465.8585&rep=rep1&type=pdf
SOI has increased and the Niño 3.4 index will reach -0.8 C by the end of October.
https://www.tropicaltidbits.com/analysis/ocean/nino34.png
The tropopause can be defined as the region of the atmosphere where the vertical temperature gradient drops dramatically and heating from the surface disappears. Therefore, in winter, the height of the tropopause decreases in high and middle latitudes.
Water vapor, because it is lighter than air and the ocean temperature drops more slowly than the continent, is able to raise the tropopause height in winter.
Thus, even a small amount of water vapor in the air slows heat loss in the troposphere in winter.
https://www.cpc.ncep.noaa.gov/products/stratosphere/strat_int/gif_files/gfs_hgt_trop_NA_f000.png
https://www.cpc.ncep.noaa.gov/products/stratosphere/strat_int/
How he gets from there to here is a complete mystery.
‘Stratospheric Intrusions are when stratospheric air dynamically descends into the troposphere and may reach the surface, bringing with it high concentrations of ozone which may be harmful to some people. Stratospheric Intrusions are identified by very low tropopause heights, low heights of the 2 potential vorticity unit (PVU) surface, very low relative and specific humidity concentrations, and high concentrations of ozone. Stratospheric Intrusions commonly follow strong cold fronts and can extend across multiple states. In satellite imagery, Stratospheric Intrusions are identified by very low moisture levels in the water vapor channels (6.2, 6.5, and 6.9 micron). Along with the dry air, Stratospheric Intrusions bring high amounts of ozone into the tropospheric column and possibly near the surface. This may be harmful to some people with breathing impairments. Stratospheric Intrusions are more common in the winter/spring months and are more frequent during La Nina periods. Frequent or sustained occurrences of Stratospheric Intrusions may decrease the air quality enough to exceed EPA guidelines.’
Because of the high PV, the waves that fall from the stratosphere into the troposphere do not mix with the tropospheric air, but instead cause waves in the troposphere. This allows moist air from the south to reach far north.
“Within the troposphere, PV values are typically low. However, the potential vorticity increases rapidly from the troposphere to the stratosphere due to a significant change in static stability. Typical changes in potential vorticity in the tropopause range from 1 (tropospheric air) to 4 (stratospheric air) PV units (10-6 m-2 s-1 K kg-1). Currently, an anomaly of 2 PV units, separating tropospheric from stratospheric air, is referred to as the dynamic tropopause in most literature. The traditional way to describe the tropopause is to use potential temperature or static stability. This is only a thermodynamic way to characterize the tropopause. The advantage of using PV is that the tropopause can be understood in both thermodynamic and dynamic terms. A rapid bending or lowering of the dynamical tropopause can also be referred to as an upper PV anomaly. When this occurs, stratospheric air penetrates into the troposphere, resulting in high PV values relative to the surroundings, creating a positive PV anomaly. ”
“There is a clear relationship between PV and water vapor imaging. The low tropopause can be identified in WV images as a dark zone. As a first approximation, the tropopause can be treated as a high relative humidity layer, while the stratosphere is very dry with low relative humidity values. The measured radiant temperature will increase if the tropopause decreases. This is because the radiation measured by the satellite comes, to a first approximation, from the upper part of the moist troposphere. High radiation temperatures will result in dark areas in the WV images. ”
https://rammb.cira.colostate.edu/wmovl/vrl/tutorials/satmanu-eumetsat/satmanu/basic/parameters/pv.htm
https://www.cpc.ncep.noaa.gov/products/stratosphere/strat_int/gif_files/gfs_pvort_320K_NA_f000.png
You define turbulent planetary waves with such certainly and precision as never before in the annals of planetary science. But – other than a photovoltaic – what’s a PV?
Stratospheric intrusions occur when the polar vortex is blocked in some region above the Arctic Circle by ozone accumulation.
https://i.ibb.co/6tjzGMS/gfs-t30-nh-f00.png
https://i.ibb.co/pxSSrdT/gfs-t100-nh-f00.png
https://i.ibb.co/0mXNKCG/gfs-o3mr-150-nh-f00.png
Potential vorticity is a cute idea – but we don’t have the math for global scale turbulence. I put little faith in eyeballing vortices.
PV maps allow us to show the movement of the polar vortex in the tropopause.
https://atmos.uw.edu/cgi-bin/wxloop.cgi?/home/user_www/hakim/tropo/theta/+all
It is one of the ways of visualising atmospheric dynamics at the tropopause.
I have a separate question. Unrelated to Radiation forcing and energy balance, so hawks of “consensus science” can relax.
The so called Little Ice Age is a period from 1300 to about 1850. The period preceding current Global Warming.
Now Sankt-Petersburg was established in 1705, just in the middle of it. Most of palaces were built in 1730s. Now, if you go and visit them you will notice that none of them are built for cold climate. Story goes that it is just because Italian architects were invited. But buildings are massive, in the middle of nowhere (there were marshes), it would take several years in those technologies. Even Italian architects would notice the issue. Or at least after the first disastrous project, the second palace would be built with actual heaters in the rooms. And this is in the middle of the Little Ice Age. Did anyone ever compared perceived temperature records to features of the buildings that were built in those eras.
I don’t know if there is a contradiction.
The architecture was for ostentatious display. It was first and foremost to show off the wealth of the Tsars.
Bad design for dealing with cold weather could also be handled by wealth.
Wikipedia says:
As the formal home of the Russian Tsars, the palace was the setting for profuse, frequent and lavish entertaining. The dining table could seat 1000 guests, while the state rooms could contain up to 10,000 people—all standing, as no chairs were provided.[54] These rooms, halls and galleries were heated to such a temperature that while it was sub-zero outside, exotic plants bloomed within, while the brilliant lighting gave the ambiance of a summer’s day
Illogical on their part, but plausible just a show off, as you say. Probably noting more there
If freezing of the Thames was occurring, the polar vortex must have been strongly blocked. This looks like a prolonged SSW, so that the circulation switched to the east. These anomalies occur mainly from autumn to winter. Summer blocking can bring strong heat when a high is blocked over an area. In my opinion, the Little Ice Age is more of a weather anomaly than a strong global temperature drop. This is how the weather fooled Napoleon and Hitler.
Isakov
Yes, Torre Abbey on the south west coast of England near me, was built in 1196 and had many features of a warm weather climate, including cloisters that were open, for monks to study and pray in, unglazed windows, no fireplaces.
in the 1370’s the monks roofed over the cloisters, created fireplaces, glazed in windows as according to the records the temperatures had become much colder and they were unable to study in the former open cloisters.
we can trace that to a distinct change in the climate and a change in the wind direction from warm wet westerly winds to cold easterlies in winter with increased gales.
As regards the 1730’s we know that to be a very warm decade from records in England and Sweden and North America
tonyb
Isakov
Thank you for your comment about St Petersburg since it prompted me to look at the images of those palaces. Magnificent!
Many moons ago, pre Internet, I read biographies of Peter The Great and Catherine the Great, but I don’t remember the books having any pictures of those wonderful buildings.
I’ve been in -50 F windchill and slept in a tent at 10 F. Whether the LIA was a few degrees C colder than now, anything below freezing is miserable and can be dangerous. Building for lows of +10 F or -10 F is kind of a rounding error. It would have been uncomfortably cold regardless. One source shows St Petersburg all time low at -33 F with records going back to mid 1700s.
Construction of those buildings would have been before electricity so the only heaters would have been fires. When it got really cold the most important question was how much bigger do we make the fire. I don’t think the facade of the structures could have made much of a difference in heat retention, and insulation as we know it was nonexistent.
At the current rate of trying to transition to new energy supplies prematurely, millions might have the wonderful opportunity to freeze inside their homes just like Peter and Catherine and their contemporaries did.
Hi CKID,
You are welcome. I started looking at the topic after uncovering some information about how hard was it to heat up those palaces.
For example in 1787 Count Sheremeti’ev was writing in a letter: “Just think that I am in the palace twice every day. I myself wonder how it gets to me and the evening was in the mezzanine: this is the name of the ceremonial chambers like a museum, it is only very cold in them, they are almost not heated, all the ends, but the stoves are only for the sake of sight and some do not even close”.
Another description from early 19 century: “In the back courtyard, huge stacks of firewood grew (firewood was stored for long-term storage in the basement of the Winter Palace), they were carried through the halls by stokers, inevitably carrying dirt and soot with them. For a long time this mud and vanity was taken for granted”.
In 1835 they even tried to introduced mechanized system to avoid the dirt. Here is the exert from the report: “for prevention of dirt carried along the stairs and corridors by working people while carrying firewood by them, as well as to facilitate them in this work, it is considered necessary: to arrange a machine for lifting firewood from the lower to the upper floor of the Winter Palace, near the stairs that has at the Frailinsky corridor, which point is indicated in pencil on the plan attached to this”
Yes, desire for opulence no matter the costs can be used as an excuse. But with all that dirt and inconvenience there can also be doubts. It sounds more like the buildings were built when climate was much wormer and royals just didn’t want to leave those palaces no matter what the new climate brings.
But of course, I have no proof. Just speculation
JJBraccili
“A liquid is a liquid because there are forces of attraction between molecules that hold the molecules close to each other.”
A volatile substance, water including, is liquid because there is atmospheric pressure on its surface…
https://www.cristos-vournas.com
Really? You can have a liquid at very low and high very pressures if the temperature is suitable. You can’t have a liquid it the temperature is above the critical temperature at any pressure.
At atmospheric pressure, you can’t have liquid water at a temperature above 212 F.
What’s your point?
You can’t have any liquid water on Earth’s surface without-atmosphere…
https://www.cristos-vournas.com
What’s your point? I didn’t even mention pressure in what I was talking about. I was talking about intermolecular forces. Your comment was a non-sequitur.
J Braccili
“A liquid is a liquid because there are forces of attraction between molecules that hold the molecules close to each other.”
or
https://www.cristos-vournas.com
A volatile substance, water including, is liquid because there is atmospheric pressure on its surface…
JJBraccili |
Really? You can have a liquid at very low and high very pressures if the temperature is suitable. You can’t have a liquid it the temperature is above the critical temperature at any pressure. At atmospheric pressure, you can’t have liquid water at a temperature above 212 F.
JJBraccili | October 16, 2021 at 3:25 pm |
What’s your point? I didn’t even mention pressure in what I was talking about. I was talking about intermolecular forces.
He meant the definition of a liquid was a little bit more than just intermolecular forces which failed to exclude solids and gases.
You think pressure is significant? Why don’t we have liquid H2, N2, O2 at atmospheric pressure? At 0 C put all the pressure you want on H2, N2, & O2 and they will never liquify.
CO2 warms the atmosphere. But the monster in the room is SW radiation. And what follows the monster as 2nd monster is LW radiation.
Or are the monsters clouds and what they are made of, water?
So were are counting radiation, clouds, water and we found one thing to explain it all. Our CO2 emissions. This would be like counting the petty cash and auditing that when Sales are a million times what’s in petty cash.
Somebody finally counted the right things with this study. They kept good records. They’ve demonstrated their ability to count, though imperfectly.
Most climate studies are, we found this little gremlin and it turns out that sucker is in charge of all our finances. The gremlin says jump or dance over there, and that’s where all our finances go. So we just need to tame the gremlin.
Did I tell you I am an auditor and have been doing this for a long time?
In how many universes are such things true?
The monster in the room is the height of the oceans. That is what controls the amount of radiant retained by the earth daily.
I will say it differently.
The monster in the room is the land surface area.
The more the land surface area of the earth, the higher the radiant retained by the earth.
I agree with your first answer. The oceans will moderate change for a long time. Long enough I think. 70% of the surface of earth X 4 kilometers deep of water.
It would not matter if the whole world was made of water.
There is no storage of heat in water or matter.
Energy radiates from surfaces only, not from depth.
All I am saying is that as the oceans rise more radiant is reflected to the black sky The surface area of the earth covered by water increases, while the surface area of the earth covered by land decreases. Less heat is retained by the earth. Since the oceans are staying at a constant height the heat loss to the black sky is equal to that which is retained to melt the ice that broke off.
It’s just the opposite. Land surfaces reflect more energy (higher albedo) than water surfaces. More ocean surface less land surface more solar radiation absorbed.
http://ponce.sdsu.edu/surface_albedo_and_water_resources.html
Melting ice may or may not increase the volume of water in the oceans. Floating ice doesn’t change the volume. Ice over land does. The volume of water increases with temperature. Warming oceans increases the volume of water in the oceans and height.
“Less heat is retained by the earth.”
Water is a transfer medium. It absorbs and stores efficiently. Ground soil does not. Dry place experiencs wilder extremes compared do wet places. Seasonal joule storage if it happens will be with water and not earth. Earth in Minnesota is so resistant to transfer, frost will not go deeper than 6 feet. Water being a transfer medium does transport heat and cold across latitudes.
The Vostok ice core shows it took about 8,000 years to drop the oceans to their lowest point after the ice blocks were gone. That is when nature made the new ice blocks.
When the CO-2 was at its highest the ice blocks were completed. About 8,000 years the oceans dropped to the level we are at now. That is when the ice blocks were breaking off and melting equal to that amount freezing and being dropped on the frozen areas at the poles.
We will remain here for about another 110 thousand years.
THAT IS THIS ICE AGE. IT IS JUST THAT EASY TO UNDERSTAND.
Ragnaar | October 17, 2021 at 10:53 am |
“Less heat is retained by the earth.”
Water is a transfer medium. It absorbs and stores efficiently. Ground soil does not. ”
Water does not store heat.
Heat does transfer through it better than most earths.
Basically the earth gets hotter than the water during the day.
I hope you would not say it is storing more energy than the ocean because the temperature is higher.
Not only that it is at a much hotter temperature than the ocean can reach despite having the same amount of back radiation.
At first glance one would have to say, gee there is a lot more heat there for the temperature to be so hot.
I hope you would not say it is storing more energy than the ocean because the temperature is higher.
At the end of the day what have you got?
The same amount of energy that went in had to come out.
You won’t accept that the earth surface has more energy during the day, I think.
It certainly did not get any extra or manufacture any extra but it did seem a lot hotter.
Yet you hasppily claim the reverse for the ocean.
The heat just dived in and sank to the bottom.
No
The land is a very densely packed surface that absorbs all the energy in a single layer.
The ocean does the same thing but the energy is topped at different levels of the ocean by exactly the same number of intercepts on the ground. A diffuse impenetrable layer.
The molecules of the land are closer together at absorption level , take on energy and at that stage as they emit it you measure the temp from the radiation and say it is hot.
How can that molecule be hot when it has just lost its radiation energy?
You have it entirely wrong.
You are aware that ocean temperatures vary. They’re not constant. They would be if water didn’t store heat or kinetic energy. Energy Out = Energy Out at steady state.
Stick a thermometer in a pot of water at 25 C. Turn on the heat and watch the thermometer. It will rise slowly until it gets to 100 C and the water boils. If you turn off the heat. The pot will slowly return to 25 C. If you measure the heat lost, it will be identical to heat required to heat the pot to 100 C.
That ‘s pretty much the definition of storing energy.
I am saying the earth is radiating more heat to the black daily than it is retaining from the sun because the area of the earth covered by the oceans is high.
To keep a constant surface temperature nature is breaking off ice from the ice blocks and melting it to replace the heat lost.
The ice blocks are not floating. They were formed when the oceans were at their lowest. They are resting on solid earth.
You have the science wrong. What matters is the difference between the energy absorbed from the sun and the energy earth radiates into space. Right know we are absorbing more energy from the sun than we radiated from space. That’s causing the planetary temperature to rise and the ice to melt.
“To keep a constant surface temperature nature is breaking off ice from the ice blocks and melting it to replace the heat lost.”
That is profoundly wrong. If water is replacing heat lost, it does that by freezing. In freezing you take heat out of water and that heat would replace heat lost in the surroundings. You have to add heat to ice to make it melt.
Deposition or desublimation, in which a substance passes directly from a gas to a solid phase.
That is the term explaining water vapor flashing to snow or ice in the upper atmosphere.
This is how nature adds heat to the atmosphere
Let me try again please. In my office in MN I have boiler heat. What I will call the tank is heated by natural gas flames. The tank stores the heat. When the thermostat calls for more warmth, a water pump runs and moves water from the tank to the radiators. The water moves in a big circle around the interior of the exterior walls. The water absorbs heat, stores it, then the pump transfers it, then it is released. The system uses water and actually leaks a bit as it’s old and buried under the doors sills. I turn some valve and add water to it. While boiler heat is less efficient, I have zero plans to change to forced air, leaks and all. The damn boiler is well over 30 years old and some manifold shaped thing will eventually rust out I’ve been told. The point is, water stores and transfers heat. We apply that theory and have for many years. The beauty of Earth’s climate is: Water stores and transfers heat. God himself could not have come up with a better plan.
For his next acts, angech will explain Newton’s misunderstandings and why water isn’t wet.
Weather is just NATURE taking the warm humid air from over the oceans, moving it to the poles, freezing the moisture in it, and in this case dropping it on the frozen areas. The dry air works it way back towards the equator.
If the ice blocks were not breaking off nature would over cool the earth.
GOD did come up with a better plan. I call it ICE MAKING AND ICE MELTING. It works because of the most ingenious design called water. That is because water expands as it cools from 39’F to 32’F!!!!!
As an auditor, Mr. Ragnaar, you probably know
a lot about counting things that exist.
But you may not understand
modern climate “science”.
Modern climate “science”
is about the future.
A coming climate crisis.
That is always coming,
but never arrives.
The imagined crisis
has not happened yet.
There is nothing to count.
So you can’t count anything
— you just predict.
Then you develop
complex computer games
and program them to predict
the a coming climate crisis.
You do this every year
for over six decades.
Eventually almost everyone
believes in that coming crisis.
There is really nothing to count.
… Except maybe the number of
failed climate predictions?
That would be a very long list.
This is why we look at what has happened. Not what will happen. This is a generalization. It is also important to understand the system. How money flows through it. Accounting is a spreadsheet with connected modules. QuickBooks and UltraTax software are these spreadsheets and work. CMIP6s are junk. They do not understand the system sufficiently. They would not withstand an IRS or SEC audit.
The monster in the room is the height of the oceans. That is what controls the amount of radiant retained by the earth daily.
It would not matter if the whole world was made of water.
There is no storage of heat in water or matter.
The radiant energy is always stopped at a boundary.
Defined as the surface in an airless solid body.
The mass of the rest of the body does not count.
Take a water world in your example and shine a flashlight on it.
In the world of oceans retaining energy the whole world will eventually heat up to the temperature of the ongoing source , the flashlight.
Apart from the surface, which has no say in a storage model. It would have to have one small emitting portion only at sub flashlight energy level.
Now if you use the argument that this is wrong because the surface must emit what it receives at a lower level spread out, you immediately destroy the credibility of the retained energy idea.
I am not happy with this, but the alternative theory of energy being accumulated and stored leads to that even greater, unphysical example
The monster in the room is Mr. T.
We’re still here. Which reminds me of a story. I worked for a guy who got married for the 3rd time in his 70s to a women with a dog. He confided in me his goal in life was to outlive the dog.
The monster in the room is Mr. T.
With magical powers. Able to absorb heat energy and transfer it to its caves in the deep ocean. Stopping it from going back whence it came at whim.
So if we go with 0.75 W/m2 in the second plot at 90% into the oceans, we have effectively 0.075 W/m2. It’s not kind of going into the oceans. It really is going into the oceans.
So 90% is 0.675 W/m2 into the oceans. Into a column of water 1 meter by 1 meter by 2.8 kilometers (taking into account only 70% of Earth is covered in water).
So we are putting one LED nightlight (0.675 W/m2) worth of heat per square meter of ocean surface more or less. And I think this is ballpark the same as heat coming from the center of the Earth.
Where does the 10% go? Into the atmosphere. So, we take 1 LED nightlight per 10 square meters of the Earth surface. And we don’t let that heat sneak into the ocean or leave via the TOA.
There are problems with standard physics.
What happens when a photon is reflected is one of them.
“”hen light bounces off an object it does impart momentum to it. In the simplest case, light bouncing off a very massive stationary object, the light imparts no energy to the object. The momentum imparted is twice that of the incoming light, since it just changes directions and thus changes the sign of its momentum.”‘
Here we have a conundrum.
We accept that energy has to be unstoppable, yet we quite happily allow waves of opposite energy to cancel out and reflections to double energy in the opposite direction and never mention the energy that should be ongoing in all cases.
Something does not work properly.
Part of this problem is that we tend to treat matter and energy as only existing in two phases that we poorly describe by particle and partly by wave theory and treat them as existing in an empty vacuum through which some entities can transit without leaving a trace.
The answer is more complex than that depending on the extra dimensions that exist to what we can see. In the time space matrix we can see that our ideas of distance and time can be expanded or shrunk due to two things. The existence of mass in space and the existence of motion or movement between the masses.
There are other properties that are difficult to define and harder to explain but a GUT needs to start from somewhere and has to include answers to the problem with energy outlined above.
The problem for radiative physics, Radiative energy flux variations from 2000 – 2020, that we are discussing here, with its bearings on Earth’s radiation balance is that the maths incorporates unreal physics due to an inability to accept what the actual physics is trying to tell us.
Thus firstly, if we accept physics we have to accept that there can be no storage of radiation.
Energy in always equals energy out even though on the face of it it should not.
We look at something hot and see that it takes time to cool down so we say the object is storing heat.
We look at the oceans and see temperature variations and we say the warmer layers are storing heat.
How can there not be extra energy?
We look at something hot and see that it takes time to cool down so we say the object is storing heat.
We look at the oceans and see temperature variations and we say the warmer layers are storing heat.
How can there not be extra energy?
-In all these scenarios we are blinded by the seeming retention of heat in the hot objects.
What we do not take into account is the massive system it is all in.
If any of these things were on their own, in space, with no heat input or surroundings how different the story.
A glass of warm water would freeze instantly as the energy, now not supplanted by back energy goes straight out.
Ragnar sort of explains it.
“So 90% is 0.675 W/m2 into the oceans. Into a column of water 1 meter by 1 meter by 2.8 kilometers (taking into account only 70% of Earth is covered in water).”
All that heat in the ocean [not so much really] is only kept there by continual replacement of that energy from the sun. The old chestnut of so many Hiroshima size bombs every second is more than enough to do this every second during the day plus put the temperature of the atmosphere up.
What happens when the sun goes down. Temperatures drop.
“Photons don’t have mass, but they do have momentum, which is energy associated with motion. If a photon strikes something, it can give some of its momentum to the object it hits. In the case of a solar sail, when light hits the sail’s reflective surface, it bounces off, transferring some of the energy associated with its initial motion to the sail. This force is called radiation pressure, and it pushes the sail slightly in the direction the photon was traveling before it bounced off.”
While this seems like cheating, I assume it’s true. Something has force but no mass. This is Star Trek stuff. Does infrared have mass? I can make photons. I turn on a light. I am transferrring something from the source to elsewhere using energy. So we might say this is a case of perfect efficiency. I can make a plant grow with my light. I am putting energy into the plant which I can later eat. Physics is fine today. It has not collapsed.
The term describing the phenomena is relativistic mass.
https://www.britannica.com/science/relativistic-mass
Thank you JJBraccili
The term describing the phenomena is relativistic mass.
Ragnaar Physics is fine today. It has not collapsed.
yet
If a photon strikes something, it can give some of its momentum to the object it hits. In the case of a solar sail, when light hits the sail’s reflective surface, it bounces off,
how much momentum does it give?
Not some. All
bounces off?
billiard balls are said to bounce off each other.
But the momentum forwards is preserved.
The billiard ball stops if the other billiard ball gains maximum momentum
Galileo explained this by combining a small and a large mass when people thought heavier objects fell faster.
Does the lighter object added act as a parachute?
Doe the heavier overall mass go faster again?
No
Billiard balls do not suddenly gain the energy to go back the other way with the same force but light does.
This is not explainable and leads to perfect motion machines concepts. like radiation imbalance, creating energy from nothing
JJBraccili explains the first half of the problem
Some simple relativistic math might help. Photons travel at the speed of light and thus have zero mass and infinite momentum.
Robert I. Ellison commented:Some simple relativistic math might help. Photons travel at the speed of light and thus have zero mass and infinite momentum.
LOL. Photons have finite momentum: Energy/c
angech commented:
The term describing the phenomena is relativistic mass.
Wrong. There is no “relativistic mass.”
There is only mass.
Mass does not increase with speed of a particle.
Mass is a constant.
It’s the laws of kinematics that change.
Learn.
JJBraccili commented:
The term describing the phenomena is relativistic mass.
There is no such thing as “relativistic mass.”
Mass is constant. It’s the laws of kinematics that change as velocity of a particle increases.
There is relativistic mass. I linked an article in which a physicist discusses it.
I hear that some physicists prefer to use momentum.
JJBraccili wrote:
There is relativistic mass.
No there isn’t. It’s only an old-fashioned sleight-of-hand trick taught to freshman instead of teaching them the true science, that the laws of kinematics change as velocity increases.
The modern view is that mass is mass = rest mass = constant. It does not vary with velocity. What changes are the laws of kinematics — relativistic kinematics.
JJBraccili wrote:
The term describing the phenomena is relativistic mass.
https://www.britannica.com/science/relativistic-mass
That’s just a definition. It does not mean that a particle’s mass increases with velocity. It just appears that way in the relativistic equations. It’s the Newtonian equations that change, not the mass.
Robert I. Ellison wrote:
Some simple relativistic math might help. Photons travel at the speed of light and thus have zero mass and infinite momentum.
If a photon had infinite momentum, just one of them striking the Earth would send it careening towards the end of the Universe at the speed of light.
OMG.
It is right there in the relativistic math.
Robert I. Ellison wrote:
It is right there in the relativistic math.
You’re an i.d.i.o.t.
For m=0, p=E/c. For a photon E=hf, f=frequency.
Nothing has infinite momentum.
Think!!!!!!!!!!!!!!!!!
Mass approaches infinity as the velocity approaches the speed of light.
https://www.citycollegiate.com/relativity5.gif
David is wrong yet again and becomes a n.a.s.t.y. little t.r.o.l.l. at the drop of a hat.
http://hyperphysics.phy-astr.gsu.edu/hbase/Relativ/imgrel/prel.gif
Robert Ellison wrote:
Mass approaches infinity as the velocity approaches the speed of light.
Not for a massless particle!
Robert I. Ellison commented:
http://hyperphysics.phy-astr.gsu.edu/hbase/Relativ/imgrel/prel.gif
That equation is derived assuming mass does not equal zero and velocity does not equal c!!!!!!!!!!!!!!!!!!!!!!1
RIE, you can’t think at all.
If a solar photon actually had infinite momentum, it would collide with the Earth and send the Earth outward with infinite velocity.
Nothing has infinite momentum.
What the F is wrong with you??
I’m not a know.it.all, Robert, I just take great delight in smacking down know.it.alls like you when they are gloriously and laughably wrong.
‘There is no such thing as “relativistic mass.”
Mass is constant. It’s the laws of kinematics that change as velocity of a particle increases.’ David Appell
Mass changes with velocity.
Photons always travel at the speed of light – explicit in the relativistic math is that photon mass is zero and momentum infinite. There are some deep mysteries in photon wave/particle duality and always pompous fools who pretend they have all the answers.
Robert I. Ellison wrote:
Mass changes with velocity.
Nope. Old-fashioned thinking for plebes.
Photons always travel at the speed of light – explicit in the relativistic math is that photon mass is zero and momentum infinite.
Really? Then what happens when a solar photon with infinite momentum collides with the Earth?
Where does the Earth, with finite momentum, go?
Tell us, Robert.
David is really quite ridicules. How does he explain away mass dilation for plebeians?
https://www2.lbl.gov/MicroWorlds/teachers/massenergy.pdf
The relativistic math in the video I posted just above in this thread contains some counterintuitive results. I’ll let you know when I figure it out. Right now I am going with the math and not David’s incredulity.
Robert blindly looks at the math without looking at the assumptions behind the derivations.
Robert answer this question you’ve avoiding: when a solar photon of (your) infinite momentum strikes the Earth of finite momentum, where does the Earth go?
Robert I. Ellison commented:David is really quite ridicules. How does he explain away mass dilation for plebeians?
Now you’re even more confused — there is no “mass dilation,” LOL.
There is time dilation.
Mass is a constant. What changes is the equations of kinematics. That’s what Einstein showed.
I don’t think you’re know you’re smart enough to understand that, but that’s not my problem, it’s your’s.
What changes in both time and mass dilation is the Lorenz factor. But David want’s to define one out of existence and keep the other. It makes absolutely no difference to predictions.
What happens when a wave with theoretically no mass and infinite momentum strikes the solid Earth? The usual. And David is as usual being too slippery and too bombastic.
Robert I. Ellison commented:
What happens when a wave with theoretically no mass and infinite momentum strikes the solid Earth? The usual.
The usual???????
What is the usual????
Solve the equations when one incoming particle has infinite momentum.
I dare you.
OMG
The 3.4 Niño Index has dropped below -0.8 and will be below -1 C by early November.
http://www.bom.gov.au/archive/oceanography/ocean_anals/IDYOC007/IDYOC007.202110.gif
In November and December 2020, the area of the ozone hole was at a record high. Will this year be similar?
https://www.cpc.ncep.noaa.gov/products/stratosphere/polar/gif_files/ozone_hole_plot.png
https://www.cpc.ncep.noaa.gov/products/stratosphere/strat-trop/gif_files/time_pres_TEMP_ANOM_ALL_SH_2021.png
With an intense Aleutian Low and the Intertropical Convergence Zone moving south – we may see enhanced upwelling in the north-east Pacific, more closed cell marine stratocumulus, a higher albedo, a good year for chinook salmon, baby seals and anchovies and lower global surface temperature.
https://earth.nullschool.net/#current/wind/surface/level/overlay=mean_sea_level_pressure/orthographic=-132.10,27.08,241/loc=-170.384,57.789
https://www.ospo.noaa.gov/Products/ocean/sst/anomaly/
Of course – being turbulent fluid flow patterns these things shift on a dime.
The polar vortex pattern in the lower stratosphere changes slowly and can continue throughout the winter.
https://earth.nullschool.net/#current/wind/isobaric/70hPa/orthographic=-143.96,50.11,372
The forecast is extremely interesting.
https://earth.nullschool.net/#2021/10/22/0000Z/wind/isobaric/70hPa/orthographic=-150.44,76.33,372
Even more interesting is the pattern of the north polar vortex at 10 hPa.
https://earth.nullschool.net/#current/wind/isobaric/10hPa/orthographic=-116.57,69.23,372
It’s a vortex created by planetary spin but changes with polar surface pressure.
https://www.ncdc.noaa.gov/teleconnections/ao/
That’s a near real time visualisation not a forecast. And it depends you find major modes of climate variability interesting or ephemera high in the atmosphere.
These “ephemeris” are already affecting North American weather and will continue to do so.
https://i.ibb.co/GW8cRyf/gfs-T2ma-us-11.png
https://earth.nullschool.net/#2021/10/22/0000Z/wind/isobaric/10hPa/orthographic=-106.99,60.17,591
I suggest that it is the Arctic Oscillation that more directly drives storm tracks across North America.
https://www.ncdc.noaa.gov/teleconnections/ao/
If anyone believes that the stratospheric polar vortex does not rule winter weather in the mid-latitudes they are sorely mistaken.
http://ds.data.jma.go.jp/tcc/tcc/products/clisys/STRAT/gif/zu_nh.gif
The animation below shows the change in weather pattern in the Gulf of Alaska since late September.
https://coralreefwatch.noaa.gov/data/5km/v3.1/current/animation/gif/ssta_animation_30day_large.gif
The Arctic Oscillation – polar surface pressure – seem more directly relevant to surface winds and storms.
https://en.wikipedia.org/wiki/Arctic_oscillation
Of course – being turbulent fluid flow patterns these things shift on a dime.
The tracks of hurricanes as well.
I have presented a New equation precisely calculating the planet without-atmosphere mean surface temperatures.
The equation is New. It is based on few principles:
1). The Stefan-Boltzmann emission law.
2). The Planet Surface Rotational Warming Phenomenon.
3). The correct estimation of the “energy in” – the not reflected portion of the incident on a planet solar SW EM energy.
It should have been discovered that there is a strong specular reflection from the smooth surface sphere, which is not taken in consideration by the planetary Albedo the satellite measurements.
4). A planet (any planet) cannot be considered as a blackbody surface, because planet is solar irradiated from one side only, and, thus, planet is not capable achieving a uniform surface temperature, no matter how fast it rotates.
5). An irradiated body is considered as a body without an inner source of energy, or as a not previously warmed to some temperature, thus the only source of energy it receives is the EM radiative energy.
When EM radiative energy hits a surface it is not absorbed by the surface (not being transformed into heat). The EM energy interacts with the surface’s atoms and molecules, thus the EM energy is partially reflected (diffusely and specularly) and partially IR emitted (by transformation from SW into LW EM energy).
Only a small fraction of the incident solar EM energy is being transformed into heat. That small amount of heat then, by conduction is getting transported in and is accumulated in the surface’s inner layers.
When something is New it has to fight for its place among the old.
Φ(1 – a) is a coupled physics term multiplied with solar flux S.
Φ is not multiplied with Albedo. Φ is multiplied, along with (1 – a) term with the solar flux S.
Thus there are not any tricks here… But there are some New concepts and they have to fight their way through the old long established insights.
https://www.cristos-vournas.com
Curiously, the paper itself starts with a statement “climate variations originate from variations of the radiative balance at the top of atmosphere”. This is almost certainly not true as stated.
Indeed, the phenonmenon investigated by the paper is a change in the radiative balance caused by a change within the climate system itself, namely a change in clouds within the system. That the change in radiative balance itself has consequences within the climate system is clear, but there is nothing to establish that the change relating to clouds was in any way caused by a variation in radiative balance.
“Facebook-owned Instagram censored evolutionary biologist Colin Wright earlier this week after he posted a study from a major medical journal showing male-to-female transgender people (aka biological men) have a natural advantage over biological women in multiple sports. The Masters of the Universe reportedly consider the post to be “hate speech.””
It used to be that uttering certain words was hate speech. The sign of a witch. Now some scientific facts are hate speech according to Instagram. How long before we are burning scientists as they did witches?
Link: Instagram Censors Biologist for Posting Evidence Showing Biological Men Are Stronger Than Women
I read that as well. Introduction into evidence exhibit number 1 that the world has become a free range insane asylum.
Common sense might be the most rare commodity in our society.
Ah, the good ol’ days:
https://www.rarenewspapers.com/view/580705
> Ah, the good ol’ days:
Yes. When men were men.
And manly.
And women and minorities and h0mosexuals knew their places.
And children were meant to be seen and not heard.
Ah, those were the days my friend.
Yes, good old days when facts were facts. For those living in utopian bubbles that must be difficult to understand.
Sure, Jan:
https://blogs.loc.gov/headlinesandheroes/files/2021/05/Tulsa_s-Terrible-Tale-is-Told-The-Chicago-Whip-June-11-1921-1024×550.jpg
J:
We have biological men displacing women as winners in sports. Some call that, The Patriarchy so Crafty. Women are surrendering to biological men in something they helped build, women’s sports.
“I support anyone’s right to be who they want to be. My question is: to what extent do I have to participate in your self-image?”
They realize they can’t take the author of the above quote down. But they can put H.S. young women in what they see as their places.
Rsgnaar –
Life involves tradeoffs. Outside of libertarian fantasy Shangri-las, anyway.
J:
How are the wars on drugs and terror working out?
We will drag the whole world kicking and screaming to look at itself in the mirror. What were the trade offs in Afghanastan?
We haven’t had a discussion in a long time.
The trade off was to accept Hunter Biden. Who is painting for dollars in plain sight. The trade off was to put V.P. Harris on the ticket because of you know, diversity. Got to have that. Life involves trade offs.
“While the details of President Biden’s executive order remain fuzzy, asking women — no, requiring them — to give up their hard-won rights to compete and be recognized in elite sport, with equal opportunities, scholarships, prize money, publicity, honor and respect, does the cause of transgender inclusion no favors,” Hogshead-Makar said. “It engenders justifiable resentment, setting back the cause of equality throughout society. And either extreme position – full inclusion or full exclusion in sport – will make life much harder for transgender people. We must make sport a welcoming place for all.” https://www.usatoday.com/story/sports/2021/02/01/group-protect-womens-sports-accommodate-transgender-athletes/4345854001/
Back in the 19th century women weren’t allowed to have competitive sports because it was a well known fact that their menstrual cycle sapped too much of their energy. Time to prove the old hypothesis correct by having women with menstrual cycles lose consistently and take us back to the good ol’ days. This is just stupid. I assume they will fix it eventually but what to do with the records made that won’t be broken for 100 years?
Hello, I’m not a climate scientist and I’ve been saying the for years. The oceans are warming. Visible radiation, not IR, warms the oceans. For the oceans to warm, you have to have more visible radiation reaching the oceans. Simply go to Climate4You and the data is all there. Climate scientists simply don’t look. They exclusively focus on CO2. Clouds decrease, more solar radiation reaches the oceans, the oceans warm, global temperatures increase. Science 101, a course Climate Scientists seem to have skipped.
Is this a problem of semantics? Income and Expenses. Your visable radiation is income. Joules moving from the ocean to the atmosphere is an expense. You can warm the oceans by keeping income constant and reducing expenses. You can reduce income by X but reduces expenses by 2X and have warmer oceans. Accounting picks up on something universal in my opinion. Simple math. In my example, the oceans are a balance sheet. You have the beginning net worth, plus income, minus expenses equals the ending net worth. None of what you think short of something like a blackhole in our vicinity can change what happens with the accounting, at any time or place. These same accounting truisms are found in physics unless we are talking about QM which I don’t know enough about.
Asymmetric ozone distribution is seen throughout the stratosphere, and the polar vortex is shifted toward Europe, which will allow Siberian air to flow deep into the American continent.
https://i.ibb.co/j32bxqf/gfs-z02-nh-f00.png
About Science:
Bret and Heather 100th DarkHorse Podcast Livestream: The Demolition of Dissent
Watch on Odysee, not Youtube.
Reminds me a lot of the climate wars and some people’s tactics.
There is indeed lots of connections to be made between the Dank Web’s contrarianism and AGW contrarianism:
https://decoding-the-gurus.captivate.fm/episode/special-episode-interview-with-stuart-neil-on-sars-cov-2
I think I all ready looked at that. Whatever one says about the IDW, the alternatives seem to have less value. I think it would be a great thing if you targeted Michael Malice. He may be my number one Guru. Best quality? Russian background.
BTW. I can’t remember what your Twitter name is?
> the alternatives seem
To you they may seem, R.
I can see why you like Michael Krechmer. As a Redditor put it, very little of what he says is nuanced, thoughtful, erudite, or interesting.
W:
For decades I’ve been trying to explain what libertarianism is? He does a great job of it even though he calls it anarchy. I am unaware what Redditor thinks of him. I am not sure I care.
One of the arguments against libertarianism is the suggestion poor children will not be educated. Which we could argue has all ready happened. While our rulers children are educated. To try to genralize what he says, the criticisms of libertarianism is a description of the current system’s flaws. As government’s take of the economy increases, this will only become more apparent. His banner argument these days is in the ballpark of a national divorce. Would you rather I follow some fraud of a Republican?
I’d ask more study on your part:
“YOUR WELCOME” with Michael Malice #175: Dr. Debra Soh
> I am not sure I care.
Neither do I, R.
If Michael says he’s an anarcho-capitalist, believe him.
One day he’ll grow up.
W:
“One day he’ll grow up.”
He hangs out with adults it seem to me. But who really wants to grow up?
Counterpoint, R. Benjamin Shapiro, and Benjamin Shapiro:
https://youtu.be/gXE5bv3YpMs
Willard:
Thank you.
Willard:
I wondered if I should start defending Malice and if that would be of any valuea?
I just listened to the recent Bari Weiss podcast. They talked about The Cathedral. Malice introducted me to that, though he didn’t invent the idea, but I think it’s a key part of his message. And applicable as someone around here has found out.
https://www.reddit.com/r/MichaelMalice/comments/pnpxw8/what_is_the_cathedral_that_michael_is_always/
What makes a good guru? They teach you things. Even if you are a H.S. boy.
I learned some of the logic of computer programs in H.S. That logic is still true. No matter how people change the meaning of words. Or what new comes along.
At about 1:00:00 of the above video:
Women are being erased. The Patriarchy so Crafty.
I can’t recall who said this, I am a TERF.
That’s me. Thanks to the Orange One, I don’t care what name you call me. I think I’ll market a Red TERF hat like the MAGA hats.
Clintel launches a new organization for climate imaging
By David Wojick
https://www.cfact.org/2021/10/16/clintel-launches-a-new-organization-for-climate-imaging/
The beginning:
In his lengthy video presentation, CLINTEL President Guus Berkhout proposes creation of a new analytical facility — the Laboratory of Climate Imaging, Int. — to look at climate data in a new way. He calls it “Climate Imaging”, but it is not about pictures. It is a combination of data re-ordering, transformation and visualization. He also uses the additive Int to make clear that LCI is not an Intergovernmental, but an International organization. And, last but not least, he proposes to use imaging as an extra tool in model validation and policy making.
See the video here https://m.youtube.com/watch?v=Msy3sFneOdA
Here is how Professor Berkhout explains it: “Imaging is making the invisible visible. It is about collecting measurements with the aim to extract information for the detection and visualization of the dynamic properties of complex systems. This is done without understanding yet the internal mechanisms. Knowing these properties is often enough to make important decisions on how to cope with system changes. This is particularly important when decisions are urgent and cannot be delayed until reliable models have been developed. In addition, he proposes to use imaging for the improvement of model verification and, ultimately, for the evaluation of the costs and benefits of climate policies. His slogan is: “Let us think differently, let us think the imaging way.”
The core idea is that the climate debate is primarily focused on global averages – already for forty years – but global averaging minimizes the amount of information in the analysis. Huge amounts of detailed climate data disappear, being compressed into a single number, such as average global temperature over one, or even a few years.
Professor Berkhout proposes to reverse this process, which he calls unfolding the averages. It is only in this detailed data that the actual causes of climate change can be determined.
Much more in the article. Please share it.
Let the data speak!
‘The science behind climate change is really simple. If the earth absorbs more energy from the sun than it radiates into space the planet warms and the climate changes. Anything that happens on the planet doesn’t matter.’ JJBraccili
The US National Academy of Sciences (NAS) defined abrupt climate change as a new climate paradigm as long ago as 2002. A paradigm in the scientific sense is a theory that explains observations. A new science paradigm is one that better explains data – in this case climate data – than the old theory. The new theory says that climate change occurs as discrete jumps in the system caused by and at the pace of internal changes in a complex dynamical system. By far a more interesting aspect of climate science than simple radiative physics. Cold water upwells in the eastern Pacific with Bjerkne feedback and closed cell in marine boundary layer stratocumulus persist reflecting sunlight and cooling the planet. Thermohaline circulation slows in periods of low summer insolation and there is runaway ice sheet feedback. Climate is more like a kaleidoscope – shake it up and a new pattern emerges – than a control knob with a linear gain.
In the words of Michael Ghil the ‘global climate system is composed of a number of subsystems – atmosphere, biosphere, cryosphere, hydrosphere and lithosphere – each of which has distinct characteristic times, from days and weeks to centuries and millennia. Each subsystem, moreover, has its own internal variability, all other things being constant, over a fairly broad range of time scales. These ranges overlap between one subsystem and another. The interactions between the subsystems thus give rise to climate variability on all time scales.’
Climate is not simple – it is a complex dynamical system we are just beginning to come to terms with.
I thought I explained that.
Climate change is two problems. You have the main problem which you can use classical thermodynamics to solve. Energy accumulation = Energy In – Energy Out. You don’t have to take a measurement on the planet to determine if that is a problem. It is fairly easy to find the cause.
Problem 2 is that the sun doesn’t warm the planet evenly. This sets up energy imbalances across the planet. Weather is how the planet copes with the imbalances. Climate is the average measure of weather over a period of time.
Problem 1 impacts Problem 2 profoundly. Problem 2 has very little or no impact on Problem 1. I’m an engineer. That make me a pragmatist. Problem 2 doesn’t interest me. My sole focus in on Problem 1 and how to deal with it.
The fossil fuel industry is going to be promoting a mitigate and adapt solution. In other words, deal with the effects of Problem 2 and do nothing about Problem 1. If that sounds nutty, that’s because it is.
Conflating science – even your simplistic science – is never treasonable. The rational response to both natural variability and anthropogenic warming is to build resilient infrastructure, conserve and restore agricultural land and global commons and to deploy fast neutron nuclear fission engines.
Anthropogenic warming is superimposed on planetary spatiotemporal chaotic change. Both result in changes to top of atmosphere energy dynamics. Reflected in the first order differential global energy equation. The change in work and heat is equal to energy in less energy out – by the first law of thermodynamics.
d(w&h)/dt = Ein – Eout
The essence of change is in global scale turbulent dynamics with internal feedbacks in ice, cloud, biology, hydrology… In which climate is an emergent property of internal processes in which there are shifts between fractionally dimensioned state spaces at momentary to millennial scales. Tipping points are the fundamental mode of operation.
‘“Fluid dynamics is a field theory. This means that the solutions of the Navier Stokes partial differential equations are fields – functions f(x,y,z,t) like velocity and pressure fields. The “phase space” of fluid dynamics is a Hilbert space where the elements are fields (functions). This Hilbert space is uncountably infinite dimensional (the L2 space of square integrable functions) and exactly the same as the one used to study quantum mechanics and more generally any PDE system.
This above mentioned fundamental property, which applies to the even broader climate system of which fluid dynamics is just one part, is what makes the difference between temporal and spatio- temporal chaos.” https://pielkeclimatesci.wordpress.com/2011/03/07/a-new-view-of-the-climate-system-involving-spatio-temporal-chaos/
This is the dominant climate science paradigm.
Robert I. Ellison commented:
In the words of Michael Ghil the ‘global climate system is composed of a number of subsystems………..The interactions between the subsystems thus give rise to climate variability on all time scales.’
The Earth system can’t spontaneously heat up long-term, everywhere, without a cause. “Internal variability” can’t cause such a thing — only external variability, external forcing can. Changes in solar irradiance. Forcings due to orbital variations. Volcanic emissions of CO2. Emissions of CO2 and other GHGs due to humans digging up fossil fuels and burning them.
Clouds don’t spontaneously rearrange on their own and change the long-term climate. Nor do ocean currents. Those do so in response to external forcings that are the primary motivators.
Robert Ellison gets constantly excited by a few years of clouds parting in one part of the world or ocean currents changing in another, always imagining this is finally the indication that INTERNAL VARIABILITY is responsible for climate change, never EVER realizing that these are feedbacks to external forcings, not real forcings themselves.
He gets fooled by these changes time and time again. I’m sure he will continue to do so many times still, parading them here as sure, he thinks, signs that INTERNAL VARIABILITY causes a large part of modern climate change, not human influence.
His misunderstanding is a result of his biases, which are clear to see (staunchly free market capitalism, for example, despite its obvious failures which he refuses to even acknowledge, let alone discuss. Indeed, he wants more of them). And it’s getting pretty tiring and, as others here see too, he’s getting quite ignorable.
Chief? Of nothing I’ve seen. Elevated without cause, can’t handle being challenged.
T
That’s Chief Hydrological and Hydrodynamical Engineer. Cecil Terwilliger (brother to Sideshow Bob) was Springfield’s Chief Hydrological and Hydrodynamical Engineer. He opined that this was a sacred vocation in some cultures. The more I thought about this the more it resonated with me. I am an hydrologist by training, profession and (much more) through a deep fascination with water in all its power and beauty. Given the importance of water to us practically and symbolically, there is more than an element of the sacred.’
It’s a bit dated – but it shows how much ahead of David’s curve I am.
Hung up in moderation. Here’s the link I hope.
https://judithcurry.com/2011/02/09/decadal-variability-of-clouds/
My solutions – btw – include building resilient infrastructure for whatever surprises nature throws at us, conserving and restoring agricultural lands and ecosystems and deploying advanced nuclear engines.
20 are in development in the
‘The Department of Energy has selected General Atomics’ electromagnetic systems business to develop a 50-megawatt electric reactor concept under a cost-shared partnership.
GA-EMS partnered with nuclear steam supply systems developer Framatome to design a reactor that will include load-following features and integrate with intermittent or renewable power sources as part of the Advanced Reactor Concepts-20 project, General Atomics said Wednesday.
The three-year conceptual design effort will receive funding support through DOE’s Advanced Reactor Demonstration initiative and the industry team will also develop power conversion, control and instrumentation systems.
Scott Forney, president of GA-EMS, said the business aims to apply its experience in TRIGA non-power nuclear and gas-cooled reactor development programs and mature fast modular reactor technology to support U.S. clean energy goals.
The group’s work also covers cost analysis and pre-application licensing.
General Atomics noted it expects the FMR design to be ready for demonstration by 2030 and commercial availability in the mid-2030s.
Struggling with my keyboard…
The animation below shows the circulation over the Bering Sea. The low from the west is now moving toward the Bering Strait along a jet stream that will push air from the north over Canada. There we will see a frigid high. The polar vortex blockage in the lower stratosphere over the Bering Sea will be stronger the weaker the solar wind magnetic field becomes.
https://i.ibb.co/xGrPNJP/mimictpw-alaska-latest.gif
https://i.ibb.co/xh1B4B2/latest2day.gif
The good news for California is snowfall in the mountains.
My posts are not going through. Just checking if it still works in general chat.
Questions for JJ. Let’s see if it goes through in small portions.
1) What is the definition of Global warming according to “consensus climate science? What is the actual non-circumstantial link/evidence provided that proves causal relationship between GW and CO2 concentration?
2) Are you still standing by this stupid statement: “”The water cycle has NO impact on earth’s energy balance as I have shown. No impact on earth’s energy balance, no impact on climate.” Or do you want to tell NASA on how stupid they are for claiming the following: ” This CYCLING OF WATER is intimately linked with energy exchanges among the atmosphere, ocean, and land that DETERMINE the Earth’s CLIMATE and cause much of natural climate variability”
3) Do you know the difference between translational and vibrational kinetic energy? I strongly suspect that you do not ;)))) One is responsible for temperature of the gas another is responsible for characteristic IR absorption.
4) What is your source on why latent heat cannot be converted to IR radiation? I’m sure it is very solid one. ….. Ah, I remember, you mentioned: “I talked to a physicist friend this afternoon. His answer was no.” You are really a solid debater.
Carbon dioxide has 9 degrees of freedom – 3 each rotational, vibrational and translational. Photon absorption and emission happens with quantum jumps in electron orbits.
Water vapour molecules lose heat – kinetic energy – as they rise in the atmosphere. At the condensation point intermolecular attraction forces dominate and a phase transition occurs.
No great mystery – baby physics – but for the sake of scientific veracity I find myself correcting Isakov again. For which I will be condemned as anathema. 😊
Carbon dioxide has 9 degrees of freedom – 3 each rotational, vibrational and translational. Photon absorption and emission happens with quantum jumps in electron orbits.
Water vapour molecules lose heat – kinetic energy – as they rise in the atmosphere. At the condensation point intermolecular attraction forces dominate and a phase transition occurs.
No great mystery – baby physics – but for the sake of scientific veracity I find myself correcting Isakov again. For which I will be condemned as anathema. 😊””
Nothing to condemn here. You are a typical example of Dunnig-Kruger effect. I’m wasting my time in trying to argue with you. Hopeless
I don’t expect rational or civil discourse from Isakov. He was wildly wide of the mark on CO2 degrees of freedom – the possible ways a molecule can move – and physics of photon absorption and emission. Along with having an odd perspective on water vapor
“I don’t expect rational or civil discourse from Isakov.”
This is just too hilarious to ignore.
So I ask JJ, if he knows the the difference between translational and vibrational kinetic energy. I even clarify that one is responsible for temperature of the gas another is responsible for characteristic IR absorption.
In response Robert decides to demonstrate Dunning-Kruger effect in action. He informs me about 9 degrees of freedom of CO2. How is it related to the difference between vibrational and translation kinetic energy? – don’t know. Why is he mentioning only CO2? – don’t know. Why 9 degrees of freedom are important? – don’t know. I’m sure it wall sounded profound for him, but it was a useless statement. While it should be a general knowledge that temperature of gasses is defined only through translational kinetic energy. It is also a common knowledge that characteristic absorption and emissions are defined only through vibrational kinetic energy – it doesn’t matter what is the translational speed of the molecule, it will absorb at a particular wavelength independent of that speed (we ignore doppler effect here). Basic concepts but Robert and JJ seem to be oblivious to it.
And now he says: ” He was wildly wide of the mark on CO2 degrees of freedom – the possible ways a molecule can move – and physics of photon absorption and emission”.
SO Robert brings up CO2 degrees of freedom for no reason and with zero connection to the topic in hand and then accuses me of being wildly of the mark on CO2 degrees of freedom. How can I be wildly of the mark about the topic I didn’t talk about? – don’t know.
Seriously pathetic. Disgusting arrogance. Robert is write because Robert said that he is right.
Degrees of freedom are the numbers of ways the molecule is free to move – 9 in total – vibrational, rotational and translational. Look it up. Absorption and emission happen with quantum jumps in electron orbits. Look it up and don’t believe a word from Isakov.
“”Degrees of freedom are the numbers of ways the molecule is free to move – 9 in total – vibrational, rotational and translational. Look it up. Absorption and emission happen with quantum jumps in electron orbits. Look it up and don’t believe a word from Isakov”
You are getting desperate. “Absorption and emission happen with quantum jumps in electron orbits” – don’t you know the difference between emissions from atoms and from molecules? Emission from vibrational states is the characteristic changes in a dipole moment not a jump of an individual atom in an atom. You are crumbling under the weight of your own arrogance.
An explanation simple enough for me. The vibrational states I believe – based on a comment from someone who – unlike Isakov – seemed to know what he was talking about – involves hybrid molecular electron orbits.
https://scied.ucar.edu/learning-zone/how-climate-works/carbon-dioxide-absorbs-and-re-emits-infrared-radiation
“An explanation simple enough for me. The vibrational states I believe”
Good. So Robert confirms that he knows nothing himself but he just “BELIEVES comment of SOMEONE who SEEMED to know what he was talking about”. That was my point after few first comments from Robert. He is a believer and cult member.
” involves hybrid molecular electron orbits.” – your link doesn’t include such term. Maybe you need to go and clarify with SOMEONE. Maybe it is not his/her fault. Maybe it just SEEMED to you wrongly.
Or maybe read encyclopedia.
https://www.britannica.com/science/spectroscopy/Theory-of-molecular-spectra
Does Isakov published science to his credit? Otherwise most of what we know is from more or less credible sources. We are taught in science and engineering to recognise credible sources. Isakov I would judge to be not at all credible.
Robert, you are grasping at straws here. My credentials are irrelevant.
“We are taught in science and engineering to recognise credible sources” – I do not know who was teaching you, but I warn you, they sound like a cult.
I actually have degrees in engineering and science (physics) and when I was taught it was to use brains first of all. Second, use sources correctly because it can save you a lot of precious time by standing on the shoulders of giants and because you have to be sure to give credit to their work. Not once I was told that works of the past are infallible, no matter how credible are the sources. We were penalized if we ever said “I believe”. It was a worst sin during the exam. You either know or your do not know, and when you do not know you can hypothesize with clear definitions and assumption. The attitude in true science is that everyone gets excited if “consensus understanding” is wrong in any aspect. This is the most interesting part.
Now, in theology the most important part is to follow a freaking 2000 year old book to a letter. DO NOT DISOBEY THE TEACHING AND PRIESTS. Climate “science” is behaving like theology. And it has very devoted Zealots and Robert is a good example.
But still Robert, why did you run away from your “Absorption and emission happen with quantum jumps in electron orbits”? Show me the source that vibrational models in molecules involve jumps of electron orbits. It should be easy for such a devoted theological scholar to to find the relevant credible source. ;))) Don’t be shy. Do it.
Note that Isakov of almost exclusively odd long winded rants. Let him show that he understands the difference between radiative forcing and energy imbalance. That would be more pertinent than the nonsense that molecules have no electrons. But I am of course utterly bored with unscience and absurd recriminations.
so sad for Robert. So much arrogance and all dissipated in a fart of personal attacks, as usual.
All you had to explain is difference between vibrational and translation kinetic energies. It was you who decide to claim that absorption in molecules is governed by electron jumps between orbits. you screwed up and now do not know how to escape your stupid claim. And of course admitting that you screwed up is not an option for you. SO you are stuck. The only options that is left is to go personal at me.
And finally, you might be surprised but there are different types of kinetic energies: radiant, thermal, sound, electrical and mechanical. Notice that radiant is one of them ;)))
Isakov from the start launched absurd cultist rants. Now in utter hypocrisy he accuses me of insulting him.
To: ID Part I
First, let me give you a piece of advice. If you are writing a lengthy response, compose it in a word processor and then paste it into the response box. Be sure to save it often. Windows has this nasty habit of going into the blue screen of death mode now and then. Also, you get the benefit of any spell and grammar checker you have.
I’m going to respond to your current post in multiple posts to avoid the long post problem.
“My arguments are based on clear definitions, stated assumptions and supported by relevant references.”
Really? Time for the golden oldies. How about this gem?
“But for me, more important part would be work done. As I estimated earlier 1-2 percent of water vapor in the atmosphere is continuously cycled, so we can assume similar timescales with heat input. So we get 10^14 kg of water that is constantly brought to a height of 10000 m. This is 10^19 Joules equivalent potential energy. And with Sun input being 5*10^20, the generated potential energy corresponds to 2% of the heat input. Way larger than even your 0.25% radiative forcing. How is it that you ignore this component in your energy balance equation.”
You were trying to discredit climate science because a work term was not included in the accepted form of earth’s energy balance. The first thing wrong in your “analysis” is that you neglected that the water vapor condenses and returns to earth losing all that potential energy. The second thing is that earth’s energy balance is between the planet + atmosphere and outer space you can’t do work to outer space because it is vaccum. You need an opposing force (pressure in outer space) to do work. What clear definitions, assumptions, and references did you use for that brilliant analysis?
Another gem from the same post.
“Now if we consider your claim that H2O is condensing by loosing kinetic energy to surrounding air and not by radiation, then the question is how that surrounding air would loose the energy? N2 and O2 are really bad IR emitters. Are you seriously not seeing the problem in your logic?”
That is where you were arguing that condensing was not being done by kinetic energy transfer but by radiation from H2O molecules. The kinetic energy transfer causes the temperature of the surrounding molecules to rise. There are two modes of transfer. The heat transfer is from the atmosphere to the surface. That is a function of the temperature difference between the atmosphere and the surface. The direction of heat transfer is from the surface to the atmosphere. The higher atmospheric temperature lowers the heat transfer from the surface to the atmosphere, effectively returning some of the latent heat to the earth. The other is by radiant heat transfer. The kinetic energy from the latent heat is transferred to all the greenhouse gases, and they radiate it. They radiate it in all directions. About 50% winds up going to space, and 50% goes to the
To: ID Part II
surface. Most of the latent heat returns to the earth. I’ll discuss the impact of the latent heat going to space when I discuss the water cycle.
“If, for instance, CO2 concentrations are doubled, then the absorption would increase by 4 W/m2, but once the water vapor and clouds react, the absorption increases by almost 20 W/m2 — demonstrating that (in the GISS climate model, at least) the “feedbacks” are amplifying the effects of the initial radiative forcing from CO2 alone” Even most ardent supporters of consensus science do not claim that CO2 is the main driver. They claim that it is the trigger, but most of Radiative Forcing is done my water vapour in the atmosphere.”
Do you know the meaning of the term driver? If I add CO2 to the atmosphere, the temperature of the atmosphere rises. If I remove it, it falls. The ONLY reason H2O has any impact is that CO2 has caused the atmosphere’s temperature to rise. H2O AMPLIFIES the effect of CO2 — it doesn’t cause it. That’s what a driver does. CO2 is the driver of climate change.
If we continually added a substantial amount of CH4 to that atmosphere and no CO2, CH4 would be the driver. Just because there is a lot of something in the atmosphere doesn’t mean it’s having an impact. You got to get over this “size” obsession of yours. Sometimes size is important, and sometimes it’s not. A psychiatrist would have a field day psychoanalyzing you.
“What I was explaining to you is that latent heat during evaporation (not boiling) is governed by activation energy. Maxwell-Boltzmann distributions are valid for all fluids, not just gases. When you plot M-B for liquid water and for water vapour the shape will be generally the same, just shifted. But liquid water distribution will have a distinct kinetic energy value, called activation energy. Molecules that have translational kinetic energy above activation energy can escape the surface. Activation energy in thermodynamic system is not directly related to chemical bonds, as you claim, but only to the surface tension. And surface is the primary distinguishing property between gasses and liquids. Unfortunately school education confused generations of students regarding this fact, with stupid stronger chemical bonds in liquids.”
That was a word salad of BS. I never heard of activation energy involved with vaporization. You’re talking to the wrong person to try to get away with that. There is a field of study called mass transfer that deals with this phenomenon. The best reference is Mass Transfer Operations by Treybal. For evaporation, the equation would be the mass transfer rate = the mass transfer coefficient * the change in concentration between the liquid and vapor phase. In this case, the liquid concentration would be the vapor pressure of water at the temperature of the liquid, and the vapor phase concentration would be the partial pressure of water in the vapor phase. Nowhere in that book is the Maxwell-Boltzman distribution mentioned. BTW the equation is valid for both evaporation and condensation.
To: ID Part 3
Then I pulled out my copy of The Properties of Gas and Liquids by Prausnitz et al. Prausnitz is considered THE expert in property estimation. I looked up surface tension, and it had 5 or 6 methods of estimating surface tension — no mention of the Maxwell-Boltzman distribution. You should also know that viscosity is much more important than surface tension in determining mass transfer rates. All of that BS trying to prove that latent heat can be converted directly into IR — it can’t.
“When did I say that CO2 has NO effect? I always clearly stated that CO2 is a GHG. The thing is that it is not anywhere as critical as often claimed.”
Your “theory” that cleaning the oceans is the solution to climate change is a joke. The idea that oil products in the oceans are causing climate change is a joke. To be a source of climate change, the effect has to be continually increasing by substantial amounts. Not only that, the oceans are not static, and they continually churn the surface. Ever hear of waves? What your talking about would require a calm ocean. Then there is the earth’s IR spectrograph.
“1) What is the definition of Global warming according to “consensus climate science? What is the actual non-circumstantial link/evidence provided that proves causal relationship between GW and CO2 concentration?”
I already answered that. Go to the link I provided you to my post on the subject on Quora
“2) Are you still standing by this stupid statement: “”The water cycle has NO impact on earth’s energy balance as I have shown. No impact on earth’s energy balance, no impact on climate.” Or do you want to tell NASA on how stupid they are for claiming the following: ” This CYCLING OF WATER is intimately linked with energy exchanges among the atmosphere, ocean, and land that DETERMINE the Earth’s CLIMATE and cause much of natural climate variability””
Let me put this water cycle nonsense to bed once and for all. In my post before this one, which was my long post that got delayed for God only knows why I did an energy balance where I said the water cycle had no impact, but it did. If you didn’t notice, the energy radiated from the earth dropped from 240 TW to 239. That means the temperature will be lower. The water cycle will have an impact, but the problem needs more analysis to assess the real impact.
We need to evaluate the impact of adding CO2 to the atmosphere on the energy balance and the water cycle. Start with the earth in energy balance and introduce any amount of CO2 you like. That will result in R back radiation to the earth from CO2 and its impact on H2O in the atmosphere. That R back radiation is added to the absorbed solar radiation (Assuming all the R back radiation gets absorbed or just say R is the back radiation absorbed. It doesn’t matter). A fraction of the total energy absorbed (w) winds up generating evaporated water. The additional energy carried to the atmosphere by evaporation is wR. That water vapor is condensed, and latent heat transfers by
To: ID Part 4
sensible heat and IR. About 0.5 of the latent heat escapes the atmosphere. If none escaped the atmosphere, there would be no impact. It would be recycled back to the earth. You can take the back radiation and subtract the amount that escapes the atmosphere. The back radiation then becomes R – 0.5wR. R will always be > 0.5wR. The net effect will be to reduce the greenhouse effect of CO2. The planet will still warm and get to the same final temperature, but it will take longer. That is not a game-changer, and the water cycle doesn’t have the significant impact you claimed on climate change.
3) Do you know the difference between translational and vibrational kinetic energy? I strongly suspect that you do not ;)))) One is responsible for temperature of the gas another is responsible for characteristic IR absorption.
Yes, I do. It should be evident from the material I posted. As I said, reading comprehension is not your strong suit.
4) What is your source on why latent heat cannot be converted to IR radiation? I’m sure it is very solid one. ….. Ah, I remember, you mentioned: “I talked to a physicist friend this afternoon. His answer was no.” You are really a solid debater.
You suck at this. It’s not surprising why you hold the views you do.
I discussed this with my physicist friend because I was giving you the benefit of the doubt. There could be a very remote possibility you were right, and I now have no doubt you are wrong.
No one source contains the explanation I gave on boiling water. I was surprised I couldn’t find one. They talk about boiling and constant temperature, and latent heat, but they give no mechanism. I searched on a physics blog for answers. There was a discussion of if the kinetic energy of vapor and liquid in equilibrium were the same. The best response was that if the temperature is the same, the kinetic energy is the same because the measuring device doesn’t know if it’s in a vapor or liquid. The vapor-liquid share a common interface, and at equilibrium, the kinetic energies will be the same.
The rest was just a thought experiment. Consider liquid water molecules. They are held together by hydrogen bonding. To break the bond, force must be applied. IR cannot provide force; kinetic energy can. If kinetic energy is exchanged, it also means momentum changes. Change in momentum means force is produced. The force acts through the separation distance. Work is done. Latent heat is the work done to separate the molecules.
The rest is pretty straightforward. You add kinetic energy to bring the liquid water to a boil. If there were no hydrogen bonding, the molecules would be further apart. Break the bond, and the existing kinetic energy causes the molecules to separate to the distance proper for the amount of kinetic energy present. The density drops, and you wind up with a vapor phase with the same temperature and kinetic energy as the liquid phase.
Chief –
Just because I refuse to give up on you, I’ll give you another chance to be accountable.
As I’ve documented many times you were ridiculously wrong when you declared a 7-day moving average of COVID deaths in Florida to be 18 on Oct. 3. It’s now up to 126, per the CDC.
You said 18 was “definitive.”. You said I was ‘nuts’ when I told you that there would be a lag in the official recording of deaths. You said that the articles that explained the cause of the lag were ‘yellow journalism.”
”
So you were off by 700%
When do you plan on acknowledging your huge error? Is simple math a problem for you?
Is it really that hard for you to just acknowledge an error? Even one do obvious and so easy to document?
But then I have given up on Joshlings obsessive misrepresentations.
Oh for Gods sake. All matter above absolute zero emits thermal energy. Temperature – the measure of kinetic energy – in Earth’s nonequilibrium thermodynamic system will rise to a point where energy out equals energy in. In space the energy is electromagnetic. On Earth there are other forms. Greenhouse gases have cross sections that resonate at specific photon frequencies rather than being transparent as they are to visible light. This property allows energy in but scatters outgoing photons including back towards the surface.
Why is this not simply taken as read? We could then discuss the interesting topic of what, why and how cloud is changing. Instead we get an endless reiteration of idiosyncratic unscience. And – I might add – joshlings weirdly obsessive and utterly out of place misrepresentation. It is all bogglingly insane.
Chief –
Remember when you said this?:
Here, let me try to fix this:
Chief –
Remember when you said this?:
Do you know what the deaths for the week to October 7 were?
The deaths for the week to October 7 were 555, per the CDC
And that number may go up further still.
Will you every just acknowledge being wrong. Obviously wrong? Very wrong?
Isakov Dmitry wrote:
Water vapour molecules lose heat – kinetic energy – as they rise in the atmosphere.
What’s the mean free path of an air molecule?
How far does a water vapor molecule rise before it collides with another molecule? How much kinetic energy does it lose in that time? How much energy is gained by the molecule coming down (?) it collides with? Isn’t there a net balance of up and down molecules, otherwise the atmosphere would be losing air from either the top or bottom of the atmosphere?
Isakov from the start launched absurd cultist rants. Now in utter hypocrisy he accuses me of insulting him.
5) related to 4). You provided a school level estimation for dew point inside the closed box. Unfortunately when you were given a source that contradicts your estimate you decided to ignore it. But maybe you can try again. Can you explain how the relative humidity can be roughly constant (60-80%) throughout the troposphere above the tropics? And then after after the top of the troposphere is reached the humidity sharply drops without the need for going through saturation condition (dew point)? Why do they call it Radiative-Convective Equilibrium? Can you write to the journal and tell them to stop writing stupid things like this :“At a height of 11 km, the RADIATIVE COOLING and associated subsidence lead to a halving of the relative
@Ireneusz Palmowski | October 18, 2021 at 4:30 am | Reply
And the bad news for California is that the id-eeee-ots in charge will squander any water they get.
An unusually strong drop in tropopause height over California could mean severe freezing temperatures overnight in California’s mountains.
https://i.ibb.co/G9kdy4b/gfs-hgt-trop-NA-f012.png
There have been 440 comments here so far, and it appears climate science is not yet settled. I have a computer program that predicts after 500 comments here, climate science WILL be settled. This computer program had previously predicted the climate would continue to get warmer, unless it gets cooler.
“Science is settled” only means that the basic ideas are well understood. It certainly does not mean that climate science is definitive.
See “But Science” in the Bingo:
https://tinyurl.com/the-bingo
Depends on what you are talking about. if you talking about whether or not the planet is warming and what is causing the warming, that’s definitive. If you talking about the modeling and predicting what is going to happen in the future. That’s not.
Which part of “the basic ideas” you do not get, JJ?
“But Predictions” and “But Moduiz” are other Climate Ball Bingo squares:
https://andthentheresphysics.wordpress.com/2021/05/23/the-bingo-core/
You implied that climate science is not definitive. I disagree. Parts of it are.
Again, JJ: which part “the basic ideas are well understood” you do not get?
https://en.wikipedia.org/wiki/Effective_temperature
Earth effective temperature
Main article: Earth’s energy budget
The Earth has an albedo of about 0.306.[9] The emissivity is dependent on the type of surface and many climate models set the value of the Earth’s emissivity to 1. However, a more realistic value is 0.96.[10] The Earth is a fairly fast rotator so the area ratio can be estimated as 1/4.
The other variables are constant. This calculation gives us an effective temperature of the Earth of 252 K (−21 °C). The average temperature of the Earth is 288 K (15 °C). One reason for the difference between the two values is due to the greenhouse effect, which increases the average temperature of the Earth’s surface.
288K-255K = 33oC
When I first learned the current science claims there is a +33oC Greenhouse Warming Effect on Earth’s surface I became very much surprised… It is impossible, I thought – some major mistake has been made in this Wikipedia Article…
I started searching and reading everything I could find on the matter – but NO – it was the same number +33oC everywhere I looked.
Unbelievable, I still don’t accept it, thin Earth’s atmosphere is very much transparent both ways – in and out. Because Earth’s atmosphere is very thin…
https://www.cristos-vournas.com
288 K is the temperature of the surface. It is not the temperature at the average emission altitude.
Yes, Robert, thank you.
But NO – it was the same number +33oC everywhere I looked.
https://www.cristos-vournas.com
33 k is calculated with the Stefan-Boltzmann law for a planet without an atmosphere. I suggest not taking it as definitive.
Chief –
Why would anyone think you’re credible on complex issues when you can’t even get the simplest of issues correct – and then when it’s pointed out to you that you’re wrong on those simple issues you get hostile and avoid any level of accountability for your error?
But because I refuse to give up on you, I’ll give you another chance to be accountable.
As I’ve documented many times you were ridiculously wrong when you declared a 7-day moving average of COVID deaths for Oct. 3 in Florida to be 18. It’s now up to 126, per the CDC.
You said 18 was “definitive.”. You said I was ‘nuts’ when I told you that there would be a lag in the official recording of deaths. You said that the articles that explained the cause of the lag were ‘yellow journalism.”
So you were off by 700%
When do you plan on acknowledging your huge error? Is simple math a problem for you?
Is it really that hard for you to just acknowledge an error? Even one so obvious and so easy to document?
This is a wildly out of place misrepresentation obsessively repeated. The latest Florida Health report puts deaths in Florida for the previous week at 123. Deaths and cases continue to decline which is good for everyone but Joe Biden.
Robert I. Ellison commented:
33 k is calculated with the Stefan-Boltzmann law for a planet without an atmosphere. I suggest not taking it as definitive.
No. But Lacis et al’s model found the same number:
Lacis et al, Science 330, 2010, p 356-359, http://pubs.giss.nasa.gov/abs/la09300d.html
There is a greenhouse effect but I wouldn’t take Lacis as Gospel either.
Chief –
> This is a wildly out of place misrepresentation obsessively repeated.
I quoted you.
You’re lying and you lack integrity and accountability.
You were wrong.
You said i was “nuts” when I told you there was a significant lag in the recording of deaths.
You said the articles that explained the lag were “yellow journalism.”
You were off by 700%
You’re lying ans you lack integrity and accountability. Apparently tour incapable of acknowledging an obvious error.
The principle is to use the data from authoritative sources and not handwave madly at what might be.
https://watertechbyrie.files.wordpress.com/2021/10/compare-state-trends-13.png
It doesn’t show show what joshling wants it to show and he will go to any extreme and unconscionable lengths to deny that.
Robert I. Ellison commented: There is a greenhouse effect but I wouldn’t take Lacis as Gospel either.
There is no “gospel” in science LOL you fool.
Do you find any problems with their methodology?
Chief –
Per the CDC you were off by 700%
I quoted you. The CDC’s number is 7 X your number
You have zero integrity.
You’re bizarrely incapable of just acknowledging your error.
What’s up with that?
Citing the available CDC number as I did is not error.
Chief –
I’m quoting you and demonstrating unambiguously that you were wrong.
You got hostile when I explained your error to you.
What is it about you that causes you to become hostile if someone points out your errors?
In regards Robert Ellison it is called Dunning-Kruger effect – a type of cognitive bias in which people believe that they are smarter and more capable than they really are. Essentially, low ability people do not possess the skills needed to recognize their own incompetence. The combination of poor self-awareness and low cognitive ability leads them to overestimate their own capabilities.
A great self-description. Now all you need is to get help for your condition.
I quoted the CDC in the context of declining cases and deaths in Florida. joshling is inveterately hostile with many repetitive, tawdry, salacious and fallacious comments. I think because of a lack of more substantive ideas. It is more than a little odd.
Chief –
> Citing the available CDC number as I did is not error
You cited numbers and I told you that they didn’t reflect the lag on the recording of deaths.
You said i was “nuts” and that the numbers were definitive.
I showed you articles that explained the cause of the lag. You called them “yellow journalism.”
The numbers increased by 700%
You know all of this but you’re pathetically trying to hide from it.
It’s bizarre.
Have a nice night. I’ll give you a chance to be accountable again tomorrow.
Again? I cited the CDC in the context of declining cases and deaths in Florida. It remains true.
https://watertechbyrie.files.wordpress.com/2021/10/compare-state-trends-13.png
I did not accept josling’s handwaving what might be 1000/s of deaths. He was wrong then and is wrong now. And a sane person would move on.
This is more junk science.
This whole theory is based on lowering the surface temperature where solar radiation is incident by spinning the planet, but it won’t raise the earth’s temperature by 33 C. All you are doing is increasing the heat transfer between the sun and the earth.
1. The sun is a powerful source of energy. Even if you dropped the surface temperature by 100 C it wouldn’t have much of an impact on heat transfer.
2. Spinning the planet has a diminishing effect on heat transfer. The greatest effect will be spinning the planet from a standstill. Double that spin and you will get less of a temperature drop than you did before. Double that and you will get less than the last and so on and so on. Your equation doesn’t allow for that.
3. You’ve defined that factor I discussed with you two different ways and neither makes sense to me.
4. If the spinning of the earth is causing all the temperature increase, then CO2 is not causing any. You have to explain the earth’s IR spectrograph that shows that CO2 has a significant impact on the earth’s radiant energy. Translation — the energy that CO2 is preventing from escaping to outer space didn’t disappear.
5. The effect you claim will be impacted by the diameter of the planet. I could be wrong, but I don’t remember seeing that in your equation
Temperature in Earth’s nonequilibrium thermodynamic system will rise to the point where energy out equals energy in. Spin doesn’t change that. This is of curse a dynamic energy equilibrium in which change is countered by the Planck feedback.
No, but spin can change the equilibrium temperature.
BS. Using the Stefan-Boltzmann approximation.
T = (j*/σ)^0.25
Where j* is equal to energy in and doesn’t change with spin.
Let’s take the moon. Start with a non-spinning moon. The temperature on the hot side is Thns, and the temperature of the sun is Ts. Heat transferred from the sun to the moon is proportional to (Ts**4 – Thns**4.). Assume a spinning planet has a uniform surface temperature Tms. The heat transferred from the sun to the moon is proportional (Ts**4 – Tms**4).
For a non-spinning planet, the temperature of the cold side is Tc. Let’s say that the temperature that the cold side of the moon radiates to is 0 K. For the non-spinning planet, the heat transferred from the moon to space is proportional to Tc**4. For the spinning planet, the heat transferred to space is Tms**4.
Heat absorbed for the non-spinning planet is proportional to (Ts**4 – Thns**4) – Tc**4 that is Ts**4 – (Thns**4 + Tc**4)
Heat absorbed for the spinning planet is proportional to (Ts**4 – Tms**4) – Tms**4 that is Ts**4 – 2Tms**4.
Difference between heat absorbed by a spinning planet and a non-spinning planet is Ts**4 – 2Tms**4 – (Ts**4 – (Thns**4 + Tc**4).
Thns**4 + Tc**4 – 2Tms**4
The difference between the heat absorbed by a spinning planet and a non-spinning planet is proportional to (Thns**4 – 2Tms**4) + Tc**4. For a spinning planet to absorb more heat than a non-spinning planet, Thns**4 > 2Tms**4.
What’s wrong with your analysis besides the fact that it’s amateurish. The radiation being radiated by the hot side should be subtracted from the incoming solar radiation. As I said, I suspected the effect of a rotating planet is small and can be neglected. With this analysis, I’m convinced.
You’re not as smart as you think you are. Next time you come at me, you will need to do your homework, or I’ll hand you your head every time.
Let’s stick to a spinning planet with an atmosphere and oceans. The temperature rises to a point at which energy out equals in. Now lets spin it up.
The theory that the poster presented was for a planet without an atmosphere. His conclusion was that the rotation of the earth without an atmosphere raised the temperature of the planet by 33 K. From that he concludes that greenhouse gases have no impact on the earth’s temperature.
Those equations apply anywhere, but, as I said, the effect is probably negligible.
It’s not my fault you have no idea what you are talking about.
My keyboard is prematurely posting… Where were we?
Spin up the planet and the temperature rises to a point where energy out equals energy in.
j* = σT1^4 = σT2^4 => T1 = T2
It’s amazing how far some can get their heads up their arses.
I guess you didn’t understand what I posted. Not surprising.
You have to take out the radiant energy from the hot side of the moon from the solar radiation energy to the moon to get the heat transfer equations and energy balance equations to agree. They have to agree.
Give up! You’re not going to win this one.
I guess you don’t understand the simple math I presented for a spinning planet.
Your simple math uses averages. It assume the moon is absorbing and emitting from it’s entire surface area at the same temperature. In reality, it’s absorbing in half it’s surface and emitting in the other half. The absorbing surface temperature is higher than the average radiant temperature and absorbing less. The emitting surface temperature is lower and emitting less.
Spin the planet and the absorbing surface temperature lowers and the emitting surface temperature rises. The absorbing side absorbs more and the emitting side emits more. If you use the Stefan-Boltzmann equation to come up with the average radiant temperature the more a planet emits the higher its temperature.
In the end it will all balance out. This isn’t rocket science.
Yes there is an average temperature of the Earth at which all incoming energy is reradiated out. I
Your “analysis” assumes the moon is absorbing solar energy and emitting energy across its entire surface evenly. It’s not. Spin the planet fast enough so the absorbing and emitting surface temperatures are the same and you will be right. Unfortunately, it doesn’t work that way and a non-spinning planet will absorb and emit less energy than a spinning planet but not-always as my math model proved.
You just don’t get it.
Spin the planet Earth up and the warm side has less time to warm and the dark side less time to cool – but the energy emitted must remain the same as energy in implying – as my math – reliant on physical laws – shows – the average temperature is the same.
For the moon energy in (not reflected) is some 300 W/m2. Start it spinning and energy in remains the same thus energy out and average temperature remains the same. You propose a violation of the 1st lot AND do not understand why. But I am tired of this and you.
In your world, if radiative forcing is not 0 then the earth is in violation of the first law.
That being said I sWhat math?
All I’ve seen is the Stefan-Boltzman equation and energy in = energy out. That is not the first law of thermodynamics. Energy in = energy out occurs at steady state and guess what? The temperature of the planet cannot change. Only when energy in is not equal to energy out does energy accumulate and the average temperature change.
at down and reconsidered my position. What convinced me that spinning the planet was not going to change the temperature was asking what was the temperature going to be if the spinning the planet resulted in a uniform planet surface temperature. The solar energy will be absorbed and emitted evenly across the planet. This is exactly what is assumed when we calculate the average temperature of the planet.
That doesn’t mean there couldn’t be a difference when the planet surface temperature is not uniform. I then postulated what would happen if a planet is rotated 180 degrees. It turns out that the hot side temperature is linked to the cold side temperature by energy balance and the planet’s temperature would be unaffected by the change. That was my mistake in the equations I developed. I didn’t link the temperatures. Even with that, it was evident from my equations the effect would be negligible. The equations just didn’t predict it would have no impact.
I’ll always admit when I make a mistake and I’m wrong. It’s unfortunate there are few posters willing to do the same.
SB is a true in principle for all nonequilibrium systems – energy out is proportional to temperature. To have a temperature rise solely as a result of spin creates energy out of nothing. One of us is wrong but you are such a smartarse it can’t be you.
It’s nice to philosophize, but the question of the effect of spin is a legitimate question that needs to be answered. That’s not the first time I’ve seen it asked. Waving your arms, stating the Stefan- Boltzmann equation saying in = out is not answering the question. Just because you think something may be true, doesn’t make it so.
Chief –
Just because I refuse to give up on you, I’ll give you another chance to be accountable.
As I’ve documented many times you were ridiculously wrong when you declared a 7-day moving average of COVID deaths in Florida to be 18 on Oct. 3. It’s now up to 126, per the CDC.
You said 18 was “definitive.”. You said I was ‘nuts’ when I told you that there would be a lag in the official recording of deaths. You said that the articles that explained the cause of the lag were ‘yellow journalism.”
”
So you were off by 700%
When do you plan on acknowledging your huge error? Is simple math a problem for you?
Is it really that hard for you to just acknowledge an error? Even one do obvious and so easy to document?
Yet again.
https://judithcurry.com/2021/10/10/radiative-energy-flux-variations-from-2000-2020/#comment-961833
Chief –
Yet again. You said the 7-day moving average for Oct. 3 was 18. And you said that number was “definitive.”
At that time I told you that number would get mcuj larger because there is a significant lag in the recording of deaths in Florida.
In response you said i was “nuts.”
When I showed you articles that explained the reason for the lag, you dismissed them and called them “yellow journalism.”
The number as of now is 126, per the CDC. That’s 700% higher than the number you said was “definitive.”
I have provided quotes to back ll of this up.
Your inability to just acknowledge your error reflects very badly on you, on your sense of integrity, and on your sense of accountability.
It’s also just bizarre.
Robert I. Ellison commented:
Using the Stefan-Boltzmann approximation.
T = (j*/σ)^0.25
Where j* is equal to energy in and doesn’t change with spin.
LOL. SB law assumes equilibrium. LOL.
Energy in is some 240 W/m2 – the Planck feedback ensures that energy out approaches energy in.
Just one of David’s many strange and enigmatic observations.
No s**t!
That 240 W/m2 has been corrected for albedo. Think of the hot side radiant energy of the moon as reflected energy. On the earth, it’s probably negligible.
Yes – energy in neglects reflected shortwave and is nominally equal to emitted IR. It’s measured as shortwave up. Earth albedo is some 0.3 – the moon some 0.12.
It’s odd what these guys think are significant Earth system science points. This is day one stuff – the interesting stuff comes much later.
Robert I. Ellison commented:
For the moon energy in (not reflected) is some 300 W/m2.
For the Moon energy in varies greatly by latitude and longitude, because it has no atmosphere. It is by no means a constant 300 W/m2.
Robert I. Ellison commented:
I guess you don’t understand the simple math I presented for a spinning planet.
Your “simple math” does not capture how heat can be retained on the dark side of a planet, and not lost to space, if the spin rate is fast enough.
JJBraccili wrote:
No, but spin can change the equilibrium temperature.
Yes.
This says it all.
The change in work and heat in the system is equal to energy in less energy out.
d(W&H)/dt = Ein – Ein
The negative Planck feedback – SB is derived from Planck’s law – drives the system towards energy equilibrium. It is fundamentally true.
Japanese oceanographers confirm the existence of an inter-basin stadium wave:
https://www.science.org/doi/10.1126/science.abh3295
Observations show that sea surface temperatures along the Gulf Stream and the Kuroshio Current tend to synchronize at decadal time scales. This synchronization, which we refer to as the boundary current synchronization (BCS), is reproduced in global climate models with high spatial resolution. Both in observations and model simulations, BCS is associated with meridional migrations of the atmospheric jet stream. Changes in the strength and path of the ocean currents associated with the jet shifts lead to the synchronicity of surface temperatures. Numerical simulations using a conceptual model and an atmospheric general circulation model are consistent with a notion that BCS is an interbasin air-sea coupled mode. Air temperature patterns similar to the one associated with BCS have been repeatedly observed, including in July of 1994 and 2018.
This is a very important observation, indicating that in the summer in the Atlantic and Pacific, the jet current acts with similar strength. The increase in strength of the jet current is most pronounced over the oceans and then moves over the continent.
In summer the stratosphere is completely separated from the troposphere, in winter the stratosphere through the polar vortex merges with the troposphere. However, this observation indicates that even in summer, solar activity has an effect on the jet current because it is similar in the Atlantic and Pacific.
https://i.ibb.co/c2p1Qpn/Screenshot-3.png
Below you can see the southern polar vortex in action. Winter in Antarctica continues.
https://i.ibb.co/4RGp3wN/zu-sh.gif
Thanks Phil and Ren
A few years ago I was reviewing these maps and looked at different dates randomly as far back as I could. I noticed this persistent anomaly but had no idea why it was there. Now, apparently I do.
Instead answering JJB or other CO2 gate keepers I would like to give some educational lecture on relative contribution of different GHG on absorption of LWIR from earth.
https://www.youtube.com/watch?v=lsMWUK4WGkk
Its a nice professor with a bowtie. It will be most surprising for JJB to find out that 93% of absorbed LWIR from earth is done by water vapour. CO2 is a fine tuning GHG, not the main one.
Isakov Dmitry commented:
It will be most surprising for JJB to find out that 93% of absorbed LWIR from earth is done by water vapour. CO2 is a fine tuning GHG, not the main one.
Educate yourself man. Please. Learn what this means: “Water vapor is a feedback, not a forcing.” Water vapor does not absorb more IR until the temperature increases. That increase is, today, caused by CO2 and CH4.
This is old science, understood for decades. Here you just look foolish.
“Water vapor does not absorb more IR until the temperature increases. That increase is, today, caused by CO2 and CH4”
Stop embarrassing yourself. Please. 93% of of IR radiation is absorbed by water vapour. The whole so called green house effect is controlled mainly by variations in water vapour concentration. The impact factor for water vapour is just 10 times larger than impact factor of CO2. It is simple logic. 10% change in water vapour content in any location on the planet will have higher effect than doubling of CO2 at the same location. What can’t you understand?
David Appell | October 19, 2021
“Isakov Dmitry commented:
It will be most surprising for JJB to find out that 93% of absorbed LWIR from earth is done by water vapour.”
–
Sounds like one of David’s usual “Go Brandon” misinterpretations.
We all know they are saying 93% for H2O really means 2-5%
for CO2.
Grow up David and stop forcing the issue, listen to the feedback.
David
It is not credible that water in all its forms, the much more powerful GHG than CO2, operates simply and exclusively as a feedback to the trace gas CO2. This is just wishful thinking and can’t be true. The tail does not wag the dog 🐕 .
Phil Salmon commented:
It is not credible that water in all its forms, the much more powerful GHG than CO2, operates simply and exclusively as a feedback to the trace gas CO2.
Don’t care what you think is credible, only physics matters.
Water vapor is a condensable greenhouse gas.
At constant temperature, the amount of it in the atmosphere is a constant. Hence so is its greenhouse forcing.
The concentration of water vapor only changes when the temperature of the atmosphere changes. That change now comes from anthropogenic gases like CO2, CH4, N2O, etc.
They increase the temperature. Water vapor concentration increases in turn, according to the Clausius-Claperyon equation, about 7% per degree C of warming.
Basic thermo.
Hence: “For climate change, water vapor is a feedback, not a forcing.”
Isakov Dmitry wrote:
Stop embarrassing yourself. Please. 93% of of IR radiation is absorbed by water vapour. The whole so called green house effect is controlled mainly by variations in water vapour concentration.
Water vapor concentration DOESN’T VARY at constant T.
Try to put more water vapor in the atmo, it just rains or snows out.
You can only put more water vapor in the atmo by increasing the atmo’s temperature.
Take an advanced course in thermodynamics, learn about phase transitions, learn the Clausius-Claperyon equation.
Isakov Dmitry wrote:
10% change in water vapour content in any location on the planet will have higher effect than doubling of CO2 at the same location. What can’t you understand?
LOLz. You can’t change water vapor concentration unless you first change the temperature.
Try, and it just rains or snows out.
Learn some physics.
“LOLz. You can’t change water vapor concentration unless you first change the temperature.
Try, and it just rains or snows out.
Learn some physics”
I totally blame school education for confusing people so badly about evaporation. Latent heat of vaporization is measured in kJ/kg, it is just a function of heat input vs the mass of evaporated substance. It is independent of temperature. That is why boiling of water will take place at constant temperature independent of how much energy you put in. Temperature is only coming into picture as a parameter determining how many molecules have kinetic energy above activation energy. Activation energy in turn is a function of surface tension. Surface tension is a complex function of pure substance properties, interface conditions (pressure and saturation levels in atmosphere) and contamination.
If you have the same puddle of water on the street at the same temperature of surrounding air the evaporation rate will be very different depending on following parameters: 1) source of heat; 2) heat transfer mechanism from the source of heat to the puddle; 3) air pressure above the puddle; 4) saturation level of air above the puddle; 5) dynamics of the saturation level of air – function of air speed; 6) contamination on the surface (pure water will evaporate faster than water with nanometric layer of oil on top of it.
I hope you can read it and think carefully before dismissing it out of hand. Your understanding of evaporation process is wrong. While the information is available on this topic. Please stop thinking that temperature is a determining factor in evaporation, it is not. You can perform evaporation experiments at your home if you do not believe me. For example contamination, take 2 dishes with same amount of water, but in one of them add a tiny drop of oil. Then leave them on a counter and observe which one will evaporate sooner. Ideally in a zone without wind, as you cannot control uniformity of wind for both dishes. Also avoid direct sun-light, both due to non-uniformity and the fact that the absorption of oil will be different. Try it and discover a whole new world for yourself. ;)))
Isakov Dmitry commented:
in response to David Appell:
I don’t even need to read your convoluted example — waste of time.
Water vapor is a feedback to climate change, not a forcing.
This is elementary climate science, known by everyone, and I’m not wasting my debating it with someone like you.
If you don’t understand physics that’s your problem. You’re wrong, period.
“I don’t even need to read your convoluted example — waste of time.
Water vapor is a feedback to climate change, not a forcing.
This is elementary climate science, known by everyone, and I’m not wasting my debating it with someone like you.
If you don’t understand physics that’s your problem. You’re wrong, period”
That is a shame. Another example of Dunning-Kruger effect. And more importantly another confirmation that “climate science” is not a science but a cult with claims if infallibility.
‘Latent heat of vaporization is measured in kJ/kg, it is just a function of heat input vs the mass of evaporated substance. It is independent of temperature.’
Evaporation proceeds faster at higher temps – all things being equal. It is a function of the Maxwell-Boltzmann distribution of molecular velocities. At the boiling point it is simply that the mass is losing heat as fast as it gains heat. The Clausius–Clapeyron relation show why warmer air can hold more water vapor. Which is the relevant feedback.
Isakov’s bombastic ignorance is truly astonishing. Is he here because he has worn out his welcome elsewhere?
Isakov talks about Dunning-Kruger instead of physics. The sure sign of a scientific amateur.
Isakov Dmitry commented:If you have the same puddle of water on the street at the same temperature of surrounding air the evaporation rate will be very different depending on following parameters: 1) source of heat; 2) heat transfer mechanism from the source of heat to the puddle; 3) air pressure above the puddle; 4) saturation level of air above the puddle; 5) dynamics of the saturation level of air – function of air speed; 6) contamination on the surface (pure water will evaporate faster than water with nanometric layer of oil on top of it.
We’re not talking about all that crap.
We’re talking about a gas with a condensable gas mixed in, like water vapor.
You know, like the atmosphere.
Get it now? No puddles, no contamination, no other sources of heat, no oil stains or gum wrappers or dog piddle mixed in.
Just water vapor in the air.
Got it? Now, Clausius-Claperyon.
“We’re not talking about all that crap.
We’re talking about a gas with a condensable gas mixed in, like water vapor.
You know, like the atmosphere.
Get it now? No puddles, no contamination, no other sources of heat, no oil stains or gum wrappers or dog piddle mixed in.
Just water vapor in the air.
Got it? Now, Clausius-Claperyon”
You are embarrassment, arrogant embarrassment.
Clausius–Clapeyron relationship is specifically defined only for the condition when both phases (gas and liquid) are present. How illiterate can you be even about the things that you use as argument?
Also, what does Clausius-Clapeyron talks about. It talks about pressure and Latent heat of vaporization constant. They determine your surface condition. And it is only determined for pure substance. JUST LEARN ABOUT THE SUBJECT THAT YOU ARE TRYING TO TAL ABOUT
Isakov Dmitry wrote:
Also, what does Clausius-Clapeyron talks about. It talks about pressure and Latent heat of vaporization constant. They determine your surface condition. And it is only determined for pure substance. JUST LEARN ABOUT THE SUBJECT THAT YOU ARE TRYING TO TAL ABOUT
You are out of your league.
Go ask any climate scientist. I dare you. Ask about water vapor.
Report back.
“climate science” – is not science.
Please read books on Physics. It is not that hard. Just try
Isakov Dmitry commented:
“climate science” – is not science.
LOL. Read a textbook like Pierrehumbert’s or Dessler’s and tell me that’s not science.
Please read books on Physics.
I’m sure I’ve read many more of them than you have.
From a professor of atmospheric science at U of Washington:
third page:
“Why water vapor content will increase with global warming
* Feedback on warming, not a forcing”
https://atmos.washington.edu/~dargan/587/587_3.pdf
(emphasis mine)
HAHAHAHAHAHAHAHAHAHAHAHAHAHAHAHAAAAAA
Bible is true because Bible says it is true!!! A very good argument for cult member.
If it is accepted on sound scientific grounds that a warmer atmosphere holds more water vapour then that is the feedback. The rest is Isakov’s ridiculously bombastic contrarian curmudgeon BS.
You and our arguments remind me this
https://www.youtube.com/watch?v=16r98zeAaoU
Thanks. It was hilarious then and it is hilarious now, when you express you arguments.
He may accept that warmer air holds more water vapor or not. The latter is difficult to argue scientifically but weirder things have happened. But rants are not rational arguments.
“He may accept that warmer air holds more water vapor or not. The latter is difficult to argue scientifically but weirder things have happened. But rants are not rational arguments”
Interesting, which post of mine claims that warmer air cannot hold more water. If you have comprehensions issues it is not my problem.
Saturation point for warmer air is increasing with temperature. It doesn’t mean that there is more moisture in hotter air. You can have air at same temperature but with totally different levels of humidity, literally from 0% to 100%. Not understanding the difference between saturation point and actual water content in the air is a nice and classic move of fake scientists. Thank you for proving the point. All of you mention Clapeyron–Clausius equation but none of you actually understand what it means. Pathetic.
However, what you also misunderstand that actual moisture content in the air can be affected by many other parameters except of Temperate. And i do not need to a text book to tell me that. I work with this systems. I even told you how to check it at home by yourself. But you are a religious zealot, that is why you refuse to use your own brains.
So warmer air doesn’t have to hold more water he says waving his arms and ranting away. This is a seminal work held in considerably higher regard by me than Isakov’s rookie mistakes and absurd rants.
https://www.gfdl.noaa.gov/bibliography/related_files/bjs0601.pdf
Nope, warmer air does not have to have more water. It can but it does not have to. At same temperature you can have all kinds of humidity levels. But at same temperature and pressure you have a limit of what is the maximum content of moisture. And this maximum is defined by Clapeyron–Clausius equation, if the liquid water is available in the system.
https://www.engineeringtoolbox.com/water-vapor-air-d_854.html
I’m flabbergasted that such basics is unknown to you, particularly as you treat everyone with unashamed arrogance. Humble down and go hide in the cave.
As a hydrologist I have forgotten more about the water cycle than Isakov ever knew.
“As a hydrologist I have forgotten more about the water cycle than Isakov ever knew”
If you do not know the difference between saturation temperature and actual temperature of the air, or what is the meaning of RELATIVE HUMIDITY (what is it relative to?) then I’m afraid you have forgotten quite a bit.
And there is data and not just vaguely sciency sounding hand waving obfuscation.
https://www.gfdl.noaa.gov/bibliography/related_files/bjs0601.pdf
Assuming constant relative humidity we get an increase in moisture content of 7%/K warming. This is consistent with satellite measurements.
He comes along with simplistic misconceptions and abusive rants and expects to be applauded.
Do not run away? Hydrologist who doesn’t know that air does not necessary reach saturation condition at any particular temperature. Shame on you. There is nothing “vaguely sciency sounding”. THIS IS BASICS
“Assuming constant relative humidity we get an increase in moisture content of 7%/K warming.”
Why do you make this assumption? Do you understand what relative humidity means? Do you know how equilibrium vapour pressure of water is defined and why is it different from actual vapour pressure? Seems that you do not. You are hydrologist, supposedly, what is wrong with your basics.
in science there is hypothesis and validation with empirical data.
Agree. And I had a hypothesis that you have no clue about things you are talking about. Now we have data to confirm it. Not to know what is RELATIVE in relative humidity is brilliant.
But let’s see if you will have courage to admit that you screwed up.
In that the water content of the atmosphere is measurably increasing.
Isakov Dmitry
…warmer air does not have to have more water. It can but it does not have to. At same temperature you can have all kinds of humidity levels.
Dmitry, thank you for your brilliant insights!
Atmosphere does not “work” as a closed system in the tube.
https://www.cristos-vournas.com
Dmitry, thank you for your brilliant insights!
“Atmosphere does not “work” as a closed system in the tube.”
You are welsome. But it is sad that I have to spend so much effort on explaining such basics to them. 😞🤕
Robert I. Ellison commented:He may accept that warmer air holds more water vapor or not. The latter is difficult to argue scientifically but weirder things have happened. But rants are not rational arguments.,/i.
Hey, we agree on something! I’ll buy you a beer, Robert, should we ever meet, our other differences notwithstanding.
Isakov Dmitry commented:However, what you also misunderstand that actual moisture content in the air can be affected by many other parameters except of Temperate.
Bull — we all know that. Is that really the extent of your argument?
Yes, climate is complicated. But to a good approximation Earth’s water vapor can be treated as a constituent of air whose relative humidity is constant and whose concentration depends exponentially on temperature, in accordance with the Clausius-Claperyon equation, increasing 7% per degree C. It’s the famous water vapor feedback, it’s well known in climate science, it about doubles climate sensitivity, and there’s very little doubt about it. (Look in the description of any climate model to see a more complete treatment.) Nothing you’re written casts the slightest doubt on that, either. As others have said here you’re just ranting, and I’m done with you.
“air whose relative humidity is constant and whose concentration depends exponentially on temperature, in accordance with the Clausius-Claperyon equation, increasing 7% per degree C. It’s the famous water vapor feedback, it’s well known in climate science, it about doubles climate sensitivity, and there’s very little doubt about it”
🤣🤣🤣🤣🤣🤣🤣🤣🤣🤣🤣🤣🤣🤣Not constant even in first approximation”🤣🤣🤣🤣🤣🤣clausius claperyon is describing saturation condition. Please read physics not fake science. 🤕🤕🤕🤕 Well known to climate science – – – – – this is the point. It is not science what does not comply with scientific principles
I’m done with you as well.
Isakov Dmitry commented:
Not constant even in first approximation”
Says what?
That nice professor with a bowtie seems to get the effectiveness of CO2:
http://www.ilectureonline.com/lectures/subject/ASTRONOMY/2/355/6361
Yet that nice professor with a bowtie also writes for Dailywire:
https://www.dailywire.com/news/most-comprehensive-assault-global-warming-ever-mike-van-biezen
In it we can read most of the usual talking points.
I can list them on demand.
Another fun fact about heat transfer and particularly radiative heat transfer from gases. In thermosphere the temperature of the gas can reach 2000C during the day. Imagine if we could put in this number into the favorite Stefan-Boltzmann equation, like they do for the top of the troposphere. How cool will this be? So sad that S-B equation is strictly valid for surfaces, available only for liquids, solids and plasma. Gases do not posses such property, e.g. there is no surface.
The primary mistake that cult members of “climate science” do, it that they do not understand the difference between translational kinetic energy that is responsible for gas temperature, and vibrational kinetic energy that is responsible for IR absorption ( which will take place independent on gas temperature).
David, stop embarrassing yourself
You think you can’t use the Stefan-Boltzmann equation in the atmosphere? You should take a look at the atmospheric modeling in the climate models. They use Planck’s equation from which the Stefan-Boltzmann is derived.
It a complicated story why. Way above your level.
> The primary mistake that cult members of “climate science” do, it that they do not understand the difference between translational kinetic energy that is responsible for gas temperature, and vibrational kinetic energy that is responsible for IR absorption ( which will take place independent on gas temperature).
This you:
https://www.researchgate.net/profile/Dmitry-Isakov
What, you want to make it really personal and report me? Or get me fired for heresy? ;))))))))))))
Go try.
A “yes” or a “no” would do, Dmitry.
Not surprising. It doesn’t matter. CO2 is driving climate change. H2O is just a passenger.
Dunning-Kruger effect is too strong in you. It is hopeless to try and explain anything to you.
You do not know what is temperature.
You do not understand the difference between vibrational and translational kinetic energies. Although, I don’t think this was the reason of why you decided to compare absorption spectrum in the atmosphere to the absorptions spectrum of liquid water. I think it was just a sign that your “solid” understanding of science is more like a dough.
It is also entertaining that every new post you provide IR spectra from atmosphere at different temperature, clearly misunderstanding for which condition and at which altitude they are measured. Dough again.
And of course not knowing that most of the GHG effect in the atmosphere is driven by water vapour is absolutely classic. Even “consensus science” would not make such outrageous claim. They do many outrageous claims but they cannot deny the obvious. But apparently you can.
How to discuss anything with your type? Hopeless.
Hey genius,
1. It was you that claimed that earth’s radiant profile at TOA was from water. That why you were claiming that condensing water’s latent heat was being directly converted into IR. BTW, incase you didn’t notice, the earths’ radiant profile looks nothing like water’s radiant profile.
2. What does vibrational and translational energies have anything to do with what you posted? BTW you forgot rotational energies which are responsible for microwaves. Didn’t know that did you?
3. I just used what ever IR profile for the earth that came up when I searched for it. They all show the same thing. CO2 has a big impact on the earth’s radiant energy. That means your lubricant, water cycle, evaporation theory is BS.
4. How many people have to tell you the H2O is not the driver of climate change? CO2 is. Doesn’t that fit in with your BS climate theory? That’s what happens when you’re peddling junk science.
Also quick question?
You claim that “CO2 is driving climate change. H2O is just a passenger.”
Now, how does CO2 and water absorb IR? Do you have any knowledge on it. Key words are natural dipole moment for water and induced dipole moment for CO2. ;)))) Look it up. you will be surprised.
A non-sequitur. CO2 is increasing in the atmosphere. The only reason H2O is increasing in the atmosphere is because CO2 is driving the temperature higher. Stop increasing CO2 and the planet’s temperature will stabilize. H2O will have no impact on temperature change at that point. It only has an impact on temperature change because of the rising amount of CO2 in the atmosphere.
In case you didn’t know it, the key word is CHANGE.
The amount of ignorance is mind blowing. You are hopeless
Isakov Dmitry commented:
in response to JJBraccili:
Not surprising. It doesn’t matter. CO2 is driving climate change. H2O is just a passenger.
The amount of ignorance is mind blowing. You are hopeless
How much climate science have you studied, formally?
Isakov Dmitry commented:You claim that “CO2 is driving climate change. H2O is just a passenger.”
Now, how does CO2 and water absorb IR?
OF COURSE water vapor absorbs IR.
You don’t understand climate science at all.
That’s fundamentally your problem.
“Stop increasing CO2 and the planet’s temperature will stabilize.”
Mind-boggling. Again and again, we see that the AGW believers are the real climate change d-niers. Either that or lack of basic education.
Like many. You have no idea what you are talking about.
solar wind drives climate, not CO2
https://solarclimate.tumblr.com/post/662931197224271872/solar-wind-drives-climate-not-co2
Oh please!
There is not enough energy in solar wind, sun spots, or solar flares to drive the earth’s climate.
ahahaha
ahahaha
This is an excellent post – and an excellent paper. Sadly ignored by too many riding their idiosyncratic hobby horses into the ground. I may be biased – it is what I have been saying for a decade.
https://judithcurry.com/2011/02/09/decadal-variability-of-clouds/
The cause in cloud feedback to shifts in spatiotemporal patterns of sea surface temperature evolving over decades to millennia. As Chief Hydrologist – the more interesting bits are complex d
+ynamical fluid dynamics
keyboard problems… dynamical fluid dynamics and not baby radiative transfer physics expounded on interminably by puerile antagonists.
This time, a snowstorm in South Dakota and freezing temperatures in North Dakota will bring real winter to the Midwest. A strong frigid high is operating from central Canada.
No worries, the cult of “consensus climate science” has figure out the solution. They will burn at the stake heretics, like me, to make it warmer. ;))
JJBraccili, you wrote:
“The theory that the poster presented was for a planet without an atmosphere. His conclusion was that the rotation of the earth without an atmosphere raised the temperature of the planet by 33 K. From that he concludes that greenhouse gases have no impact on the earth’s temperature.
Those equations apply anywhere, but, as I said, the effect is probably negligible.”
Also you wrote:
“That 240 W/m2 has been corrected for albedo. Think of the hot side radiant energy of the moon as reflected energy. On the earth, it’s probably negligible.”
The issue we discuss is very important.
What I suggest is to compare Moon mean surface temperature with the Moon effective temperature. Then please comment what you think about the differences.
https://www.cristos-vournas.com
It depends how you define it. Do you define the effective temperature as the temperature calculated from the moon’s radiant energy, and the surface temperature as the moon’s average hot side temperature?
I pretty much done discussing the planetary spin theory. Any impact it has on the earth is negligible.
Radiative energy flux variations from 2000 – 2020
From a trusted source
JAXA-Arc1)
Average remaining extent gain (of the last 10 years) would produce a maximum in March 2021 of 14.75 million km2, 0.87 million km2 above the March 2017 record low maximum of 13.88 million km2, which would be 18th lowest in the satellite record
_______________________________________________________________
In 2020, October 2020 was heading to be the lowest monthly average in the satellite record.
This October’s monthly average is likely to be 1.5 million km2 above that of October 2020.
On this day sea ice extent is nearly 1.9 million km2 more than a year ago.
2021 is not an average year.
I wonder if this is what the Chief calls randomness?
Not likely to last given the slow refreeze the last 3 years but I will enjoy it while it lasts.
What it really shows is how poor a handle we have on the actual extent of natural variability.
Presumably it froze up while CERES was confirming a large radiative imbalance that should have been warming us.
Due to low subsurface temperatures in the central Pacific, I predict that the Niño 3.4 index could drop to -1.5 degrees C in November.
http://www.bom.gov.au/archive/oceanography/ocean_anals/IDYOC007/IDYOC007.202110.gif
https://www.tropicaltidbits.com/analysis/ocean/nino3.png
IP,
Do you see a repeating 2-month pattern in the recent nino index? Please see colored highlights I have added to your graph.
I have not seen any literature on this, have you? Geoff S
http://www.geoffstuff.com/cdas.jpg
Solar wind speeds are low, but there are speed spikes. Any increase in solar wind speed will now cause a decrease in surface temperature in the El Niño regions.
https://i.ibb.co/gJyFchQ/plot-image.png
https://i.ibb.co/bsbzg90/nino12.png
Disturbances to the circulation of the northern polar vortex are already evident in October.
https://www.cpc.ncep.noaa.gov/products/stratosphere/strat-trop/gif_files/time_pres_WAVE1_MEAN_OND_NH_2021.png
https://www.cpc.ncep.noaa.gov/products/stratosphere/strat-trop/gif_files/time_pres_HGT_ANOM_OND_NH_2021.png
Let me try again to address misconceptions that are deliberately pushed by “consensus science” apologists.
It is amazing how they manage to deceive public by obscuring obvious things. They actually provide the data but with an abracadabra trick they obscure the reality. They also employ bullying through authority of “solid” and “settled” science and thus, they manage to confuse so many. But let’s look at the actual data. Nothing new. Just data that they provide themselves.
In the link below you can see a full spectrum of radiative transfer in the atmosphere.
https://en.wikipedia.org/wiki/Greenhouse_gas#/media/File:Atmospheric_Transmission-en.svg
The disadvantage of the graph is that it is normalized for individual GHG and thus, it is not providing relative strength of each component. But this can be corrected using Beer Lambert Law, that states that optical absorption is linearly proportional to molar concentration. Now we have to be careful with molar concentration, which is measured in mol/L, as it is proportional to molar mass. Water has molar mass of 18g/mol, while CO2 is 44g/mol. So at same mass content CO2 will have 2.4 times higher effective absorption. Sounds good for CO2, however, GHG effects are most important in tropics where more energy per sqm is absorbed from the Sun. In tropics water content in lower troposphere, which captures radiant heat from the surface (Green house effect), reaches values of 40,000 ppmv. At the same time CO2 is distributed relatively uniformly at different latitudes with concentration of less than 400 ppmv or 100 time smaller than water vapour. So in combination we have 100/2.4= 42 times stronger effect from water vapour in tropics. This is known to “consensus science” but they conceal it by lumping water vapour and CO2, when they talk about GHG effect.
Now let’s go to the graph. We see several features both at input (direct absorption from the Sun in the atmosphere) and at the output (absorption of LWIR from Earth’s thermal radiation). If we look at input we will see that most of the absorption is due to water vapour. IPCC ranks the value of that absorption at 22% (78/341) of incoming Solar input. Impact of CO2 on the input can be ignored. Let’s ignore impact of clouds for now and thus, and changes in reflection. What do we get? Minute disturbance to water vapour content in atmosphere would have enormous increase in direct energy absorption from the Sun. While doubling or even tripling the content of CO2 will have no significant effect.
Now, let’s look at the output side. JJB loves to throw a lot of spectra without paying attention to what those spectra represent. For our analysis we need spectra from the ground and thus emissions at around 300K. Why is it important? Because the temperature of the surface determines the position of the spectrum’s maxima. This position we can determined using Wien’s law, which will give us 9.65 um, not 15 um that JJB wants. Now if we look at graph above, we will see that at this wavelength maximum transparency in the atmosphere is achieved, because the peak intensities drop smack in the middle of the water window. But what it also means is that the slopes of the emission curve fall into both absorption zones of the water vapour, e.g. 5-8 um and band above 11 um. So already at the left side (shorter wavelengths) we have a lot of absorption from water vapour and 0 absorption from CO2. Let’s look at the right side (longer wavelengths). We can notice that from 11 um to 20 um the absorptivity increases linearly for water vapour, so effectively we have a 0.5 multiplier on average for the normalized absorptivity. For simplicity let’s be generous and assign multiplier of 1 for CO2 absorptivity in the same region. But as we remember from Beer-Lambert law, water is 42 times more efficient in absorbing that CO2 based on molar concentration. So in overall we get that at the surface, where IPCC is measuring Global Warming, water vapour is a dominant GHG and controls radiant heat transfer.
Now, does it mean that CO2 can be ignored. No. Water specific humidity drops from tropics to poles. At higher latitudes the surface temperatures also drop and thus, the impact of left side of the emission spectrum stops overlapping with water absorption band. Additionally we have deserts, which also experience low water content. So this is where role of CO2 starts to be critical, allowing to partly compensate the drop in humidity. CO2 is a fine tuning mechanism for the climate.
The critical role of CO2 also appears above the top of the troposphere where water vapour concentration drops to nearly 0. There CO2 is a dominant GHG that limits the total loss of radiant energy to the universe. This is where all the spectra provided by JJB become relevant. Of course, air density at those altitudes and pressures (1 mbar) is very small, which leads to distances much larger than wavelength of IR radiation. Meaning that the probability of IR photons to interact with CO2 is limited.
So we see that the overall effect from CO2 can be substantial for GHG effect. Probably it can reach up to 20% in overall. Not something to be ignored but also not the dominant GHG. But we can imagine that even 10% changes in water vapour distribution will have a much larger effect on the climate than doubling of CO2.
At least, this is how I see it. Can I be wrong? Maybe. But they will have to try hard and without simple dismissive garbage and arrogant proclamations.
Also, analysis above is just considering GHG effect. It is ignoring a much more dominant mechanism of heat transfer in troposphere – latent heat. And this is where the variations in water content will dwarf any CO2 effect even further.
14CO2 is produced in the lower stratosphere and upper troposphere by neutrons from secondary galactic radiation. But does it cause a greenhouse effect? So does ozone, which as it falls from the stratosphere during the polar vortex lowers the tropopause, which means faster heat loss in space. CO2 as well as O3 are much heavier than air (O, N, O2, N2). Only water vapor heated from the surface is able to raise the height of the tropopause.
“Stratospheric intrusions are identified by very low tropopause heights, low surface heights of 2 potential vorticity units (PVU), very low relative and specific humidity concentrations, and high ozone concentrations.”
What this means:
“low surface elevations of 2 potential vorticity units (PVUs)”?
It means that air descending from the tropopause with an average temperature of -60 C, does not mix with air in the troposphere and displaces water vapor from it. This causes an immediate drop in tropopause height and surface temperature.
At the same time, the moist air is pushed into the interior of the winter polar vortex, where there is a rapid loss of thermal radiation to space.
https://www.cpc.ncep.noaa.gov/products/stratosphere/strat_int/
https://en.wikipedia.org/wiki/Carbon-14
Let me try again to address misconceptions that are deliberately pushed by Isakov Dmitry as he twists science into a pretzel in a quest to gain support for his idiotic theories.
I see that ID found an IR spectrograph of the earth more to his liking. I have to admit on his spectrograph, CO2 can’t have much more impact on earth’s climate. There is very little radiant energy for CO2’s 15mm absorption band to absorb. If the earth’s temperature rises, there will be even less. ID has now proved that the “consensus science apologists” are wrong, and we can continue to burn fossil fuels without consequence. Of course, he is dead wrong.
The IR spectrograph from my Quora post comes from NASA’s Goddard Institute of Space Sciences. It is a composite graph from satellite data. My graph is a plot of radiant energy vs. wavenumber. His graph plots radiant energy vs. wavelength. Wavelength = 1 / wavenumber. I have to congratulate ID for doing the conversion from wavenumber to wavelength correctly. With his track record, that’s quite an accomplishment. He is correct. On my IR spectrograph, the earth’s radiant peak is at 18mm; on his, it’s at 10mm. Mine is from data. Mine has to be correct. He doesn’t even question the discrepancy. The pompous a** assumes he is correct; therefore, I must be wrong. I could end this right here by saying mine is from actual data, but there is more to the story.
A few years ago, I was sent a paper written by an expert in atmospheric radiation, who actually was an expert. Yesterday, I said climate models use Planck’s equation to describe atmospheric radiation. That’s what he did. He produced a plot of the earth’s radiant energy vs. wavelength. Surprise! Surprise! It is identical to ID’s graph. The paper concluded that CO2 wasn’t a problem. He published his results in a pay-to-publish journal, and he was a consultant for the GWPF. The GWPF traffics in climate denial junk science. I was skeptical and decided to investigate.
I found out that Planck’s equation gives you different answers depending on whether you use wavenumber or wavelength as the integrating variable. Here is what Wikipedia has to say about Planck’s equation:
“Evidently, the location of the peak of the spectral distribution for Planck’s law depends on the choice of spectral variable.”
https://en.wikipedia.org/wiki/Planck%27s_law
Translation: You get a different radiant profile peak location depending on whether you use wavenumber or wavelength as the integrating variable. Once again, ID has proven himself clueless.
Since my IR radiant curve is from actual data, his plot is wrong. If you look at my IR plot, it has a black body radiation curve obtained by integrating Planck’s equation using wavenumber superimposed, and it pretty much matches the earth’s radiant energy profile.
Check out this website:
http://climatemodels.uchicago.edu/modtran/
It calculates the earth’s radiant profile using Planck’s equation. Switch the integrating variable from wavenumber to wavelength and see what happens to the 15mm CO2 absorption band.
I won’t go into his comments that rely on his graph because the graph is BS.
The rest of his screed is that H2O is the driver of climate change because it radiates the most IR. The problem is that for H2O to increase in the atmosphere to impact climate, the atmosphere’s temperature has to rise. For the water cycle to increase, the earth’s temperature has to increase. H2O can not accomplish that on its own because it condenses in the atmosphere, and the quantity in the atmosphere depends on atmospheric temperature. It needs another source of energy to increase – solar radiation or other greenhouse gases.
ID should not be lecturing anybody about anything because he has no idea what he is talking about.
This is a continuation of my post because I forgot to say something that will put another nail in the coffin of ID’s theories.
H2O is not as powerful a greenhouse as ID leads us to believe. As ID has told us, H2O absorbs IR over a broad range of wavelengths. Look at the IR spectrograph of the earth’s radiant energy. When the earth’s temperature rises, the earth puts out more IR, and the IR is at shorter wavelengths or longer wave numbers. The earth’s radiant profile gets higher and shifts to the right toward longer wavenumbers. Now, look at the peak. Consider only the effect of shifting the radiant energy curve to the right. Absorption bands to the left of the peak have less energy to absorb, and absorption bands to the right have more energy to absorb. Since H2O absorbs on both sides of the peak, the absorption bands on the left side have less energy to absorb, and the absorption bands on the right have more, assuming the amplitude effect cancels out. H2O could increase planetary temperature, lower planetary temperature, or have no impact. H2O is not as potent a greenhouse gas as ID thinks.
I’m not here to praise ID. I’m here to bury him under his own BS.
What, now you are desperately trying to hide that you do not know basic relationship between the temperature of a black body and the peak of IR emission generated by it? Don’t worry, I’m here to remind you. You should also be reminded of your lack of understanding of clausius-clapeyron equation. But ok. Let’s just talk about radiation.
Stop messing around and start putting numbers in. You, yourself provided link for calculating different contributions to the IR spectrum at 10 km looking downward (space where IPCC is emphasizing the effect of GHG). Just put in your numbers for Earths temperature, CO2 concertation and water content. Tell us your numbers and show what radiant forcing do you get. And we will check your analysis. Beauty of science is that it is falsifiable after it is quantified. Stop pushing here a theological debate.
“I found out that Planck’s equation gives you different answers depending on whether you use wavenumber or wavelength as the integrating variable. Here is what Wikipedia has to say about Planck’s equation”
OMG. Physics properties are now dependent on the units that JJB wants to use. That is “relativity” I never hear before. That really made my day. Thank you. If this is how you understand science than it explains a lot about you. You can also now solve the Global warming issue at least for USA. Just ask them to switch from Fahrenheit to Celsius ;)))))
You gave a very good link on the models. But you seem to be too laze to use it. Look, they even give you the IR heat flux values at the bottom. Go switch the graph between Wavenumber and Wavelength, does the value of the flux change? ;)))) Go try it. ;)))))
Now let see whose understanding this model supports. You claim that CO2 is dominant. I claim that water vapor is dominant factor. They really provide a convenient tool to check this. Let’s take their base model. We are talking about Troposphere and IPCC always draws radiant balancing below the clouds in their global mean radiation budget picture. So let’s fix altitude at 10km and choose Looking down option. Conditions will be Tropical atmosphere and no clouds. We should see than how much IR flux is captured by GHG according to that model. Let’s first fix CO2 at 300 ppm, as in 1960s before fast temperature increase. Now press Save This Run to Background.
Next step, change CO2 to 400 ppm or 1.33 times increase in concentration. Now the model will give you the difference between 2 IR fluxes. To me it shows 1.26W/m2. Notice also how little visual change appeared at the CO2 absorption Wavelengths or Wavenumbers.
Next step. Go back to 300 ppm. but now change water vapor scale to 1.33. OMG. The difference in heat flux now becomes 6.97 W/m2. 5.5 times higher impact from water vapor. And this is just based on equivalent increase in concentration. In reality water vapor content swings much more. And anthropogenically driven swings are very serious. Unfortunately for JJB, CO2 related affects (through added warming) on water vapour content are not even among the first 10.
I forgot from my previous post. You made a big deal that my graph had the radiant peak at 18mm and yours was at 10mm. That’s not due to a scale change. Then you went off talking about the H2O absorption bands locations on the radiant curve. I just scanned it because I knew your data was wrong. Would you like to revise that BS?
I don’t know if you received my other post where I discussed why H2O is not as powerful a greenhouse gas with regards to temperature change as you might think. You’re not going to like that either.
They should put your picture in the dictionary beside the word clueless.
“I forgot from my previous post. You made a big deal that my graph had the radiant peak at 18mm and yours was at 10mm. That’s not due to a scale change. Then you went off talking about the H2O absorption bands locations on the radiant curve. I just scanned it because I knew your data was wrong. Would you like to revise that BS”
Are you seriously going to insist that “Planck’s equation gives you different answers depending on whether you use wavenumber or wavelength as the integrating variable. ” ;)))))) SPECTRAL INTENSITY OF INFRARED RADIATION from EARTH’s SURFACE WILL BE INDEPENDENT OF WHAT UNITS YOU USE IN YOUR SPECTROSCOPE, WAVELENGTH OR WAVENUMBER. How “smart” are you to claim the opposite?
Where did I make a big deal about 18 um peak? My statement was ” This position we can determine using Wien’s law, which will give us 9.65 um, not 15 um that JJB wants.” How is it related to how you represent the graph, wavelengths or wavenumbers? Plus your spectrograph had both wavenumbers and wavelengths. https://earthzine.org/wp-content/uploads/2013/12/6.1.jpg
Why are you confused in your own graphs?
Your problem is that you do not specify where the graph is taken, in which direction and at which temperature? The radiant peak from the surface at 300K will be at 9.6 um. At 270K it is at 10.7um, at 215 K (same temperature as top of the troposphere) the peak is at 13.5 um. To get radiant peak at 18 um you will need temperature of 160K (-113C). What is happening inside your jelly of a brain?
The only time I used number 18 is 18g/mol for molar mass of water, are you referring to this? Do you have serious problem with reading and comprehensions?
You found a good interactive website that gives modeling of radiant heat transfer. Why don’t you use it? And use it as intended.
“Are you seriously going to insist that “Planck’s equation gives you different answers depending on whether you use wavenumber or wavelength as the integrating variable. ””
Absolutely!!!!!!!
“Where did I make a big deal about 18 um peak? My statement was ” This position we can determine using Wien’s law, which will give us 9.65 um, not 15 um that JJB wants.” How is it related to how you represent the graph, wavelengths or wavenumbers?”
The actual radiant peak at on my graph is at 18mm not 15mm. If it were at 15mm the CO2 absorption band would be at the peak — it’s not. You just can’t read.
You think there is no impact whether the peak is at 18mm or 10 mm?
LOL!!!!!!!!!!!!!
“Your problem is that you do not specify where the graph is taken, in which direction and at which temperature?”
My graph is a radiant profile of the earth. Go back and look at my graph. You’ll see a blackbody radiation curve in red. That curve was generated by integrating Planck’s equation using wavenumber. I think the black body curve that matched earth’s radiant energy profile was at 294 K. Your peak is at 10mm that corresponds to a blackbody curve at 300 K. See the problem now? Probably not, your ego won’t let you admit you make mistakes. Trust me, you make plenty of them.
For a physicist, you don’t know a damn thing. If you can’t handle blackbody radiation, it’s difficult to imagine how bad you must be at quantum mechanics.
“You found a good interactive website that gives modeling of radiant heat transfer. Why don’t you use it? And use it as intended.”
You mean use it like you? You have no idea how to use it. I told you it doesn’t do a heat balance. That makes it useless. There are other problems with that model. No sense discussing it with you because you won’t understand.
There is a company called Spectra or Spectral that has a model. You have to pay for it which probably means you aren’t interested. It’s probably much better than the free model, but I don’t know. I’m not a big fan of climate models.
““Are you seriously going to insist that “Planck’s equation gives you different answers depending on whether you use wavenumber or wavelength as the integrating variable. ””
Absolutely!!!!!!!”
This is hilarious. :))))))))))) Back to school my dear, back to school.
“The actual radiant peak at on my graph is at 18mm not 15mm. If it were at 15mm the CO2 absorption band would be at the peak — it’s not. You just can’t read…..I think the black body curve that matched earth’s radiant energy profile was at 294 K. Your peak is at 10mm that corresponds to a blackbody curve at 300 K. ”
It is really not hard to apply Wien’s law https://en.wikipedia.org/wiki/Wien's_displacement_law
Just take 2898 and divide by temperature in K. Try it. It is not that hard a exercise. 300K gives you the peak at 9.6um, 294K gives you a peak at 9.8 um. You can also take 2898 and divide it by wavelength and get a relevant temperature. So for 18 um peak the black body temperature is at 161 K. So where do you get your graphs from?
Stop being delusional and learn some science. At least basics.
Clueless,
Where did I get my graph?
https://energyredirect3.blogspot.com/
That’s the one I like to use because he has determined the amount of energy CO2 is preventing radiating into space. In reference 1 the author lists where he got the graph — NASA’s Goddard Institute of Space Studies. The original paper was by Gavin Schmidt. You can read his bio here.
https://en.wikipedia.org/wiki/Gavin_Schmidt
Authoritative enough for you? BTW where did you get that BS graph of yours?
The red curve superimposed on my graph is a blackbody curve generated from Planck’s equation using wavenumber as the integrating variable. The temperature of that curve is 294 K — not 161 K.
Your posts are devolving into psychobabble. It happens when your theories are BS.
Some advice:
The first rule of getting out of a hole is to quit digging.
But religion.
But consensus.
But science (“settled”).
But data.
But Anything But CO2.
Nothing new indeed.
The highest CO2 concentrations are measured at the surface, of course, and interestingly, very high CO2 concentrations are observed during the winter in Antarctica.
A decrease in vegetation immediately increases CO2 levels near the surface.
https://earth.nullschool.net/#2021/08/02/0000Z/chem/surface/level/overlay=co2sc/patterson
This article gives a useful approximation of what goes on with evaporation of water:
https://www.wired.com/2013/11/how-do-things-cool-with-evaporation/
In the Arctic, as the sea ice melts, the water warms a bit from SW radiation. At the same time, evaporation can ramp up as there’s no sea ice to make evaporation difficult. The ideal evaporation is warm water, cold air temps and dry air. The cooling aspect of evaporation gets things closer to making more sea ice. Once again, as we are talking about water, we expect negative feedbacks. The more Exxon-Mobile warms the Arctic, the more evaporation cools it. Got that? Does this sound like a death spiral? No. That’s some cult thing where they dress up like goats and dance around. How did I get on this subject? I am watching low lake levels behind my office and trying to figure out how low they will get before the lake freezes.
Isakov Dmitry
“So sad that S-B equation is strictly valid for surfaces, available only for liquids, solids and plasma. Gases do not posses such property, e.g. there is no surface.”
“…S-B equation is strictly valid for surfaces, available only for liquids, solids and plasma…
Thank you!
https://www.cristos-vournas.com
‘Finally, this proof started out only considering a small flat surface. However, any differentiable surface can be approximated by a collection of small flat surfaces. So long as the geometry of the surface does not cause the blackbody to reabsorb its own radiation, the total energy radiated is just the sum of the energies radiated by each surface; and the total surface area is just the sum of the areas of each surface—so this law holds for all convex blackbodies, too, so long as the surface has the same temperature throughout. The law extends to radiation from non-convex bodies by using the fact that the convex hull of a black body radiates as though it were itself a black body.’ https://en.wikipedia.org/wiki/Stefan%E2%80%93Boltzmann_law
What we calculate with SB is an equivalent black body temperature. What happens with the Earth is that the average emission height is in the atmosphere and not at the surface. SB shows that the equivalent blackbody temperature is 33 degrees C lower than the average surface temperature.
Christos Vournas commented:
Isakov Dmitry
“So sad that S-B equation is strictly valid for surfaces
No, it’s valid for any blackbody.
But yes, all bodies have surfaces.
The distinctive property of gas is that it does not have its own surface interaction between molecules of gas is effectively zero. Gas will occupy all available volume.
Isakov Dmitry commented:
The distinctive property of gas is that it does not have its own surface interaction between molecules of gas is effectively zero. Gas will occupy all available volume.
Yeah yeah blah blah. Irrelevant.
Water vapor is a condensable gas. You can’t add more of it to a gas mixture at constant T.
The animation below shows the current circulation in the eastern Pacific. You can see that it is not typical of the La Niña period. This is because the stratospheric polar vortex has already taken control of the weather in the northern hemisphere. This will bring heavy rainfall to California and snow in the mountains, which can be counted in meters.
http://tropic.ssec.wisc.edu/real-time/mtpw2/product.php?color_type=tpw_nrl_colors&prod=epac×pan=24hrs&anim=html5
https://coralreefwatch.noaa.gov/data_current/5km/v3.1_op/daily/png/ct5km_ssta_v3.1_pacific_current.png
“snow in the mountains, which can be counted in meters.“
That can’t happen. They told us decades ago ski areas will be a thing of the past. The number of failed predictions is getting bigger than the Megamillions Jackpot.
I can’t see this as anything other than random word salad purporting to account for turbulent fluid dynamics.
https://earth.nullschool.net/#current/wind/surface/level/overlay=total_precipitable_water/orthographic=-116.06,40.41,464/loc=-128.920,41.034
Clausius-Clapeyron is the relevant equation explaining why water vapor is a feedback to global warming.
JJBraccili,
Φ -Factor is an analogue of the well known Drag Coefficient Cd=0,47 for smooth sphere in the parallel fluid flow.
And it is about the by sphere’s surface the portion of incident energy acceptance!
From Wikipedia, the free encyclopedia
“In fluid dynamics, the drag coefficient (commonly denoted as: Cd, Cx or Cw) is a dimensionless quantity that is used to quantify the drag or resistance of an object in a fluid environment, such as air or water. It is used in the drag equation in which a lower drag coefficient indicates the object will have less aerodynamic or hydrodynamic drag. The drag coefficient is always associated with a particular surface area.[3]
The drag coefficient of any object comprises the effects of the two basic contributors to fluid dynamic drag: skin friction and form drag.”
https://en.wikipedia.org/wiki/File:14ilf1l.svg
https://en.wikipedia.org/wiki/Drag_coefficient
Φ factor explanation
The Φ – solar irradiation accepting factor – how it “works”. It is not a planet specular reflection coefficient itself.
There is a need to focus on the Φ factor explanation.
Φ factor emerges from the realization that a sphere reflects differently than a flat surface perpendicular to the Solar rays.
Φ – is the dimensionless Solar Irradiation accepting factor
“Φ” is an important factor in the Planet’s Surface Mean Temperature Equation:
Tmean.planet = [ Φ (1-a) S (β*N*cp)¹∕ ⁴ /4σ ]¹∕ ⁴ (K)
It is very important the understanding what is really going on with by planets the solar irradiation reflection.
There is the specular reflection and there is the diffuse reflection.
The planet’s surface Albedo “a” accounts for the planet’s surface diffuse reflection.
Albedo is defined as the ratio of the scattered SW to the incident SW radiation, and it is very much precisely measured (the planet Bond Albedo).
So till now we didn’t take in account the planet’s surface specular reflection.
A smooth sphere, as some planets are, have the invisible from the space and so far not detected and not measured the specular reflection.
The sphere’s specular reflection cannot be seen from the distance, but it can be seen by an observer situated on the sphere’s surface. For example, when we admire the late afternoon sunsets on the sea we are blinded from the brightness of the sea surface glare. It is the surface specular reflection what we see then.
https://www.cristos-vournas.com
It’s a hypothesis I suppose. Science requires empirical verification.
The roughness of a surface can be varied at this site changing the amounts of specular and diffuse reflection. But can this possibly mean that a perfectly smooth planet is invisible? And that all Christos’s planets have the same roughness?
https://www.olympus-lifescience.com/en/microscope-resource/primer/java/reflection/specular/
JJBraccili,
We have Φ for different planets’ (spheres) surfaces varying
0,47 ≤ Φ ≤ 1
And we have surface average Albedo “a” for different planets’ varying
0 ≤ a ≤ 1
Notice:
Φ is never less than 0,47 for planets (spherical shape). Also, the coefficient Φ is “bounded” in a product with (1 – a) term, forming the Φ(1 – a) product cooperating term.
So Φ and Albedo are always bounded together. The Φ(1 – a) term is a coupled physical term.
The Φ(1 – a) term “translates” the “absorption” of a disk into the “absorption” of a smooth hemisphere with the same radius.
When covering a disk with a hemisphere of the same radius the hemisphere’s surface area is 2π r². The incident Solar energy on the hemisphere’s area is the same as on the disk:
Jdirect = π r² S
But the “absorbed” Solar energy by the hemisphere’s area of 2π r² is:
Jabs = Φ*( 1 – a) π r² S
It happens because a smooth hemisphere of the same radius “r” “absorbs” only the Φ*(1 – a)S portion of the directly incident on the disk of the same radius Solar irradiation.
In spite of hemisphere having twice the area of the disk, it “absorbs” only the Φ*(1 – a)S portion of the directly incident on the disk Solar irradiation.
Jabs = Φ (1 – a ) S π r² , where Φ = 0,47 for smooth without atmosphere planets.
and Φ = 1 for gaseous planets, as Jupiter, Saturn, Neptune, Uranus, Venus, Titan.
Gaseous planets do not have a surface to reflect radiation. The solar irradiation is captured in the thousands of kilometers gaseous abyss. The gaseous planets have only the albedo “a”.
And Φ = 1 for heavy cratered planets, as Calisto and Rhea ( not smooth surface planets, without atmosphere ).
The heavy cratered planets have the ability to capture the incoming light in their multiple craters and canyons. The heavy cratered planets have only the albedo “a”.
That is why the albedo “a” and the factor “Φ” we consider as different values.
Both of them, the albedo “a” and the factor “Φ” cooperate in the
Energy in = Φ(1 – a)
left side of the Planet Radiative Energy Budget.
Conclusively, the Φ -Factor is not the planet specular reflection portion itself.
The Φ -Factor is the Solar Irradiation Accepting Factor (in other words, Φ is the planet surface shape and roughness coefficient).
https://www.cristos-vournas.com
> Φ factor emerges from the realization that a sphere reflects differently than a flat surface perpendicular to the Solar rays.
We’ve been over this a few weeks ago:
https://andthentheresphysics.wordpress.com/2021/04/25/mind-your-units/
ATTP is right. However, the atmosphere is thick. Look at Mercury in a telescope to see this. 50-65 X will do. Where is it not thick for astronomy? Within 60 degrees of overhead.
Incoming SW, thicker. Outgoing LW, not thicker.
In a MN Winter, thicker to incoming SW.
In Summer, not thicker to income SW.
So the question is, what is the adjustment for this?
Not important?
What if our atmosphere had 1/10 of its sea level pressure at 2000 miles up? Would it be important then?
In regards to the Arctic sea ice death spiral. To incoming SW, my short answer is always thick. So it’s more than angle. It’s thickness as well towards the poles.
Mornin’ Ragnaar (UTC),
You mentioned the magic phrase “Arctic death spiral”, so the genie is out of its bottle!
Since “ATTP is right”, perhaps “Snow White” is as well?
Since Willis hasn’t got around to it yet, perhaps you can answer this question on his behalf?
https://judithcurry.com/2021/10/10/radiative-energy-flux-variations-from-2000-2020/#comment-961076
“Here is the 2014 paper by Pistone et al. about ‘Arctic albedo’”
https://www.pnas.org/content/111/9/3322
Jim Hunt:
No clue about Snow White. What’s their gender these days? Albedo. Heard of that. Here: https://climate.nasa.gov/vital-signs/arctic-sea-ice/
The minumum of sea ice seems flat, so the Arctic death spiral needs animation to keep walking. We can count on NASA and Greenpeace for that I am sure.
Albedo matters. I was trying to say the 1/4 surface emission of the black body formula may need improvement based up the thickness of the atmosphere interferring with incoming SW up North. Does make nice sunsets though right? They got CMIP6s. Most of them paid for. They ought to be able to handle the atmosphere’s thinkness.
As long as we are on the subject. Near horizontal incoming SW has a dispersion pattern when it hits something reflective. Half up and half down. Near vertical incoming SW I am not so sure about. We can assume it hits a round object with an albedo of 1. I argue that albedo is a function of the atmosphere’s thickness. And that SW incoming within 10 degrees of horizontal are materially impacted. Earlier I referred to viewing Mercury through a telescope. That might have been 5 degrees above horizontal. Shimmered like a mofo. But that was atmospheric turbulence I think.
‘Energy in = Φ(1 – a)’
Yeah right.
Correction:
Energy in = Φ (1 – a ) S π r² (W) ;-)))
Thank you for noticing.
https://www.cristos-vournas.com
So measured energy in is some 170 W/m2 – because of this wildly hypothetical Φ factor. – and measured energy out is some 341 W/m2?
“But can this possibly mean that a perfectly smooth planet is invisible? And that all Christos’s planets have the same roughness?”
A perfectly smooth planet still has Albedo. The smoothest object in solar system is Europa, Jupiter’s moon.
Europa has Albedo a=0,67
Planets are either very smooth Φ=0,47 or very rough Φ=1
It is the result of their some billions years of history.
The surface features were developed either one way or the other.
https://www.cristos-vournas.com
On a perfectly smooth planet reflection is all specular which you declared to be invisible. And now Φ is conveniently different for different planets. It begs the question I have always put to you of how Φ is measurable.
= A smooth sphere, as some planets are, have the invisible from the space and so far not detected and not measured the specular reflection.
The sphere’s specular reflection cannot be seen from the distance, but it can be seen by an observer situated on the sphere’s surface. For example, when we admire the late afternoon sunsets on the sea we are blinded from the brightness of the sea surface glare. It is the surface specular reflection what we see then.
Robert
“And now Φ is conveniently different for different planets. It begs the question I have always put to you of how Φ is measurable.”
== Robert, if Φ was measurable NASA would have measured it.
When discovering there is Φ=0,47 for smooth surface planets it was my duty to disclose it.
“And now Φ is conveniently different for different planets.”
== It is not like this… there are only two different Φ.
Φ=0,47 for smooth surface planets and moons
(Mercury, Moon, Earth, Mars, Europa, Ganymede)
and
Φ=1 for all other planets and moons.
“It begs the question I have always put to you of how Φ is measurable.”
== Φ is not measurable, Φ is estimated.
Usually for planets with low Albedo Φ=0,47 because they happens to be smooth surface planets.
Also we have the NASA descriptions of planetary surface features.
https://www.cristos-vournas.com
As I told you, the work I did on your “theory” convinced me that planet rotation had negligible impact on planetary temperature now I can prove it has absolutely no impact.
When I use the symbol T. Take it to mean. T to the 4th power. Let the sun’s temp be Ts. let the hot side surface temperature of the planet be Th. Let the cold side surface temperature of the planet is Tc. k is the Stefan-Boltzmann x emissivity x area. Assume the sun irradiates half the planet so the hot side, cold side areas are the same. Start with a non-spinning planet with no atmosphere and at steady state.
Heat absorbed by the planet = k(Ts – Th)
Heat emitted by the planet = kTc ( no energy is being radiated to the cold side of the planet).
At steady state heat absorbed by the planet is the same as the heat emitted by the planet. k(Ts – Th) = kTc or Tc = Ts – Th
Rotate the planet 180 degrees so the cold side faces the sun.
Heat absorbed on the hot side is k(Ts – Tc)
Heat emitted by the planet kTh.
Since Tc = Ts – Th, make the substitution for Tc
heat absorbed by the planet = kTh
heat emitted by the planet = kTn
Heat absorbed = heat emitted. The planet will remain at steady state. Rotation doesn’t impact planetary temperature no matter how fast you rotate it. When the planet returns to steady the hot side and cold side temperatures will be identical to the value they were before rotation. Take the ultimate case where you spin the planet so fast that surface temperature is uniform. That what we assume when we calculate an average temperature for a planet by making spherical corrections. There will be no change in planetary temperature as a result.
The only effect of rotating the planet will be to speed the return to steady state. Double the amount of solar radiation. A lower surface temperature will speed up the absorption of heat. There will no change in the final steady state.
Your theory has been disproven. No more need to discuss it any further. I suggest you consider removing it from your website. All you are doing now is spreading misinformation. I hope this was an honest mistake — not an attempt to deceive.
JJBraccili, thank you for your interest in my work.
There is also the Planet Surface Rotational Warming Phenomenon. It states:
“Planets’ mean surface temperatures relate (everything else equals) as their (N*cp) products’ sixteenth root.”
https://www.cristos-vournas.com
Robert, if Φ was measurable NASA would have measured it.
When discovering there is Φ=0,47 for smooth surface planets it was my duty to disclose it.
https://www.cristos-vournas.com
Christos Vournas commented:
Robert, if Φ was measurable NASA would have measured it.
If it’s not measurable then it’s meaningless.
Your parameter Φ is a fudge factor. Ad hoc, put in only to give you the answer you want. Hence it isn’t science. You can’t calculate it from theory. You can’t measure it. It’s fairy dust.
We’ve been over all this before. You’re doing pseudoscience.
David Appell
“Your parameter Φ is a fudge factor. Ad hoc, put in only to give you the answer you want. Hence it isn’t science. You can’t calculate it from theory. You can’t measure it. It’s fairy dust.
We’ve been over all this before. You’re doing pseudoscience.”
Thank you for asking.
Φ -Factor is an analogue of the well known Drag Coefficient Cd=0,47 for smooth sphere in the parallel fluid flow.
And it is about the by sphere’s surface the portion of incident energy acceptance!
From Wikipedia, the free encyclopedia
“In fluid dynamics, the drag coefficient (commonly denoted as: Cd, Cx or Cw) is a dimensionless quantity that is used to quantify the drag or resistance of an object in a fluid environment, such as air or water. It is used in the drag equation in which a lower drag coefficient indicates the object will have less aerodynamic or hydrodynamic drag. The drag coefficient is always associated with a particular surface area.[3]
The drag coefficient of any object comprises the effects of the two basic contributors to fluid dynamic drag: skin friction and form drag.”
https://en.wikipedia.org/wiki/File:14ilf1l.svg
https://en.wikipedia.org/wiki/Drag_coefficient
David,
Drag Coefficient Cd=0,47 for smooth sphere in the parallel fluid flow is a well known and well measured parameter.
https://www.cristos-vournas.com
“Φ -Factor is an analogue of the well known Drag Coefficient Cd=0,47 for smooth sphere in the parallel fluid flow.”
This is definition #3 of this mysterious factor. It sounds good. What exactly is a planet without an atmosphere dragging against? The vacuum of space? If a planet was spinning and dragging against something it would soon stop spinning.
Even if a planet has an atmosphere, the atmosphere rotates with the planet because of gravity. Nothing to drag against.
This is how you explain this factor on your website:
https://www.cristos-vournas.com/448587170
Looks like a spherical correction to me. Of course, that factor is actually 0.25 and doesn’t require all the arm waving to figure out. You probably didn’t realize it, but you accounted it in your equation when you divided by 4.
Three strikes and your out. In this case you win a lifetime membership in the Tin Foil Hat Club.
JJBraccili
“… Φ=0,47 …. ….. Looks like a spherical correction to me. Of course, that factor is actually 0.25 and doesn’t require all the arm waving to figure out. You probably didn’t realize it, but you accounted it in your equation when you divided by 4.”
Here is the Planet Mean Surface Temperature Equation:
Tmean = [ Φ (1-a) S (β*N*cp)¹∕ ⁴ /4σ ]¹∕ ⁴
JJBraccili, of course Φ -factor refers to spherical surface EM irradiance acceptance ability.
the ROTATING PLANET SPHERICAL SURFACE SOLAR IRRADIATION ABSORBING-EMITTING UNIVERSAL LAW
Jemit = 4πr²σΤmean⁴ /(β*N*cp)¹∕ ⁴ (W)
Planet Energy Budget:
Jabs = Jemit
πr²Φ*S*(1-a) = 4πr²σTmean⁴ /(β*N*cp)¹∕ ⁴ (W)
Solving for Tmean we obtain the PLANET MEAN SURFACE TEMPERATURE EQUATION:
Tmean.planet = [ Φ (1-a) S (β*N*cp)¹∕ ⁴ /4σ ]¹∕ ⁴ (K)
JJBraccili, see, I do not average solar flux over the planet’s surface. There is NO planet blackbody uniform temperature equation any more.
https://www.cristos-vournas.com
JJBraccili, you visited “Φ and Fresnel” page:
https://www.cristos-vournas.com/448587170
Also please visit:
Φ factor explanation
https://www.cristos-vournas.com/444383819
Φ observed numbers
https://www.cristos-vournas.com/445559911
SOLAR ENERGY BUDGET
https://www.cristos-vournas.com/448704125
I hate to be the bearer of bad news, but you “theory” is wrong and it doesn’t matter what some factor is or is not.
Look at my disproof. All I did was start with a non-spinning planet at steady state. It has a hot side and a cold side. I rotated the planet 180 degrees. What was the cold side is now absorbing energy from the sun. What was the hot side of the planet is now radiating energy into space. For the average surface temperature to change from the previous average surface temperature, there must be a difference between what is absorbed and emitted from the planet. There is not. Spin has NO impact on planetary temperature.
I wish your theory was true. It would certainly be a relief to know that CO2 is not the cause of a rising planetary temperature. Unfortunately, it’s not and our CO2 problem is still a serious problem.
JJBraccili
“I wish your theory was true. It would certainly be a relief to know that CO2 is not the cause of a rising planetary temperature. Unfortunately, it’s not and our CO2 problem is still a serious problem.”
Thank you. The theory is true.
The faster a planet rotates (n2>n1) the higher is the planet’s average surface (mean) temperature T↑mean.
So we shall have: when n2>n1
Tmean.dark↑↑→ T↑mean ← T↓mean.solar
Please visit page “Tmin↑↑→T↑mean← T↓max”
https://www.cristos-vournas.com/444032320
I’m not going to go through your calculation to see exactly where you went wrong. I’ll just explain the correct way to look at the problem
Energy in to the planet k(Ts – Th)
where Ts= Temp Sun ** 4, Th = Temp Hot Side ** 4, k = all the other constants.
Energy out = kTc
where Tc = Temp Cold Side **4
at steady state energy in = energy out. k(Ts – Th) = kTc
Tc = Ts – Th
That is an important relationship. It shows the relationship between Tc and Th since Ts is constant.
Rotate the planet 180 degrees. The cold side is now absorbing energy from the sun and vice versa. Each half of the planet is not in steady state but that doesn’t mean the entire planet isn’t in steady state. For the average temperature of the planet to change there must be a difference between the TOTAL energy in and energy out
Energy in = k(Ts – Tc)
We have shown the Tc = Ts – Th. Make the substitution.
Energy in = kTh
Energy out = kTh
Energy in = Energy out, There is no accumulation of energy on the planet and the average temperature doesn’t change. The result is that each half of the planet is not at steady state but the planet is. When the planet comes to equilibrium it will return to the same temperatures it was before.
Rotating the planet is not going to change that. All rotating planet does is distribute the solar radiation more evenly, and reduce the difference between Th and Tc. The best that rotating the planet can do is have the entire surface of the planet at the same average temperature. This is exactly what we assume when we calculate the temperature of a planet from the Stefan-Boltzman equation. There is no difference between a stationary or rotating planet.
There are only two ways a rotating planet can change the planet’s temperature. Either it creates energy — that’s impossible — or it acts as resistance to heat flow. I have shown it does neither.
Check your calculations in light of what I said.
JJBraccili,
Thank you. The theory is true.
The faster a planet rotates (n2>n1) the higher is the planet’s average surface (mean) temperature T↑mean.
Please visit page “Tmin↑↑→T↑mean← T↓max”
https://www.cristos-vournas.com/444032320
You can put all the ‘spin” on it you want. The theory is not true.
Scientists have been looking at this for over 40 years. Even if they had not identified planet rotation as the cause of a 33 K rise in the earth’s temperature, you can rest assured they would have figured out greenhouse gases weren’t causing it.
Your best bet is try and make some money off of your theory. You’ve done an impressive amount of work. You just need to market it in the climate denial community. There are plenty of idiots over there who would love this stuff and would pay to hear more about it.
If I were you, I wouldn’t be making plans for a trip to Stockholm to pick up a Nobel Prize.
Thank you John.
It is getting late in Athens, Greece – 11 pm.
Shall we continue tomorrow?
Christos
JJBraccili,
1. Planet cannot reach uniform surface temperature because it is solar irradiated from one side only.
2. The planet blackbody Te equation
Te = [ (1-a) S /4σ ]¹∕ ⁴
is mistaken because it is based on concept that the not reflected portion of incident solar flux’s SW EM energy warms planetary surface (gets absorbed in form of heat) and then the heat is distributed evenly over the entire planetary surface.
In fact only a small fraction is transformed to heat.
The Te equation is a mathematical abstraction.
https://www.cristos-vournas.com
1. If you spin the planet fast enough, the surface temperature will be uniform because solar radiation distributes evenly. There is nothing that would cause a hot side – cold side scenario.
2. They assume that the solar radiation distributes over the entire earth’s surface is because the earth radiates over its’s total surface. That puts everything on the same basis; otherwise, if you used the actual numbers at steady-state, energy in = 1000 W/m2 energy out = 240 W/m2.
I looked at your calculation, and I know where you went wrong. You took a planet at steady-state with Th = 200 K and Tc = 100 K. Then you dropped Th to 199 K and calculated Tc to be 107 K. I checked your result with my equations, and I got the same result. Then you reason that because the temperature of the cold side has gone up 7 K and the temperature of the hot side has gone down 1 K. The temperature of the planet goes up. A reasonable assumption, but it’s wrong.
Your assumption relies on the non-linearity of the Stefan-Boltzmann equation. Heat transferred is proportional to T4 — not T. If the equation were linear and heat transferred were proportional to T. Then when you dropped Th by 1 K Tc would rise by 1 K, and, based on your assumption, the planet’s temperature would be the same. What if I told you non-linearity makes no difference in this problem?
How do we get a planet’s temperature to rise? One way is to increase solar radiation. The instant you do that, you create an energy imbalance because more energy radiates to the planet than it radiates to space. The imbalance causes the planet to accumulate energy that raises its temperature. Eventually, the temperature rises enough to radiate sufficient energy to balance the incoming solar radiation. The temperature of the planet stops rising, and the planet is at steady-state.
The other way is to restrict the energy the planet radiates to space. Some outgoing radiation is captured and returned to the planet with the greenhouse effect. That’s identical to increasing solar radiation. The result is the same, the temperature rises, but the amount of solar radiation never changes.
These methods have one thing in common. They start at steady-state, and they end at steady-state. In between, there is an energy imbalance that causes the planet’s energy to increase and its temperature. If there is no imbalance, there is no change in the energy of the planet and no change in its temperature. Planetary rotation cannot create energy, and if it is to change the planetary temperature, it must interfere with the outgoing planet’s radiation.
In your calculation, you start at steady-state and end at steady-state. Your analysis says nothing about whether or not there was an energy imbalance between those two states. It says nothing about whether the planet has accumulated energy in the transition from one steady-state to another. In other words, it says nothing about whether the planet’s temperature has risen.
What I decided to do is to take a different tact. I decided to create an energy imbalance, and I rotated the planet 180 degrees and put the cold side facing the sun and vice versa. Then it was just a matter to determine if an energy imbalance was created. There was not. That means no energy accumulation, and no rise in the planet’s temperature.
I saved the best for last. Take a look at your calculation. Look at what you do to calculate the cold side temperature. You take the energy radiating into space by the hot side at a temperature, and then you subtract 1 K from the temperature. You determine the energy radiating into space at that temperature. You subtract the two and claim that the planet must emit that energy into space. You calculate a cold side temperature. Then you conclude that the temperature of the earth must rise.
Here’s the thing. You assumed that the additional energy absorbed from the hot side is radiated into space by the cold side. That means the energy balance has not changed, and the energy of the planet has not changed. Which means the temperature of the planet has not changed. All you proved is that the non-linearity of the Stefan-Boltzmann has caused a non-linear response in temperature. By your calculation, you have proved your main thesis wrong.
As I said, your calculation doesn’t prove or disprove your planet rotation theory. Mine does.
The animation below shows how the polar vortex blockade over the Bering Sea is currently affecting North American weather. This is a jet stream at 700 hPa (approximately 3500 m above sea level).
https://earth.nullschool.net/#2021/10/22/0900Z/wind/isobaric/700hPa/overlay=temp/orthographic=-108.46,60.20,591/loc=-130.591,39.419
Heavy precipitation is expected on October 22 even in the deserts of Southern California. A powerful snowstorm in the mountains may surprise travelers.
Effective temperature is a mathematical abstraction. Every planet has a calculated effective temperature no matter how fast planet rotates.
Why should we consider the planet effective temperature to be the highest mean surface temperature a real planet mean surface temperature can theoretically achieve?
The Stefan-Boltzmann emission law states:
Jemit = σ*T⁴ W/m² where T is a uniform surface emission
temperature.
The amount of energy emitted from a surface with A m² area is:
energy out = A (m²) * σ*T⁴ W/m² = A * σ*T⁴ W
or
energy out = A * Jemit
The Stefan-Boltzmann blackbody surface already has the uniform temperature T, because it is uniformly warmed to that T temperature.
Planet surface cannot be considered as a blackbody uniformly warmed surface. The incident solar flux cannot be averaged over the planet surface. Flux is not heat…
The fact that planet receives a solar flux, does not mean its energy first warms planet surface and only then the warmed surface emits the same incident amount of solar energy as IR EM emission.
EM radiation is not a heat transfer process, like the heat conduction is…
EM radiation is a flux-surface-matter interaction process.
https://www.cristos-vournas.com
This is a relatively simple design. The ocean floor at 400 feet below present is relatively flat. At the end of the last Ice Age the ice on the northern hemisphere was at the point where the heat retained by the earth was greater than that radiated to the black sky. The edge of the northern continents was dropping off more rapidly. The oceans began to drop rapidly until, at 400 feet plus below present, the earth reached the point where we began to retain more heat than radiated to the black sky.
The earth began building the Ice Shelf. I call them ICE BLOCKS sitting on solid earth. The oceans rose and the ICE BLOCKS began to break off. About 12,000 years later the heat necessary to melt the ice broken off plus the heat lost to the black sky was equal. This took about 14,000 years. For the last 8,000 years we have been in idle.
This Ice age will last 130 to 140 thousand years. That means the next will begin in about 103 thousand years plus this Ice Age will end.
The principle sounds correct but its implementation is wrong.
” The oceans began to drop rapidly until, at 400 feet plus below present, the earth reached the point where we began to retain more heat than radiated to the black sky.” To retain more heat the ice dropped rapidly; the oceans increased.
“For the last 8,000 years we have been in idle.” Interglacial. Cooling may begin — about now. See https://www.linkedin.com/pulse/predictability-past-warm-periods-renee-hannon/
An atmospheric river is coming over the West Coast. The large temperature difference promises a violent impacts of fronts from the Pacific Ocean.
https://i.ibb.co/rvkPYZz/pobrane.png
“To learn more about a possible connection between the two currents, the researchers collected and studied a massive amount of weather data and created models to show how the two systems might impact one another.”
https://scx2.b-cdn.net/gfx/news/2021/gulf-stream-and-kurosh.jpg
https://phys.org/news/2021-10-gulf-stream-kuroshio-current-synchronized.html
At the boundary with space climate is very simple. The change in planetary work and heat is equal to energy in less energy out. It can be expressed as a 1st differential global energy equation.
d(W&H)/dt= Ein – Eout
The large negative Planck feedback drives the planet towards energy equilibrium but the balance perpetually changes.
There are minor changes in solar insolation – over orbital cycles there are changes in the distribution of insolation. That at times of low NH summer insolation results in runaway ice sheet feedbacks. That with Arctic freshening and THC slowdown may kick in any time now. In the shorter term energy is modulated by changes in atmospheric composition and cloud. The ERBE and ISCCP data on cloud in the satellite era was dismissed as questionable – but CERES is definitive.
‘In summary, although there is independent evidence for decadal changes in TOA radiative fluxes over the last two decades, the evidence is equivocal. Changes in the planetary and tropical TOA radiative fluxes are consistent with independent global ocean heat-storage data, and are expected to be dominated by changes in cloud radiative forcing. To the extent that they are real, they may simply reflect natural low-frequency variability of the climate system.’ IPCC, TAR, 3.4.4.1
https://www.youtube.com/watch?v=eGshzvKAM3w&t=38s
Climate over the past 100 years are most clearly correlated with patterns of sea surface temperature in the eastern Pacific and cloud effect feedback. This caused most of the early 20th century warming, the mid century cooling and half of the warming of the past 40 years. But CO2 concentrations in the atmosphere are rising and may at high enough levels be the Achille’s heel of climate with abrupt 10 C warming. Although my guess in context is tipping over to rapid 10 C cooling way before then.
Fossil fuels have provided a cornucopia of benefits that much of the world still seeks to secure – and short term risks of climate change seem relatively minor. But demand for energy is growing exponentially – mostly in the developing world – and that won’t change. Fossil fuel reserves are limited – future energy demand is unlimited. That is a price crunch in the making. We need alternatives and the backbone of that must be fission energy.
‘SAN DIEGO, (Oct. 13, 2020) – General Atomics Electromagnetic Systems (GA-EMS) announced today that it is collaborating with Framatome Inc. to develop a new helium-cooled 50-Megawatt electric (MWe) Fast Modular Reactor (FMR) concept that will produce safe, carbon-free electricity and can be factory built and assembled on-site, which will reduce costs and enable incremental capacity additions. The GA-EMS led team will be able to demonstrate the FMR design as early as 2030 and anticipates it being ready for commercial use by the mid-2030s…
The FMR will be designed for enhanced safety and ease of operation with fast-response load following and overall high efficiency. The passively safe gas-cooled FMR will use a non-hazardous helium coolant—a chemically inert gas that is nonexplosive, non-corrosive, and does not become activated. Because the reactor is dry-cooled and uses virtually no water to operate, it can be sited nearly anywhere. The power conversion forgoes the use of complex steam generators and pressurizers, and the fuel will operate for approximately 9 years before requiring replacement. The direct helium Brayton cycle enables fast grid response, with up to a 20% per minute power ramping rate for load following, and high overall efficiency of 45% during normal operation. The automatic control of the reactor power and turbomachinery keep the reactor at a constant temperature that mitigates thermal cycle fatigue associated with most load-following reactors.’ https://www.ga.com/general-atomics-and-framatome-collaborate-to-develop-a-fast-modular-reactor
This is one of 20 new designs using established technology that the US government is funding on a dollar for dollar basis. It is one part of a rational response whatever climate throws at us. Building resilient infrastructure is another key. This requires megabucks and thus a thriving economy – that comes with economic freedom and entrepreneurial innovation. The other essential is to conserve and restore agricultural lands and ecosystem with enormous ancillary benefits. Rattan Lal – winner of the 2020 World Food Prize – estimates that 157 ppm CO2 can be sequestered as carbon in terrestrial systems by 2020.
Robert I. Ellison commented:Climate over the past 100 years are most clearly correlated with patterns of sea surface temperature in the eastern Pacific and cloud effect feedback. This caused most of the early 20th century warming, the mid century cooling and half of the warming of the past 40 years
Still fails to understand cause and effect.
“When estimated over the entire historical period (1850–2020), the contribution of natural variability to global surface warming of -0.23°C–0.23°C is small compared to the warming of about 1.1°C observed during the same period, which has been almost entirely attributed to the human influence.”
IPCC AR6 WG1 FAQ 3.2 p 3-102
Mr Apple quotes the IPCC, a political organization created to prove global warming had human causes. In 1995 it declared, with insufficient proof, that all natural causes of climate change were “noise”.
The IPCC claims to know global average temperatures in the 1800s with sparse coverage of the Northern Hemisphere, very little coverage of the Southern Hemisphere, and ocean temperatures defined by buckets and thermometers, almost entirely in Northern Hemisphere shipping lanes.
The same organization repeatedly predicts much faster global warming than has actually happened. Over 33 years the predictions have never been revised down to be more accurate — accuracy obviously does not matter.
And the IPCC came up with an excuse for the lack of warming from 1940 to 1975, as CO2 rose, that was so ridiculous it may have been created by Bozo the Clown.
The IPCC also “looked the other way: as the -0.5 degrees C. global cooling in that period was gradually “revised” away decades after the actual measurements.
People who rely on the iPCC for climate science facts and their always wrong predictions of climate change doom, should be ignored.
Actual global warming in the past 100 years as CO2 levels rose has been intermittent, mild and harmless.
The actual warming since the 1970s has been beneficial — mainly affecting colder regions of the Northern Hemisphere, mainly in the six colder months of the years, and mainly at night.
Reality is that global warming in the past 45 years has been beneficial to the people it most affected, so the climate alarmists, such as Mr. Apple, only use a single global average temperature, that not one person on this planet lives in.
737 comments here and climate science is still not settled !
What a disappointment !
The cause is shifts in patterns of ocean and atmospheric circulation and the effect is cloud change.
https://watertechbyrie.files.wordpress.com/2019/02/tpi-sst.png
‘This study examines changes in Earth’s energy budget during and after the global warming “pause” (or “hiatus”) using observations from the Clouds and the Earth’s Radiant Energy System. We find a marked 0.83 ± 0.41 Wm−2 reduction in global mean reflected shortwave (SW) top-of-atmosphere (TOA) flux during the three years following the hiatus that results in an increase in net energy into the climate system. A partial radiative perturbation analysis reveals that decreases in low cloud cover are the primary driver of the decrease in SW TOA flux. The regional distribution of the SW TOA flux changes associated with the decreases in low cloud cover closely matches that of sea-surface temperature warming, which shows a pattern typical of the positive phase of the Pacific Decadal Oscillation.’
vhttps://www.mdpi.com/climate/climate-06-00062/article_deploy/html/images/climate-06-00062-g002-550.jpg
https://www.mdpi.com/climate/climate-06-00062/article_deploy/html/images/climate-06-00062-g002-550.jpg
It’s some 0.3 degrees C in the last 40 years – the period of most greenhouse gas emissions.
e.g. https://www.nature.com/articles/s41612-018-0044-6
A more advanced Earth science than David is capable of. And nor is he able to accept free markets as the fount of rational responses. He is the complete ideologically hidebound package.
To: RIE
I was trying to determine how you came to your conclusion on the planet rotation theory based on what you said, and I conclude that you got lucky.
If a planet is not rotating, there will be a hot side and a cold side. As the planet rotates, the hot and cold side temperatures will approach one another until they are identical. Heat transfer to and from a planet is governed by the Stefan- Boltzmann equation, which is non-linear. If the planet’s hot side and cold side temperature change, it is possible that the average surface temperature changes with planet spin because of the non-linearity. That is the basis of the planet rotation theory and what must be disproven.
From what I recall, you made three points without explanation. You cited the Stefan-Boltzmann equation and energy in = energy out. Then you said: “You can’s get something for nothing.” I interpret that to mean you must have an energy change to affect a temperature change. The reality is it can appear “you can get something for nothing,” and you can get a temperature change without an energy change. It happens in climate change.
Suppose you observe the earth and its atmosphere at steady state from space. You determine the earth is absorbing and emitting 240 W/m2. From the Stefan-Boltzmann equation, you calculate that the planet’s temperature is 255 K. Now, you look at the radiant profile of the earth. You try to match it to a blackbody radiation profile and find a match to a blackbody radiating at 288 K. The earth’s temperature is 288 K. Still, the energy the earth is emitting only supports a temperature of 255 K. Something for nothing? Of course not. The difference is due to the greenhouse effect.
The most basic equation in heat transfer is q = h(Th – Tc), where q is the heat transferred, h is the heat transfer coefficient, Th is the hot side temperature, Tc is the cold side temperature. It says the heat transferred from a hot body to a cold body is a function of the difference between the temperature of the hot body and the cold body. h = 1/R, where R is the resistance. You probably have seen the symbol R before. When they refer to the R-value of insulation, that’s what they are talking about. The temperature of your home is Th. The outside temperature is Tc. The higher the R-value of your insulation, The smaller the h and q values, which means you lose less heat. The greenhouse effect increases R.
In terms of earth-space heat transfer, q, the energy the earth radiates to space, which is the energy the earth absorbs from the sun, is fixed. Tc, the temperature of outer space, is fixed. As the greenhouse effect increases, R increases, Th, the temperature of the earth increases. To discredit the rotating planet theory, it’s necessary to show that spin does not provide resistance — precisely what I did.
Unless you have an explanation of how your 3 “points” prove the planet rotation theory is invalid, you got lucky. Arm waving proves NOTHING!
OMG
Planck’s law drives the planet to energy equilibrium at TOA – where energy in equals energy out. There is a temperature at which that emission occurs. Long winded stupidity notwithstanding.
Only your arrogance exceeds what you don’t understand.
At TOA of the earth, at steady state, it’s 240 W/m2 in, 240 W/m2 out. Use the SB equation and you come up with a temperature of 255 K. At the earth – atmosphere interface, it’s 240 W/m2 + back radiation in and the same out. Use the SB equation and come up with a temperature of 288 K. the whole process is in energy balance. In your “analysis” that’s not possible because the earth is absorbing and emitting 240 W/m2 at TOA. In your view, a temperature of the earth above 255 K would be a violation of the first law.
Planet rotation is not creating energy, but it might be providing resistance that is restricting heat transfer. That would drive the earth’s temperature higher while the earth is absorbing and emitting 240 W/m2. That would be possible because the SB equation is non-linear. Your “arm waving” disproves NOTHING! You have to show that planet rotation is not interfering with heat transfer.
For somebody who pretends to be an expert, you don’t even understand the basics.
“Long winded stupidity”? Really?
288 K is based on measured surface temperature. BACK
The temperature you get back from SB is always a surface temperature. So what? Do you think that when you calculate the temperature from the radiation at TOA it’s somehow different?
The point is it’s higher due to the greenhouse effect than it would be without it. The earth is warmer.
Amateur hour. Want to try again?
The temperature that is calculated from SB is an equivalent blackbody temperature. That is from a surface. But on Earth there is an atmosphere and the average emission height is from higher in the atmosphere. TOA is a convenient reference point as all energy is electromagnetic.
Back radiation is not plugged into SB.
https://scied.ucar.edu/sites/default/files/images/long-content-page/radiation_budget_kiehl_trenberth_2008_big.jpg
Really? Then how does the temperature of the earth get to 288 K? 240 K only supports a temperature of 255 K.
How do I know?. Because the outgoing radiation is not impacted by the greenhouse effect. It’s the same whether the effect is there or not.
Amateur hour. Want to try again?
It’s quite bizarre. The surface gets to 2888 K because of back radiation. But the average emission height is higher in the atmosphere where it’s cooler. And surely interacting with outgoing radiation is the essence of global warming?
The earth has no idea what’s going on in the atmosphere all it sees is energy that comes at it. It responds to that.
The atmosphere is not a blackbody. A solid can be a blackbody, a dense liquid can be a blackbody, but not a gas. The molecules are too far apart.
The only time I’ve seen them talk about blackbody radiation in the atmosphere is with regards to CO2. What happens in a blackbody is incoming radiation is totally absorbed and converted to kinetic energy. For that to happen the molecules have to be very close together. That doesn’t happen in a gas. Having said that what the climate scientists claim is that the absorption-reradiation of photons gets saturated in the lower atmosphere. That means all the energy that CO2 can absorb from the earth’s radiant energy it absorbs. At that point the atmosphere is opaque to CO2 radiation. Obviously, if that were entirely true, the atmosphere would appear opaque to CO2 at TOA. It’s not. What happened? The claim is that what you see at TOA is from the kinetic energy of the molecules. Planck’s equation models the conversion of kinetic energy to radiant energy. It’s primarily used with blackbodies, but it should work anytime kinetic energy is converted to radiation. SB comes from Planck’s equation.
When they talk about a radiating temperature from SB. That’s an average radiating temperature. That doesn’t mean at some point T in the atmosphere all the radiation from CO2 is being emitted. CO2 can warm or cool the atmosphere by varying the number of photons it emits. It can set its own temperature environment.
As more CO2 gets absorbed, less radiation from CO2 escapes the atmosphere. The blackbody radiating temperature is lower and they claim the radiation is occurring higher in the atmosphere.
There are some nutty theories that go along with this. One is that if the atmosphere’s temperature profile were isothermal putting more CO2 in the atmosphere would have no impact. If the profile were inverted meaning cold at the earth’s surface and hot at the top of the troposphere it would reverse global warming. Never going to happen and I never looked into it, but it sounds crazy to me.
Groan. There are some nutty ideas. The Planck feedback is some -3.2 W/m2/K – SB is derived from Planck’s law and SB provides a convenient comparison. The planet tends to energy equilibrium at TOA. The radiant energy out is the energy in accounting for reflection. But most radiation occurs from the atmosphere. These are just simple realities.
I forgot.
If you correct the 240 W/m2 for the absence of clouds, it would give you the average the surface temperature of the earth without an atmosphere. The 240 W/m2 has nothing to do with the greenhouse effect.
So albedo is zero and the incoming energy is some 340 W/m2. The planet warms up and emitted energy is some 340 W/m2. It is simply energy conservation in a nonequilibrium system.
You forgot the reflection of radiation from the surface.
I deliberately specified zero albedo.
That’s 288 K of course…
Temperature is not nonlinear. It sums to a planetary average – which is not surface temp – at which emissions are some 241 W/m2.
SB provides the average surface temperature
Say you want to calculate the heat transferred between two radiating body’s for two cases. Th=200 K, Tc =100 K and Th= 300K and Tc = 200 K
if q = h(Th – Tc), plug in the numbers for both case and you get the same answer. The equation is linear
If q = h( Th**4 – Tc**4), plug in the numbers for both cases and you get different answers. The equation in non-linear.
Do you know anything?
SB gives the surface temp of a blackbody. The Earth is not a blackbody. And in a nonequilibrium thermodynamic system all of the energy comes from outside. The planet warms to a temperature at which energy emitted equals energy in.
He has such a weak grasp of global warming fundamentals but assumes because I correct him that I am a sceptic. It’s a sort of madness.
He says it isn’t but that it might because of a T to 4th power term. He invents two abstract ‘cases’ 100 K apart to show that the cases have exponentially different emissions. This goes way beyond not knowing how global warming fundamental.
This is nuts
… fundamentals work. It is ignorance coupled with gratuitous rudeness from the first comment.
The planet is warmed by the sun until it reaches a temperature at which emitted radiant flux is equal to absorbed radiant flux. If he cannot understand this simple physical fact it is all far beyond his capacities.
Maybe he understands correlation though. Since CO2 is GMST, CO2 is correlated to itself. Wait that’s not true. Variation is not really controlled by CO2. If I jump and you jump, that’s correlation. If I walk up a plain and you jump a lot, that’s less correlation. CO2 sits in the peanut gallery and pays for everything while the interesting stuff happens on the stage.
There are 1000’s of places to start from.
Chief –
The 7-day moving average for deaths in Florida for Oct 3 is now up to 136.
You said it was definitively 18. When I told you that there is a lag in the reporting, and the number would go up, you said I was “nuts.”. You dismissed articles describing the reasons for the lag as “yellow journalism.”
You were wrong. You angrily attacked me for telling you that you were wrong. You obnoxiously dismissed information that contradicted your erroneous views.
You refuse to acknowledge your error.
You lack integrity. You lack accountability. You lack humility.
Your approach to analysis is as bad as your lame poetry.
Just Joshing is instantly recognisable as someone with less regard for truth and integrity than insanely repeating misrepresentations many, many times for weird political reasons. The next Florida weekly CoV-2 report is due soon. I will link it when it is available as I have been doing – but other than that I have nothing to add.
Chief –
You’re lying again.
There iare no data from the CDC that could possibly erase your error and your lying, or anything I say below:
Chief –
The 7-day moving average for deaths in Florida for Oct 3 is now up to 136.
You said it was definitively 18. When I told you that there is a lag in the reporting, and the number would go up, you said I was “nuts.”. You dismissed articles describing the reasons for the lag as “yellow journalism.”
You were wrong. You angrily attacked me for telling you that you were wrong. You obnoxiously dismissed information that contradicted your erroneous views.
You refuse to acknowledge your error.
You lack integrity. You lack accountability. You lack humility.
This behaviour is just nuts.
https://watertechbyrie.files.wordpress.com/2021/10/compare-state-trends-13.png
J:
Long live Carl XVI Gustaf!
hmmm.,. They need to be willing to take the first step.
‘The top-of-atmosphere (TOA) Earth radiation budget (ERB) is determined from the difference between how much energy is absorbed and emitted by the planet. Climate forcing results in an imbalance in the TOA radiation budget that has direct implications for global climate, but the large natural variability in the Earth’s radiation budget due to fluctuations in atmospheric and ocean dynamics complicates this picture.’ https://link.springer.com/article/10.1007/s10712-012-9175-1
JJBraccili | October 11, 2021 at 11:04 pm |
“Energy is a state function. You set the state of matter by fixing its temperature, pressure, and composition. That amount of energy that matter contains at that state is fixed. You increase the temperature of matter by adding heat. The amount of heat added increases the energy of the matter by the amount of heat added. The matter is at a new increased energy state as indicated by the higher temperature. If the matter is water in a tank and I perfectly insulate the tank so no heat can escape. The tank can maintain its new state FOREVER.”
You appear to be confusing energy and temperature.
Temperature is a state function
The internal energy of the system is proportional to its temperature, internal energy is also a state function.
It can only describe the state of the system at that moment in time.
The problem with your example is that it is impossible.
The whole point of the laws of thermodynamics is to specify that any system with energy in it above that of it’s innate mass and potential energy at absolute zero must lose that energy.It cannot retain or store it in any shape or form.
The words perfectly insulate might apply to thought processes but not to thermal processes.
Water in a tank, is not one object holding temperature, it is both.
The only way the tank can not radiate its energy is if it is at absolute zero.
If it contains heat energy this must inevitably transfer through and be lost as well.
The only container that heat cannot pass through from the inside is a container at absolute zero containing a substance also at absolute zero.
The other name for that is mass without energy.
You have no idea what you are talking about. Your post makes no sense. What I said is correct. I made an idealized example to make a point. Ever hear of reversible work or transferring energy between two bodies at the same temperature. Both are impossible. Ever hear of the Carnot Cycle? Something else that is impossible. Those are used to make the second law of thermodynamics useful. The concepts are used everyday to size compressors and pumps. Lighten up!
That was an answer to someone who claimed you couldn’t store energy. Hmmm! I wonder how rechargeable batteries work. Guess it must be an illusion.
JJBraccili
” I made an idealized example to make a point.”
No, you made up an example that is impossible and argued from there claiming it was possible. In practice, no process is truly adiabatic. Many processes rely on a large difference in time scales of the process of interest and the rate of heat dissipation across a system boundary, and thus are approximated by using an adiabatic assumption. There is always some heat loss, as no perfect insulators exist.
If only the world worked that way.
For an example of the same.
JJB said sorry to me today for that poor example.
Thank you JJB.
Obviously you have come round to my way of thinking.
“That was an answer to someone who claimed you couldn’t store energy. I wonder how rechargeable batteries work. Guess it must be an illusion.”
The law of conservation of energy, also known as the first law of thermodynamics, states that the energy of a closed system must remain constant—it can neither increase nor decrease without interference from outside.
Energy comes in all sorts of forms.
Matter contains intrinsic energy.
Some other types of energy are Electric, Magnetic, Radiant, Nuclear, Ionization, Elastic, Gravitational, Thermal, Heat & Mechanical work.
The first law of thermodynamics is a version of the law of conservation of energy, adapted for thermodynamic processes, distinguishing two kinds of transfer of energy, as heat and as thermodynamic work, and relating them to a function of a body’s state, called internal energy.
You choose to sidetrack the discussion from heat energy by mentioning other types of energy not relevant to thermodynamics.
Worse you describe energy storage, in batteries, as an example of heat being stored.
Wilful obtuseness is not an argument.
The first law of thermodynamics is not concerned with batteries or energy storage in other types of energy, purely in terms of heat flow.
Heat [energy] by definition has to flow.
Flowing means it cannot be stored in matter.
Matter can accept heat energy and this increases its apparent internal energy state only while the energy is flowing into it. It is not being stored merely transferred at a higher rate as it is also flowing out of it.
A bit like radiotherapy of say a prostate lesion.
The space the prostate is in is subjected to a higher level of radiation through cross radiation from a number of directions and cooks.
One could say it got a lot hotter temporarily
.
The prostate temporarily had more energy passing through it while being irradiated.
But, although hotter, at a higher temperature, It was not a store of any extra energy at all.
Looking at it from the outside one would describe it as having higher internal energy in that space at that time but, I repeat, No extra energy was stored.
No batteries, mate.
And a real example of heat transfer to boot.
What are you bothering me for? You have no idea what you are talking about.
You can’t store energy? Ever hear of a battery? The sun radiates stored energy. Ever hear of relativity? Mass is stored energy.
If I suspend any weight in a gravitational field, I store energy. What are you going to argue? That in a billion years the sun goes supernova destroys the planet and therefore the potential energy isn’t stored? This is the DUMBEST discussion I’ve had on this board and that’s saying something.
No process is adiabatic. No s**t. Because a process can’t be made truly adiabatic I can’t tap energy from it? Where did you get your degree in science? Out of a cracker jack box?
“For an example of the same.
JJB said sorry to me today for that poor example.
Thank you JJB.
Obviously you have come round to my way of thinking.”
I did no such thing. Why would a do that to somebody like you? I have not come around to your idiotic way of thinking.
“The law of conservation of energy, also known as the first law of thermodynamics, states that the energy of a closed system must remain constant—it can neither increase nor decrease without interference from outside.”
That shows what you know. The first law of thermodynamics also applies to open systems. Ever hear of enthalpy. The reason it exists is to make dealing with open systems easier.
“The first law of thermodynamics is a version of the law of conservation of energy, adapted for thermodynamic processes, distinguishing two kinds of transfer of energy, as heat and as thermodynamic work, and relating them to a function of a body’s state, called internal energy.”
Internal energy is a state function – heat and work aren’t. Do you know the difference? Apparently, not.
“You choose to sidetrack the discussion from heat energy by mentioning other types of energy not relevant to thermodynamics.
Worse you describe energy storage, in batteries, as an example of heat being stored.
Wilful obtuseness is not an argument.
The first law of thermodynamics is not concerned with batteries or energy storage in other types of energy, purely in terms of heat flow.
Heat [energy] by definition has to flow.
Flowing means it cannot be stored in matter.
Matter can accept heat energy and this increases its apparent internal energy state only while the energy is flowing into it. It is not being stored merely transferred at a higher rate as it is also flowing out of it.”
That idiocy shows you have no grasp of thermodynamics. Thermodynamics deals with ALL forms of energy. ALL forms of energy obey the laws of thermodynamics. Heat and work aren’t the only forms of energy that can be transferred. Apparently you have never heard of kinetic and potential. Oh, that’s right, you think the first law of thermodynamics only applies to closed systems. Ever hear of the general energy balance. How about the mechanical energy balance? No? I’m not surprised.
I bet you have no idea that heat is the transfer of molecular kinetic energy. When you car moves. It has kinetic energy. When you step on the brakes you convert kinetic energy of your car into molecular kinetic energy also know as heat which transfers to the atmosphere.
Hey genius, when you heat or do work on matter you increase it’s internal energy. That is STORED energy. When you take energy from the matter it can be in the form of heat or work and you decrease the internal energy of the matter. When you stick a thermometer in a liquid you are measuring the amount of molecular kinetic energy. If that liquid comes in contact with a surface of lower kinetic energy. It transfers its kinetic to the surface until the kinetic energies are balanced. Sounds like energy being stored and transferred to me.
What? Don’t like how I’m using thermodynamics to shoot down climate denial junk science? All your doing is making yourself look like an idiot. I have a feeling that you do that quite often.
The fact that planet receives a solar flux, does not mean its energy first warms planet surface and only then the warmed surface emits the same incident amount of solar energy as IR EM emission.
EM radiation is not a heat transfer process, like the heat conduction is…
EM radiation is a flux-surface-matter interaction process.
https://www.cristos-vournas.com
JJBraccili | October 23, 2021 at 11:33 pm |
“What are you bothering me for?”
Nothing like a good rant to get those negative energies out of the system is there?
I cannot help it if pointing out errors causes you to get bothered.
Perhaps if you step back and look at what people like RIE are saying you
might get your facts right.
I do not mind you having motivated arguments.
I just like the facts you use to be correct.
You say “You can’t store energy?” in the context of thermodynamics.
Then change the concept of the energy we are talking about.
In thermodynamics we have thermal energy, heat.
That’s it.
Now show me how you store heat again?
and in what form.
“Mass is stored energy.”
What Einstein thought of that?
Mass is mass, energy is energy.
Mass just sits there.
Energy is energy, it moves [i.e.] by definition is not stored.
Chuck in a bit of time space and we have a problem, Houston.
You see when you separate masses and have them nearby all sorts of anomalies arise.
Gravity, magnetism and intermingling.
The immovable object and the unstoppable force have to compromise and co exist in time space.
Thus giving rise to the concepts of energy in it’s different forms.
One of which is heat [EM]
Mass is not heat, is it?
My facts are correct.
Heat is energy in motion. When something is heated, the heat becomes internal energy. It is stored as internal energy. That energy can be used to perform heat or work at some later time. Neither heat or energy is a state function. If no work is performed, any change internal energy, a state function, gives the heat transferred. If the process is adiabatic, any change in internal energy gives the work performed.
The heat transferred to and the work performed on a system become internal energy.
What’s your point? The earth can’t store energy so climate change is a hoax? LOL!!!
Do you understand what the First Law of Thermodynamics means? It doesn’t seem so.
RIE needs to get his facts straight. It’s evident he doesn’t understand the basics.
“What Einstein thought of that?
Mass is mass, energy is energy.
Mass just sits there.
Energy is energy, it moves [i.e.] by definition is not stored.”
LOL!! What do you think E=mc**2 means. In Einstein’s original paper he wrote the equation as m = E / mc**2. Do you know why he did that? to emphasize MASS IS ENERGY.
“Mass is not heat, is it?”
When a nuclear bomb explodes what happens? Mass is destroyed and heat and work are produced. Sounds to me like energy was stored in the mass and became heat and work. What do you think? Maybe, it was the energy fairy and the mass never disappeared.
You don’t know a damn thing! Go play in traffic.
JJBraccili | October 26, 2021 at 9:49 pm |
My facts are correct.
“Heat is energy in motion.”
Pardon? What I said?
Thanks.
Energy [heat] flows [motion]
If there is no flow of energy there is no heat.
The only reason matter can appear hot is that energy is flowing into it or out of it, not stored in it.
Moving matter is not hot unless it has been heated.
If heat input ceases it goes cold, no matter how fast it is moving.
“When something is heated, the heat becomes internal energy.”
Sort of.
But it is not stored.
The heat goes in and heat goes out.
It does not stay there stored.
All you are saying is that the internal energy state reflects the usable energy currently passing through.
It does not pull up into a parking lot or electron orbit and stay there for later use. It does a wheelie or two and exits stage left.
You are confusing the amount of energy measured with energy stored.
It is not in any form of storage.
” It is stored as internal energy.”
Confused. Storage means putting aside for a later time. SB says what goes in has to come straight out again.
It does not go into molecular vibration and electron orbit states and stay there. The molecules wish to return to their undisturbed state straight away.
“That energy can be used to perform heat or work at some later time.”
That’s right. it sits in that atomic Dunlop battery ready to go a year later. What is that battery called again?
I’m sure its not the molecular heat battery next to the nucleus is it.
“‘Neither heat or energy is a state function.
Yet JJBraccili | October 11, 2021 at 11:04 pm |
“Energy is a state function”
“What’s your point? The earth can’t store energy so climate change is a hoax? ”
It cannot store energy.
No battery, remember.
Explanations that rely on a Radiative Imbalance that is impossible by definition mean that the theories espoused are wrong.
CO2 has a greenhouse effect
H20 has a much larger GHG effect.
Climate change occurs naturally both with and without CO2 changes.CO2 rise from human activity should have a modest effect .
“Do you understand what the First Law of Thermodynamics means?”
I learn more every day.
“RIE needs to get his facts straight. It’s evident he doesn’t understand the basics.”
As I said if you stopped and listened to him you would learn a lot.
I may disagree, at times, because I try to think for myself.
It is not quite Rule 1 ,Rule 2 but at least 9 out of 10.
What do you think E=mc**2 means.
In Einstein’s original paper he wrote the equation as m = E / mc**2.
“Do you know why he did that?”
Yes.
“to emphasize MASS IS ENERGY.”
No.
He did that to emphasis mass has an equivalence with energy when it is multiplied by a factor of the speed of light squared.
You cannot take mass on its own and compare it to energy on its own.
They are two distinct entities.
A car without petrol and a motor is mass, it just sits there. It can never be in motion.
Energy is motion like radiation, it goes on for ever and never stops.
When they share a common time space continuum they share a reciprocity.
angech
“What do you think E=mc**2 means.
In Einstein’s original paper he wrote the equation as m = E / mc**2.
“Do you know why he did that?”
Yes.
“to emphasize MASS IS ENERGY.”
No.
He did that to emphasis mass has an equivalence with energy when it is multiplied by a factor of the speed of light squared.
You cannot take mass on its own and compare it to energy on its own.
They are two distinct entities.”
…mass has an equivalence with energy when it is multiplied by a factor of the speed of light squared.
Right! Thank you.
https://www.cristos-vournas.com
Let’s only talk heat. Leave work out of it.
Let’s leave out the abstractions. This is all about molecular kinetic energy. Heat is the transfer of that energy between two systems. Temperature is a measure of the average kinetic energy of whatever you stick a temperature probe into. Let’s say I take a tank and I measure it’s temperature, that’s a measure of its kinetic energy. I add kinetic energy to the tank by “heating” it. The temperature of the tank goes up. That kinetic energy remains there until I remove it by extracting it to “heat” something else. That’s all there is too. Yes, you can store energy. If heat just went in and out, the temperature of the tank would never change.
In science and engineering we routinely say something has heat content. We use the terms specific heat, heat of reaction, heat of vaporization. All of those are state variables. Heat is not. You want to argue over semantics. Somehow, in your warped perspective, you claim energy can’t be stored. That ridiculous!!!
I don’t even know how to respond to the rest of your post. It’s so stupid. I’ll respond to the crazier parts — that’s most of it.
I have to apologize to CV. I thought he was responding to me about relativity. You were the idiot who wrote that nonsense. You can read what I said to him.
“It does not go into molecular vibration and electron orbit states and stay there. The molecules wish to return to their undisturbed state straight away.”
The “heat” energy increases the translational, rotational, and vibrational of molecules and atoms. It “stays” there until there is a collision with other molecules and atoms. Some energy transfer occurs from the molecules and atoms of higher kinetic energy. If they both have the same energy, nothing happens.
“That’s right. it sits in that atomic Dunlop battery ready to go a year later. What is that battery called again?
I’m sure its not the molecular heat battery next to the nucleus is it.”
LOL!!! Batteries store and release energy by chemical reaction.
“‘Neither heat or energy is a state function.””
If I said that, I was probably laughing to hard from what I was reading. Heat or work is not a state function, but heat + work is. Let’s see if you can figure out why. It has something to do with a well know scientific principle.
“Confused. Storage means putting aside for a later time. SB says what goes in has to come straight out again.”
SB says nothing of the sort. It a relationship between temperature and radiant energy. You confused it with the first law of thermodynamics which says no such thing. In fact, it says just the opposite.
You know what I can learn from you? NOTHING!!!! You have no idea what you are talking about. I learned a long time ago when you don’t understand a subject, keep your eyes and ears open and your mouth shut. Don’t put your ignorance on full display. Guess what you’ve been doing?
JJBraccili | October 27, 2021 at 11:19 am |
Let’s only talk heat. Leave work out of it. OK
This is all about molecular kinetic energy. No
[Heat exists as radiation e.g.you can detect it by a temperature probe].
The term kinetic energy is a misnomer. A molecule has no heat.
Heat is the EMR emitted from an atom in response to a change of state.
What you measure is the energy [heat] passing through the system
“Heat is the transfer of that energy between two systems.”
[Energy can be transferred in other ways but we will leave work out of it].
Temperature is a measure of the average kinetic [heat] energy of whatever you stick a temperature probe into. OK
Let’s say I take a tank and I measure it’s temperature, that’s a measure of its kinetic [heat] energy. OK
I add kinetic[ [heat] energy to the tank by “heating” it. OK
The temperature of the tank goes up. OK
That kinetic[heat] energy remains there until I remove it by extracting it to “heat” something else. NO.
You say that it remains there until you do something.
Pour hot water into a cup. that’s a small tank.
Go away for an hour and come back.
Did the heat stay there to give you a hot drink?
No.
The energy cannot stay in a mass on its own. There is no storage in the water.
” Yes, you can store energy. If heat just went in and out, the temperature of the tank would never change.”
So heat goes into tanks and just stays there?
Open a tap in 5 years and it just flows out?
Heat goes in and out, the temperature, which is a measure of the amount of energy passing through the tank, goes up while the energy is passing through.
” I learned a long time ago when you don’t understand a subject, keep your eyes and ears open and your mouth shut. Don’t put your ignorance on full display.”
So sorry to hear that.
When you did not understand something, with your eyes and ears open and mouth shut you pretended to know and kept doing the same thing that failed to educate you in the first place.
Best practice is to ask questions if you do not understand, not to hide your ignorance. Being ignorant and recognizing that one lacks knowledge and needs help is the first step. If you do not put your thoughts out there for comment or correction you will never learn.
Took me 30 years to learn that.
You don’t understanding anything. It’s no wonder you hold the idiotic opinions you do.
“Pour hot water into a cup. that’s a small tank.
Go away for an hour and come back.
Did the heat stay there to give you a hot drink?
No.
The energy cannot stay in a mass on its own. There is no storage in the water.”
You just disproved your own point. You have a hot cup of water. You go away for an hour and it lost energy by convection, evaporation, and a very small amount by radiation. If energy wasn’t stored in the hot water in the first place, where did the energy come from that it lost? I know, it was the energy fairy. Funny, how she always shows up just in time.
Let’s devise a little experiment. let’s take your hot water in the cup. Put a lid on it so it can’t lose energy by evaporation. Then put it in a constant temperature bath at the exact same temperature as the hot water so it can’t lose energy by conduction or convection. Then let’s shine IR radiation at it at the exact same amount as the cup loses by radiation. Come back 1 hr, 1 day, 1 year, or 100 years later and the hot water will be at the exact same temperature. If I remove the cup from the experiment, it will start losing energy and the temperature of the hot water will drop. I’d say that the hot water was storing energy.
“Best practice is to ask questions if you do not understand, not to hide your ignorance.”
The problem with that is, you usually don’t know the questions to ask. Better to listen, learn, think about it, and then ask questions. Look how well your way has served you in this discussion. You keep on making the same idiotic statements because you have no idea what you are talking about.
Two bodies that are at the same temperature stay in mutual thermal equilibrium, so a body at temperature T surrounded by a cloud of light at temperature T on average will emit as much light into the cloud as it absorbs, following Prevost’s exchange principle, which refers to radiative equilibrium. The principle of detailed balance says that in thermodynamic equilibrium every elementary process works equally in its forward and backward sense.[23][24] Prevost also showed that the emission from a body is logically determined solely by its own internal state. The causal effect of thermodynamic absorption on thermodynamic (spontaneous) emission is not direct, but is only indirect as it affects the internal state of the body. This means that at thermodynamic equilibrium the amount of every wavelength in every direction of thermal radiation emitted by a body at temperature T, black or not, is equal to the corresponding amount that the body absorbs because it is surrounded by light at temperature T
So? You pulled something from somewhere that you have no idea what it means and isn’t relative to the discussion. I guess you are unaware we are discussing kinetic energy. We are also talking about systems that are not in equilibrium, but are in an unsteady state. Energy stored in a system does not get transferred if the system is in equilibrium.
That pretty much sums up what you know about thermodynamics. NOTHING!
Kinetic energy is the energy of moving objects.Kinetic energy does not make things move, instead, it is the energy of things that are in motion. Heat is the transfer of thermal energy from one object to another.
–
JJB “I guess you are unaware we are discussing kinetic energy.”
I thought we were discussing energy as heat.
“We are also talking about systems that are not in equilibrium, but are in an unsteady state.”
I thought we were discussing energy as heat.
“Energy stored in a system does not get transferred if the system is in equilibrium.”
How does one store energy?
How does one store heat energy?
Importantly, how does one store kinetic energy?
The point I am making is that energy cannot be stored as heat.
If heat exists it implies movement of energy, not movement of mass.
If no heat is present in a system in equilibrium there is no usable detectable heat in the system.
None.
This can be considered in two settings.
One absolute zero. By this I mean all motion has ceased.
Individual atoms have an internal energy state to exist but this is never a source of heat.
Two is a system, as you put it, in equilibrium.
Never mind that this is impossible in that to be in equilibrium there is a larger system around it doing work to maintain this artifice.
In such a system there is heat but no heat storage and there never will be by your definition.
The heat in a system must always be dissipating, exiting, leaving, radiating or reducing by expansion of the system.
Entropy or thermodynamics, what you will.
If it is in equilibrium the Heat is being put into the system at the same rate that it is leaving.
This is a constant generation of new energy to keep the system in equilibrium that people ignore when talking about steady state systems.
“I thought we were discussing energy as heat.”
Heat is the transfer of molecular kinetic energy. Why am I not surprised you didn’t know that?
“How does one store energy?
How does one store heat energy?
Importantly, how does one store kinetic energy?
The point I am making is that energy cannot be stored as heat.
If heat exists it implies movement of energy, not movement of mass.
If no heat is present in a system in equilibrium there is no usable detectable heat in the system.
None.
This can be considered in two settings.
One absolute zero. By this I mean all motion has ceased.
Individual atoms have an internal energy state to exist but this is never a source of heat.
Two is a system, as you put it, in equilibrium.
Never mind that this is impossible in that to be in equilibrium there is a larger system around it doing work to maintain this artifice.
In such a system there is heat but no heat storage and there never will be by your definition.
The heat in a system must always be dissipating, exiting, leaving, radiating or reducing by expansion of the system.
Entropy or thermodynamics, what you will.
If it is in equilibrium the Heat is being put into the system at the same rate that it is leaving.
This is a constant generation of new energy to keep the system in equilibrium that people ignore when talking about steady state systems.”
That’s a word salad that says nothing!
Let me clear it up for you. You are in a state of confusion.
The heat that is transferred to a system is stored as molecular kinetic energy. Temperature is an abstraction that indicates how much molecular kinetic energy is stored. When I want to transfer stored kinetic energy from one system to another, the process is called heating or cooling. The energy is transferred from the system with the higher kinetic energy to the system with lower kinetic energy where it is stored.
JJBraccili | October 28, |
“Pour hot water into a cup. that’s a small tank.
Go away for an hour and come back.
Did the heat stay there to give you a hot drink? No.
The energy cannot stay in a mass on its own. There is no storage in the water.”
–
You just disproved your own point. You have a hot cup of water. You go away for an hour and it lost energy by convection, evaporation, and a very small amount by radiation.
? You agree it lost energy, it did not store it.
“it lost energy by convection, evaporation, and a very small amount by radiation.”
Basically it lost all of its energy by radiation.
You continue to miss the energy dynamics going on.
The room air is radiating IR to the cup, as are the walls. The cup is losing energy by IR from the liquid surface and the cup surfaces.For a Cup of tea at 90C for 1 hour there is a huge amount of radiation out [SB probably].
At the same time, unacknowledged IR [heat] is pouring back into the cup from all parts of the room and air.
When it cools down to room temperature you can say it has lost so many joules [what it took to heat it up] but it lost a far larger amount than that over the course of an hour.
All except the joules put into it initially were returned by the system.
At room temp with according to you no heat exchange the cup is still radiating at 25C a large amount of IR every second.
Why does it not get colder?
Not because of storage.
It is not storing tea at 25C it is having heat input constantly from the room and in turn is doing its bit to heat the room.
” If energy wasn’t stored in the hot water in the first place, where did the energy come from that it lost?”
An external electric heat source.
You have no idea what your are talking about. You jump around like a Mexican jumping bean and say nothing. You try to justify your position by arguing semantics.
IF your point is that climate change can’t be happening because the earth can’t store heat, I have bad news for you. That’s EXACTLY the opposite of what the First Law of Thermodynamics says. You don’t understand it.
Your problem is that you want to disprove climate science and your more than willing the twist science into a pretzel to fit the narrative you want. You’re not even good at it because you don’t understand the science.
Go find somebody else that doesn’t understand science to argue with. Your illogic might find a more receptive audience.
Actual is measured at 288K
Mathematical Abstraction results in 255K
Is S/B wrong?
S/B is wrongly used. It should be used on every infinitesimal spot at every instant and then integrate over the sphere’s surface.
Thus the New equation has emerged.
The New equation takes in consideration three major new concepts:
1). Planet does not absorb the not reflected portion of the incident solar SW EM energy.
What planet does is to instantly transform the not reflected portion from SW into IR outgoing emission.
Only a very small fraction is accumulated in the inner layers.
2).Planet reflects as a sphere (Φ -factor).
3). Planet rotates (Planet Rotational Warming Phenomenon).
………………………..
The Planet Mean Surface Temperature Equation
Tmean = [ Φ (1-a) S (β*N*cp)¹∕ ⁴ /4σ ]¹∕ ⁴
gives wonderful results Tmean.earth = 287,74 K, Tmean.moon = 223,35 K, Tmean.mars = 213,21 K and
Tmean.mercury = 325,83 K
Using the new equation, the new estimate closely matches the estimate surface temperatures from satellite observations:
Tsat.mean.mercury = 340 K
Tsat.mean.earth = 288 K
Tsat.mean.moon = 220 K
Tsat.mean.mars = 210 K
Planet…Te.incompl….Tmean….Tsat.mean
……….equation….equation…measured
Mercury….439,6 K…325,83 K….340 K
It is time to abandon the old
Te = [ (1-a) S /4σ ]¹∕ ⁴ incomplete equation.
https://www.cristos-vournas.com
I posted an answer to the # of molecules problem yesterday. I’ll give you a brief synopsis. An Earth to Mars comparison is apples to oranges. The only source of the greenhouse effect on Mars is CO2. On Earth, the greenhouse effect is due mostly from CO2 and H2O, CO2 makes up 20% of the effect and H2O makes up 75%. CO2 “controls” the H2O effect by increasing or decreasing the atmospheric temperature.
Still pushing the debunked planet rotation theory?
The only way it could work is if a planet absorbs more solar energy rotating than when it ‘s not rotating. With the non-linear response I thought it might be possible. My first example showed a small planetary temperature change due to planet rotation. It was wrong. I made a couple of mistakes. One was I assumed steady-state. I realized I had to put the planet in an unsteady state and see if there was an energy imbalance. I rotated the planet 180 degrees. I thought I’d get a small energy imbalance. There was none. That disproves the planet rotation theory.
“1). Planet does not absorb the not reflected portion of the incident solar SW EM energy.
What planet does is to instantly transform the not reflected portion from SW into IR outgoing emission.
Only a very small fraction is accumulated in the inner layers.”
That statement is WRONG! What your saying is that all the absorbed solar radiation is instantly radiated as IR to space. At the same time a small portion accumulates in the “inner layers”. Where did that energy come from — the energy fairy? Energy in can’t be equal to energy out if energy is accumulating. It makes no difference how “small” the accumulating energy is. It will keep building up, raising the planet’s temperature until that average temperature of the planet equals the average radiating temperature, which will equal the average radiating temperature of the surface of the planet.
Your equation is nothing more than a curve fit manipulated with constants to fit the data to get the results you want. The theory is nothing more than junk science.
You can keep pretending your theory is valid all you like. That doesn’t make it so.
Christos
“S/B is wrongly used. It should be used on every infinitesimal spot at every instant and then integrate over the sphere’s surface.”
The one wrongly using the equation by not taking every infinitesimal spot at every instant and then integrate over the sphere’s surface is you. Your equation for Tmean does not do that at all.
atandb, of course I have.
Here it is:
Jemit = 4πr²σΤmean⁴ /(β*N*cp)¹∕ ⁴ (W) it is the entire sphere’s emission in Total (W)
Planet Energy Budget:
Jabs = Jemit
πr²Φ*S*(1-a) = 4πr²σTmean⁴ /(β*N*cp)¹∕ ⁴ (W)
Solving for Tmean we obtain the PLANET MEAN SURFACE TEMPERATURE EQUATION:
Tmean.planet = [ Φ (1-a) S (β*N*cp)¹∕ ⁴ /4σ ]¹∕ ⁴ (K)
https://www.cristos-vournas.com
JJBraccili, everything is all right with the theory.
What planet does is to instantly transform the not reflected portion from SW into IR outgoing emission.
Only a very small fraction is accumulated in the inner layers.
I should have added, I thought it was meant already, but science has its special very precise and demanding language…
The process described is the solar flux-surface interaction process. It takes place during the solar lit hours.
There is the nighttime hours, at nighttime hours the accumulated energy is IR emitted outgoing EM energy, so the balance is always there, planets never get overheated…
The Planet Surface Rotational Warming Phenomenon takes care of it.
https://www.cristos-vournas.com
You can’t have energy accumulating if energy in = energy out.
You can’t have a difference between the average surface temperature and the average temperature of the planet and be at steady-state.
There are serious problems with your “theory” that you haven’t satisfactorily addressed. Everything is not “all right” with your “theory”
JJBraccili, planet rotates continuously, what is kept from day-time is IR emitted at night. The faster planet rotates the warmer planet it is.
The Global Warming Trend is another issue. It is due to variations in orbital forcing.
The New equation calculates planet without-atmosphere or with very thin atmosphere (Earth and Titan included) the actual mean surface temperature…
https://www.cristos-vournas.com
“JJBraccili, planet rotates continuously, what is kept from day-time is IR emitted at night. The faster planet rotates the warmer planet it is.”
Where does the energy come from that causes the planet to get hotter? By your own example energy in = energy out. Unless energy is created out of thin air, the planet can’t get hotter. In your example, you just averaged out the temperatures and because of the non-linearity of S-B the average came out higher. That proves NOTHING! All the proves is that S-B is non-linear.
“The Global Warming Trend is another issue. It is due to variations in orbital forcing.”
NONSENSE! If they occur, they occur over a much longer timeframe than what we are seeing.
About those “orbital forcing’s”, That would show up as increases in solar radiation. Solar radiation has been flat to trending down over the last 40 years. Your explanation explains NOTHING!
.
https://www.cristos-vournas.com
LIVE: Lava still flowing one month after volcano erupted on La Palma Island
https://youtu.be/s8ejxUVIYGs
The eastern Pacific jet current pattern remains unchanged. Another front with precipitation will cover all of California in two days.
https://i.ibb.co/MkCWP9L/pobrane.png
https://scx2.b-cdn.net/gfx/news/2021/gulf-stream-and-kurosh.jpg
The above jetstream pattern is confirmed over the Atlantic. It is now falling over central Europe.
https://i.ibb.co/mGqBbnj/pobrane-1.png
‘Weather is a symptom of climate’ said Dame Meg Hillier, Chair of the UK Public Accounts Committee today. It hasn’t seemed to have occurred to the lady that our understanding of climate is simply an averaging exercise applied to our known and exceedingly limited time and location records of the weather. Cumulative monthly records give a better relative understanding of weather by comparing decade against decade since it is possible to find repeating similarities and patterns in temperature, sun hours, rainfall amounts, wind force, wind direction, and barometric pressure ranges. Going back fifty/sixty years suggests there is very little difference in weather now compared to weather then, and that anything and everything is possible regardless of our belief that we are influencing and controlling the weather and climate by burning fossil fuels.
Our fascination with highs and lows in isolation feels unscientific rather like searching for extremes or treasures or hyperbole rather than understanding the rather more subtle data that is buried deep underneath the roots that produce the low lying fruit we are mighty eager to pick. The latter is easy work and well paid, whereas the former can be career ending.
Our months also roughly correspond with moon cycles although it is forever possible that any month will contain two identical lunar phases. Our astronomical seasons follow the solar cycle providing the seasons something the meteorological calendar stopped following for the digital age, a small but unnecessary change IMHO.
So far as climate change and our input to the equation goes I think we are dumber now than we were pre-climate emergency because the UN’s IPCC is not fit for purpose, and much of the published and peer reviewed science being used in support of our ludicrous carbon policy is not worth the paper it is printed on. A coal fired power station is a coal fired power station whether it is located in my backyard, in China, in India, or on the site of the UN building. If there were a real climate emergency who on earth would have sanctioned one new coal fired power station build in the last thirty plus years?
When will climate science appolodists understand that you cannot prove that “climate science” is true because “climate science says it is true?
You have to use first principles
If straw-o-graphy was a field of study, Dmitry would be its leader.
The dream of founding empirical sciences on an axiomatic method has died a long time ago. Channeling your High Expectation Father only reveals you have not really studied these matters.
One could argue that parts of them could be axiomatized, for instance measurement theory. Scientific structuralism was all the rave in the 70’s. But even then there are still conceptual problems lingering.
Rookies these days. They know nothing and thus believe to invent everything.
Isakov Dmitry commented:
You have to use first principles
What do you think a climate model is?
descriptions:
NCAR Community Atmosphere Model (CAM 3.0)
http://www.cesm.ucar.edu/models/atm-cam/docs/description/description.pdf
https://opensky.ucar.edu/islandora/object/technotes%3A477/
NASA GISS GCM Model E: Model Description and Reference Manual
https://www.giss.nasa.gov/tools/modelE/
Also curious how much of physics you think is derived from “first principles.”
David watch out for strong winds in Oregon.
How do they handle turbulence with the first principles?
Your first link does not work today, I’ll try on Monday.
Curious George commented:
How do they handle turbulence with the first principles?
The links worked for me right now.
The link works today. In Appendix A, “Physical Constants” there is a “Latent heat of vaporization”. You are aware that this is not a constant. The sure sign of a scientific amateur.
Curious George commented:
In Appendix A, “Physical Constants” there is a “Latent heat of vaporization”. You are aware that this is not a constant. The sure sign of a scientific amateur.
Hilarious. You skipped over the entire document, dense with equations, about which you understood absolutely nothing, and focused on one miniscule piece as if you understood *that*.
How much does Lv vary with temperature, George, over the range considered in the model?
By 3%. Than can do a lot over 100 years.
https://judithcurry.com/2013/06/28/open-thread-weekend-23/#comment-338257
Note that they did nothing to correct the problem in 8 years.
Curious George wrote:
By 3%. Than can do a lot over 100 years.
https://judithcurry.com/2013/06/28/open-thread-weekend-23/#comment-338257
Note that they did nothing to correct the problem in 8 years.
Your analysis is wrong because it assumes the error of 3% are all in one direction — it’s actually +/- 3%. It also assumes the error is large relative to other errors in the problem.
The idea that you, who can’t understand a single thing in that model document full of equations, who has no idea of the error analysis in the calculation, can dismiss it based on one little item about Lv, or a little email conversation with an anonymous ucar person, is absolutely comical. Experts pour over these models for decades, George. You of all people don’t get to dismiss them over a tantrum about the latent heat of vaporization. So sad. But a perfect example of a denier who is determined to reject climate science based on anything at all.
LOLz.
David dear,
as usual you did not bother to read my link. It is 3% in one direction, it overestimates transport of heat by evaporation from tropical seas.
Do you really believe that when you have a model full of equations, you can feed it with incorrect data and still get useful results? For good results all data has to be correct. 97% is not enough.
The sure sign of a scientific amateur.
https://judithcurry.com/2012/08/30/activate-your-science/#comment-234131
User Gavin explains why many models use a constant specific heat of vaporization: “If the specific heats of condensate and vapour is assumed to be zero (which is a pretty good assumption given the small ratio of water to air, and one often made in atmospheric models) then the appropriate L is constant.”
Models rely on a “very good assumption” without any error analysis of its consequences. How good is it? “Very”.
Long live science. And we are spending trillions on this nonsense.
George, thanks for that explanation from Gavin (Schmidt, I assume).
What’s wrong with “very good?”
The models work.
What’s wrong with “very good?”
It is not even a bad science.
Curious George commented:
“What’s wrong with “very good?””
It is not even a bad science.
Why?
It is not even a bad science. Why?
Because it is not quantifiable. It is only a hand-waving. But I am glad to explain it to a famous PhD. SUNY, what a school!
The models work, George:
“We find that climate models published over the past five decades were skillful [14 of 17 projections] in predicting subsequent GMST changes, with most models examined showing warming consistent with observations, particularly when mismatches between model‐projected and observationally estimated forcings were taken into account.”
“Evaluating the performance of past climate model projections,” Hausfather et al, Geo Res Lett 2019.
https://doi.org/10.1029/2019GL085378
figure:
https://twitter.com/hausfath/status/1202271427807678464?lang=en
The greatest extent of sea ice in the south is observed in September.
https://masie_web.apps.nsidc.org/pub/DATASETS/NOAA/G02135/south/monthly/images/09_Sep/S_09_extent_anomaly_plot_hires_v3.0.png
This winter will be just as cold in Antarctica, and perhaps the cooling will extend into the spring months. Just see the size of the ozone hole in 2020 and 2021. In 2020, the ozone hole in November and December was a record high in the history of measurements.
https://www.cpc.ncep.noaa.gov/products/stratosphere/polar/gif_files/ozone_hole_plot.png
Please abolish refrigerators!
“When the model started with the decreased solar energy and returned temperatures that matched the paleoclimate record, Shindell and his colleagues knew that the model was showing how the Maunder Minimum could have caused the extreme drop in temperatures. The model showed that the drop in temperature was related to ozone in the stratosphere, the layer of the atmosphere that is between 10 and 50 kilometers from the Earth’s surface. Ozone is created when high-energy ultraviolet light from the Sun interacts with oxygen. During the Maunder Minimum, the Sun emitted less strong ultraviolet light, and so less ozone formed. The decrease in ozone affected planetary waves, the giant wiggles in the jet stream that we are used to seeing on television weather reports.”
https://earthobservatory.nasa.gov/images/7122/chilly-temperatures-during-the-maunder-minimum
https://www.iup.uni-bremen.de/gome/solar/mgii_composite_2.png
“The last astronauts of the Apollo program were lucky. Not just because they were chosen to fly to the Moon, but because they missed some really bad weather en route. This wasn’t a hurricane or heat wave, but space weather – the term for radiation in the solar system, much of which is released by the Sun. In August 1972, right in between the Apollo 16 and Apollo 17 missions, a solar storm occurred sending out dangerous bursts of radiation. On Earth, we’re protected by our magnetic field, but out in space, this would have been hazardous for the astronauts.
The ability to forecast these kinds of events is increasingly important as NASA prepares to send the first woman and the next man to the Moon under the Artemis program. Research now underway may have found a reliable new method to predict this solar activity. The Sun’s activity rises and falls in an 11-year cycle. The forecast for the next solar cycle says it will be the weakest of the last 200 years. The maximum of this next cycle – measured in terms of sunspot number, a standard measure of solar activity level – could be 30 to 50% lower than the most recent one. The results show that the next cycle will start in 2020 and reach its maximum in 2025.”
https://www.nasa.gov/feature/ames/solar-activity-forecast-for-next-decade-favorable-for-exploration
Φ – is the Planet Surface Solar Irradiation Accepting Factor. It is a New and very important concept for the correct estimation of planetary “energy in” (not reflected) SW EM energy estimation. I have proposed to the scientific community… because Φ is a key parameter in the planetary Radiative Energy Budget.
https://www.cristos-vournas.com
Let’s continue with this mathematical abstraction: The planet blackbody Te equation
Te = [ (1-a) S /4σ ]¹∕ ⁴
the Φ -factor for planet Earth is Φ=0,47
The Planet Corrected effective temperature (which still remains a mathematical abstraction) Te.correct for Earth is:
Te = [ Φ(1-a) Sο /4σ ]¹∕ ⁴
When substituting values
The corrected mathematical abstraction Te for planet Earth is
Te = 210 K
https://www.cristos-vournas.com
You should wait before posting again. I posted a long post that will end the discussion. For some reason, long posts take awhile before they are distributed.
That’s it? Okay, that tells me all I need to know.
18:30:
https://odysee.com/@BretWeinstein:f/bret-and-heather-101st-darkhorse-podcast:6
About the scientific consensus from Heying. 95% applicable to climage change and those waste of time John Cook cult of squirrel pointing exercises.
First they came for fossil fuels and I said nothing.
Florida is reporting fewer cases of the Chinese coronavirus per capita than its blue state counterparts, according to the New York Times’ Saturday data.
The Times’ chart provides the daily average of cases, as well as the number per 100,000. Florida is at the bottom of the list in terms of cases per capita, reporting 10 per 100,000 as of Saturday — a decrease of 42 percent in the last two weeks. Only one state, Hawaii, is reporting lower cases per capita, coming in at eight.
And the Swedes are still kicking our butts. While eating lutefisk. Good thing we got the CDC and the NIH.
Ragnaar –
Do you have any thoughts on why Sweden has 3 X the per capita rate of deaths compared to Denmark, 7 X the rate compared to Finland, and 9 X the rate of Norway?
Do you think there’s any connection between the much higher death rates in Sweden to the higher case rate in Sweden, where Sweden’s rate is about twice that of Denmark (with about 1/12th the rate of testing), and about 3 X that of Norway (with a roughly similar level of testing), and about 4 X that of Finland (with a more or less similar level of testing)?
Asking for a friend.
Ragnaar –
I do love you boyz:
> Florida is reporting fewer cases of the Chinese coronavirus per capita than its blue state counterparts,
Top 10 states in per capita cases:
North Dakota, Tennesse, Alaska, Wyoming, S. Carolina, S. Dakota, Florida, Utah, Arkansas, Mississippi,
Top 10 states in per capita testing:
Rhode Island, Alaska, Massachusetts, New York, Vermont, Connecticut, DOC, Illinois, Maine, California.
> Florida is at the bottom of the list in terms of cases per capita, reporting 10 per 100,000 as of Saturday
Please, please, please tell me you’ve accounted for the lag in reporting in Florida. “Cause I’d hate to think that you’re that incapable of learning from the previous times you (and your boyz) didn’t account for lags.
From Oct. 22nd, with accounting for the lag in reporting.
In the past seven days, on average, the state has added 128 deaths and 2,090 cases per day, according to Herald calculations of CDC data.
Read more at: https://www.miamiherald.com/news/coronavirus/article255205866.html#storylink=cpy
So I think that 10 per 100k does work out with the lag…
Pingback: Energy Budget | Pearltrees
JJBraccili
“If a planet is not rotating, there will be a hot side and a cold side. As the planet rotates, the hot and cold side temperatures will approach one another until they are identical. Heat transfer to and from a planet is governed by the Stefan- Boltzmann equation, which is non-linear. If the planet’s hot side and cold side temperature change, it is possible that the average surface temperature changes with planet spin because of the non-linearity. That is the basis of the planet rotation theory and what must be disproven.”
“As the planet rotates, the hot and cold side temperatures will approach one another until they are identical.”
It is an impossible assumption – planet is irradiated from one side only. The hot and cold sides will never become identical.
“Heat transfer to and from a planet is governed by the Stefan- Boltzmann equation, which is non-linear.”
Also
“Heat is a transfer of molecular kinetic energy”.
Since almost the entire incident solar flux’s EM energy on the instant is “sent” out (in form of reflection – SW EM specular and diffuse- and in form of IR EM emission) there is only a very small portion left to be transferred in the inner layers as molecular kinetic energy.
That is why we cannot average solar flux over the whole planet surface area. Flux is not heat.
Conclusion:
There is not any 240 W/m² outgoing IR EM emission.
https://www.cristos-vournas.com
If the planet isn’t rotating, you have solar radiation concentrated on one area all the time. As soon as the planet starts rotating, the planet’s solar radiation spends less time on that area and more on the rest of the planet. Start accelerating the rotation of the planet and less and less time is spent on that area and more and more time on the rest of the planet. Eventually, the solar radiation, for all practical purposes, is being distributed evenly and the surface temperature becomes uniform.
What rotating the planet does is distribute solar energy more evenly. It doesn’t cause the planet’s temperature to rise. I told another poster that moving energy around on the planet doesn’t change the temperature of the planet. Moving solar energy around doesn’t change it either.
The only reason I didn’t dismiss your theory out of hand is because of the non-linearity of the SB equation. It’s possible that could have had an impact. It turns out it didn’t and that disproves your theory.
Even if your theory is correct, at steady-state — meaning constant rotational velocity –, it’s 240 w/m2 in and out. If it wasn’t, the planet would just keep getting hotter and hotter. Of course there is 240 w/m2 of outgoing IR radiation. The 240 w/m2 of incoming solar radiation includes a correction for reflection.
Of course you can average out solar flux across a planet. The planet radiates IR over it’s entire surface — though at different rates. It’s an abstraction for convenience. Lighten up!
None of what you said is going to save you planet rotation theory.
Please visit now:
https://www.cristos-vournas.com/445498727
Your equation is wrong because the spin of the planet has zero effect on planetary temperature.
When someone proposes an alternate theory of climate change, unless it doesn’t pass the laugh test, I give it the benefit of the doubt, and then I analyze it. The planet rotation theory was unlikely to be true, but I couldn’t dismiss it out of hand, and I analyzed it and found it to be false. Now that I have done that, I can pontificate on why it is wrong. Some clueless blowhards go right to pontificating before doing the work.
Let start with greenhouse gases. How does that work? Look at it from the standpoint of the earth. The earth is absorbing solar radiation and emitting IR to maintain an energy balance. Greenhouse gases are introduced. Now the earth has additional radiation it has to absorb. It absorbs it, but the planet is not in energy balance. The earth accumulates energy that raises its temperature until it is back in energy balance. Notice the solar radiation to the planet didn’t change. The earth got a permanent new energy source that increased its energy. It doesn’t matter that it is recycled energy from the earth’s IR.
Compare that to the planet spin theory. Rotation increases the amount of energy the hot side receives from the sun and increases the amount of energy that the planet radiates to space on the cold side BY THE SAME AMOUNT. That occurs almost instantaneously because as the cold side is exposed to the sun, the hot side is exposed to space. There is no change in the earth’s energy balance at any point, and it can’t accumulate energy; therefore, its temperature can’t change. You did not realize it’s energy change that affects the earth’s temperature — not surface temperature changes.
As climate denial junk science goes, your theory is really good — up there with the saturation theory. It’s elaborate, and it has some scientific basis. It has no chance of being accepted by the scientific community. The climate denial idiots will lap it up, and you could make serious money marketing it to them.
Willie Soon became a multimillionaire peddling solar flares and sunspots. He is still around giving seminars. Anything is possible if you’re willing to sell your soul.
JJBraccili
“Of course you can average out solar flux across a planet. The planet radiates IR over it’s entire surface — though at different rates. It’s an abstraction for convenience. Lighten up!”
The abstraction: Te = 255 K
The convenience: CO₂ 0,04% content in Earth’s very thin atmosphere – 288K – 255K= +33C.
The convenience’s result is “+33C” Greenhouse Effect from Earth’s very thin atmosphere.
YOU: “The planet radiates IR over it’s entire surface — though at different rates.”
It is the confirmation of the Newly discovered “Planet Surface Rotational Warming Phenomenon”.
Thank you!
https://www.cristos-vournas.com
“The abstraction: Te = 255 K
The convenience: CO₂ 0,04% content in Earth’s very thin atmosphere – 288K – 255K= +33C.
The convenience’s result is “+33C” Greenhouse Effect from Earth’s very thin atmosphere.”
One of the first questions I had to answer when discussing climate change was: “How can CO2 at 400 ppm have an impact on climate?”. The reason is that the greenhouse effect depends on absolute concentration — not relative concentration. I had to answer this questions so many times I developed a standard response:
“When you talk about CO2 having a ppm level, that’s a relative number. It depends on the other gases in the atmosphere. Take away all the other gases, and the CO2 is at 1 million ppm. It doesn’t matter how much CO2 is there. It could be one molecule of CO2, and the concentration is still 1 million ppm.
Take a transparent empty box, and put some CO2 in it, and shine a fixed-rate full spectrum of infrared radiation through the box. Some photons will hit CO2 molecules, and if they are of the right wavelength, they will be absorbed, and less radiation will be measured leaving the box. Double the amount of CO2 in the box, and even less radiation will leave the box. All while the concentration of CO2 remains at 1 million ppm.
Now add an equal number of N2 molecules to the box. The concentration of CO2 is 500,000 ppm. The CO2 molecules still roam the same volume. N2 does not absorb radiation in the CO2 absorption band. Photons in the CO2 absorption band pass right through N2 like it wasn’t there. The odds of the right photon hitting a CO2 molecule is the same. There is no change in the amount of radiation leaving the box even though the concentration is half.
The magnitude of CO2 ppm doesn’t correlate with CO2’s greenhouse effect. When you say that the planet was cooling when CO2 ppm is 10Xs today’s ppm, that’s not a valid argument. Something other than CO2 could be controlling the climate, or there may be less of the other atmospheric gases, so that ppm seems high, but it could have the same or even less of a greenhouse effect.
A perfect example is a comparison between the planets Venus and Mars. Both have CO2 concentrations > 95%. The temperature on Venus is 460 deg C. The temperature on Mars is -63 deg C. CO2 has a large impact on the temperature of Venus and little effect on the temperature on Mars. Why? The pressure on Venus is 90 atm, and the pressure on Mars is 0.006 atm. The amount of CO2 in the atmosphere of Venus is orders of magnitude greater than the amount of CO2 in the atmosphere of Mars. That’s why the difference.
Another example is to imagine the earth’s atmosphere as 100 molecules of CO2. The atmospheric concentration of CO2 is 1 MM ppm or 100% CO2. What would be the greenhouse effect? Virtually nothing.
What we should be doing is using molecules/volume or molar density to correlate the greenhouse effect. We are stuck with ppm because it is easy to measure. So why does the greenhouse effect increase with ppm? It doesn’t correlate with the actual value of ppm. It correlates with the change in ppm. If you add CO2 to the atmosphere, gravity keeps the CO2 close to the earth. You’re adding CO2 and increasing the molar density. Gravity doesn’t totally maintain the volume, and there is some increase in the “height of CO2 in the atmosphere. That increases the odds that a photon will hit a CO2 molecule. That means CO2 absorbs more photons, and molar density is not a perfect measure of the greenhouse effect but is infinitely better than ppm.”
“YOU: “The planet radiates IR over it’s entire surface — though at different rates.”
It is the confirmation of the Newly discovered “Planet Surface Rotational Warming Phenomenon”.
Thank you!”
Not really! The only thing “newly discovered” is that the “Planet Surface Rotational Warming Phenomenon” is junk science. Your own example proves it.
If you want to redeem your theory, you must show how rotating a planet produces a new, permanent source of energy that can drive the planet’s temperature higher and hold it at that temperature. Without that, you did a lot of work for nothing.
JJBraccili
“take a transparent empty box, and put some CO2 in it, and shine a fixed-rate full spectrum of infrared radiation through the box. Some photons will hit CO2 molecules, and if they are of the right wavelength, they will be absorbed, and less radiation will be measured leaving the box. Double the amount of CO2 in the box, and even less radiation will leave the box. All while the concentration of CO2 remains at 1 million ppm.”
No, this is not right.
No, you are wrong.
Learn something, if that’s possible.
https://en.wikipedia.org/wiki/Beer%E2%80%93Lambert_law
Click on concentration link and you’ll find out the equation uses molar density.
I suspect you’ll spend the rest of the day trying to come up with an idiotic point to “prove” you’re right. Happy hunting.
JJBraccili
“If you add CO2 to the atmosphere, gravity keeps the CO2 close to the earth. You’re adding CO2 and increasing the molar density. Gravity doesn’t totally maintain the volume, and there is some increase in the “height of CO2 in the atmosphere. That increases the odds that a photon will hit a CO2 molecule. ”
No, this is not right, either.
Look at the target from above.
There is a molecular density below regardless of height.
Height does not change the odds.
Wrong again — as usual.
Composition of the atmosphere doesn’t change much with altitude. density and molar density do.
https://scied.ucar.edu/learning-zone/atmosphere/change-atmosphere-altitude
There’s a true false-test in the link. Why don’t you take it? I suggest you try flipping a coin. If you answer with your “vast” knowledge of science, you won’t get one question right.
JJBraccili
“A perfect example is a comparison between the planets Venus and Mars. Both have CO2 concentrations > 95%. The temperature on Venus is 460 deg C. The temperature on Mars is -63 deg C. CO2 has a large impact on the temperature of Venus and little effect on the temperature on Mars. Why? The pressure on Venus is 90 atm, and the pressure on Mars is 0.006 atm. The amount of CO2 in the atmosphere of Venus is orders of magnitude greater than the amount of CO2 in the atmosphere of Mars. That’s why the difference.”
“…The pressure on Venus is 90 atm, and the pressure on Mars is 0.006 atm.”
It is not only the CO₂% content in the Earth’s atmosphere general content that matters, but we have also to consider how many CO₂ molecules are in Earth’s atmosphere in total.
If Earth’s atmosphere was consisted from the actually existing CO₂ molecules only, the atmospheric pressure on the Earth’s surface would have been 0,0004 atm.
https://www.cristos-vournas.com
“It is not only the CO₂% content in the Earth’s atmosphere general content that matters, but we have also to consider how many CO₂ molecules are in Earth’s atmosphere in total.
If Earth’s atmosphere was consisted from the actually existing CO₂ molecules only, the atmospheric pressure on the Earth’s surface would have been 0,0004 atm.”
You missed the whole point of my example. What did I say? I said that the CO2 affect depends on ABSOLUTE concentration — not relative concentration.
Let’s take an example. Let’s take a planet and let’s assume it has an atmosphere which is 100% or 1 MM ppm CO2. It has X molecules of CO2 in the atmosphere. Now let’s start adding N2 to the atmosphere. Keep adding N2 in the atmosphere until the relative concentration of CO2 in that atmosphere is 400 ppm. Has the number of molecules in that atmosphere changed? NO! Has the greenhouse effect changed? NO!
Talking about ppm or % concentration of CO2 is meaningless. The only reason CO2 ppm correlates to the greenhouse affect is if we add or subtract CO2 to the atmosphere, it changes CO2 ppm providing there is no change in the quantity of the other gases in the atmosphere. The change is important. The magnitude of the number is not.
“…The pressure on Venus is 90 atm, and the pressure on Mars is 0.006 atm.”
It is not only the CO₂% content in the Earth’s atmosphere general content that matters, but we have also to consider how many CO₂ molecules are in Earth’s atmosphere in total.
If Earth’s atmosphere was consisted from the actually existing CO₂ molecules only, the atmospheric pressure on the Earth’s surface would have been 0,0004 atm.
Thus we have 15 times less CO2 molecules per earth’s square meter than Mars has.
https://www.cristos-vournas.com
“…The pressure on Venus is 90 atm, and the pressure on Mars is 0.006 atm.”
If Earth’s atmosphere was consisted from the actually existing CO₂ molecules only, the atmospheric pressure on the Earth’s surface would have been 0,0004 atm.
Thus we have 15 times less CO2 molecules per earth’s square meter than Mars has.
https://www.cristos-vournas.com
You still don’t get it!
The pressure of the atmosphere is determined by the mass of all the gases in the atmosphere. That has NO impact on the greenhouse affect. All that matters is the amount of CO2 in the atmosphere.
If I took Venus and added enough N2 to bring the ppm of CO2 to 400 ppm, the pressure would go up astronomically. the greenhouse affect would be the same. The affect only depends on the amount of CO2 there. I take that back. The higher pressure would increase the mole/liter of CO2. In that extreme case, it would have some impact in some situations. In the case of Venus the affect is saturated at the current pressure. Increasing the moles/liter by adding CO2 or increasing the pressure would have no impact.
Because of gravity, the relevant number is mole/liter of CO2 in the atmosphere — not moles/ft2 of surface area. What does that even mean?
You have a proclivity to pretend irrelevant numbers are important. I can see how you came up with your planet rotation theory, but it’s still wrong.
we have 15 times less CO2 molecules per earth’s square meter than Mars has.
https://www.cristos-vournas.com
“we have 15 times less CO2 molecules per earth’s square meter than Mars has.”
Your comparison is apples and oranges. Mars is a much smaller planet than the earth with 1/3 the gravity and 1/3 the surface area of the earth.
On Mars you have a high concentration of CO2 >95%. Double the amount of CO2 on Mars and you get almost double the atmospheric pressure. That means the partial pressure remains relatively constant with the actual amount of CO2 in the atmosphere. On the Earth you have a very low concentration of CO2 << 1%. Double the amount of CO2 on the Earth results in a big change in partial pressure.
The partial pressure of CO2 on Mars cannot be compared to the partial pressure of CO2 on the Earth. The partial pressure of CO2 on Mars is about the same no matter how much CO2 is in the atmosphere.
I didn’t say that right.
I need to think about that some more, and I’ll get back to you.
I’ve been busy on a couple of projects today. I rushed my last post, and when I reread it, I realized that it made no sense. Please disregard.
I think the point you are trying to make is that if the number of molecules of CO2 in the Earth’s atmosphere is < than the number of molecules in the Martian atmosphere, how could the greenhouse effect on the Earth be greater than the greenhouse effect on Mars?
Blackbody Temperature vs Observed Temperature C
Venus -41 vs 462
Earth -18 vs 15
Mars -64 vs -58
https://www.acs.org/content/acs/en/climatescience/energybalance/planetarytemperatures.html
One reason is that Mars is further from the Sun, although its albedo is less. The Earth's gravity is 3xs the gravity on Mars. That increases the molar density of CO2 and enhances its effectiveness. Neither of those is the main reason.
The principal reason is that CO2 is not the only greenhouse gas in the Earth's atmosphere. H2O is a about 4% of the Earth's atmosphere and is responsible for the bulk of the greenhouse effect.
https://www.nasa.gov/topics/earth/features/co2-temperature.html
According to NASA, CO2 is responsible for 20% of the greenhouse effect and H2O is responsible 75%. Even if the quantity of CO2 molecules in Earth's atmosphere is smaller than the quantity in the Martian atmosphere, CO2 is going to have an outsized impact because CO2 controls the amount of H2O in the atmosphere.
I don't know how many molecules of CO2 are in earth's atmosphere vs. Mars, and I don't care. It's an apples and oranges comparison.
JJBraccili, would you like please to estimate the CO2 partial pressure on Mars’ surface and the CO2 partial pressure on Earth’s surface?
https://www.cristos-vournas.com
I’ve been busy on a couple of projects today. I rushed my last post, and when I reread it, I realized that it made no sense. Please disregard.
I think the point you are trying to make is that if the number of molecules of CO2 in the Earth’s atmosphere is < than the number of molecules in the Martian atmosphere, how could the greenhouse effect on the Earth be greater than the greenhouse effect on Mars?
Blackbody Temperature vs Observed Temperature C
Venus -41 vs 462
Earth -18 vs 15
Mars -64 vs -58
https://www.acs.org/content/acs/en/climatescience/energybalance/planetarytemperatures.html
One reason is that Mars is further from the Sun, although its albedo is less. The Earth's gravity is 3xs the gravity on Mars. That increases the molar density of CO2 and enhances its effectiveness. Neither of those is the main reason.
The principal reason is that CO2 is not the only greenhouse gas in the Earth's atmosphere. H2O is a about 4% of the Earth's atmosphere and is responsible for the bulk of the greenhouse effect.
https://www.nasa.gov/topics/earth/features/co2-temperature.html
According to NASA, CO2 is responsible for 20% of the greenhouse effect and H2O is responsible 75%. Even if the quantity of CO2 molecules in Earth's atmosphere is smaller than the quantity in the Martian atmosphere, CO2 is going to have an outsized impact because CO2 controls the amount of H2O in the atmosphere.
I don't know how many molecules of CO2 are in earth's atmosphere vs. Mars, and I don't care. It's an apples and oranges comparison.
Ok.
Christos
I think that the most important outcome from this research is that it demonstrates that the behaviour of the climate system is very different for the cloud-free areas of the globe than it is for the cloudy areas of the globe.
Given that the cloudy areas account for about 2/3 of the Earth’s surface, this is very significant in terms of changes in concentrations of greenhouse gases. Many of the calculations of the effects of increasing concentrations of CO2 and other gases have been done for cloud-free conditions. Performing similar calculations for cloudy conditions is clearly a much more complex task.
“Many of the calculations of the effects of increasing concentrations of CO2 and other gases have been done for cloud-free conditions. ”
It is much worse actually. The surface heating, which they call Global Warming, is never really calculated from energy balance. They pretend that they you do but they do not. Most of calculations of CO2 (read original James Hansen’s paper, or “brilliant” delusion of Pierrehumbert in his book Principle of Planetary Climate) are actually relying on dry air adiabatic laps rate and the unsubstantiated claim that concentration of CO2 is somehow increases the altitude of the top boundary for this laps. And because they impose this lapse to be constant they get temperature increase at the surface. I’m not making it up. Just read their works or see Pierrehumbert’s interview in 2013.
It is particularly fascinating, as they should know that wet adiabatic lapse rate is slower, much slower. And wet adiabatic rate is what takes pace at tropics and sub-tropics, the part of the globe receiving most of the energy from the Sun per unit area. It is really fascinating how they managed to pull this trick and avoided being called out on this garbage and fake science.
A detailed critique of the AR6 WG1 SPM:
https://www.cfact.org/2021/10/28/clintel-catalogs-ipcc-errors-in-time-for-un-cop-26/
Here’s some info on CLINTEL
https://www.desmog.com/climate-intelligence-foundation-clintel/
Now that’s an organization that can give a fair and balanced assessment of climate science.
“800 “scientists, scholars, and professionals” that support CLINTEL have “conducted little to no climate research.”4 DeSmog analysis has found that the list of signatories includes a commercial fisherman, a retired chemist, a cardiologist, and an air-conditioning engineer, alongside a number of retired geologists.5”
It is typical of these climate denial organizations to claim a large number of supporters that have no background in climate science and try to make it appear like they do.
“Various members of CLINTEL’s list of ambassadors, and its extended list of signatories, have connections to libertarian free-market groups with a history of climate science denial, including the Heartland Institute, the Cato Institute, and the Competitive Enterprise Institute.7 All three organisations are members of the Koch-funded Atlas Network.8 9”
The Koch Brothers had to be involved in this somehow. They are one of the primary funders of climate denial junk science. They make a lot of money off of oil and gas.
The only name I recognize on their list of ambassadors is Richard Lindzen. He’s into climate denial for the money.
The group has connections to the Global Warming Policy Foundation and the Heartland Institute. Both are long time promoters of climate denial junk science.
The Heartland Institute, before they got into the business of promoting climate denial junk science, was funded by the tobacco industry to portray cigarettes as harmless. You can make a lot money in taking positions that protect industries that produce products that can kill people.
Thanks for the heads up David,
A detailed critique of Clintel’s erroneous Arctic sea ice assertions in their recent letter to Hoesung Lee:
https://twitter.com/GreatWhiteCon/status/1454410280662978563
“We are of the view that regrettably Clintel.org fails to meet adequate standards of objective scientific integrity and therefore will unfortunately misinform discussions in COP26 in Glasgow.“
I’m SHOCKED! SHOCKED!
Comparison of Te and Te.correct for planets Mars, Earth, Moon and Mercury
Φ = 0,47 is the for smooth without atmosphere planet surface solar irradiation accepting factor
Planet…Tsat.mean…..Te…..Te.correct
Mars …….210 K ….209,8 K …174 Κ
Earth…….288 K…….255 K……210 K
Moon…….220 K……270,4..K….224 K
Mercury….340 K……440 K……364 K
Let’s explain:
For Mars
Tsat.mean.mars = 210 K measured by satellites is almost equal with
Te.mars = 209,8 K (black-body equation calculated)
So scientist were led to mistaken conclusions.
First they assumed that the planet’s without-atmosphere effective and mean surface temperatures were equal, which is wrong.
Second, Earth’s effective temperature was calculated as
Te.earth = 255 K
The measured
Tmean.earth = 288 K.
So the difference of Δ 33oC was attributed to the Earth’s atmosphere greenhouse warming effect.
Now we have calculated Mars’ effective temperature as
Te.correct = 174 K
So the assumption that planet without-atmosphere mean surface temperature
Tmean = Te is wrong.
Mars’ Tsat.mean.mars = 210 K.
We can conclude now that Earth’s
Te.earth = 255 K is not equal with the Earth’s Tmean.earth.
The measured Tmean.earth = 288 K
and it is the Earth’s actual average (mean) surface temperature.
Thus the difference of 288 K – 255 K = Δ33 oC does not exist.
https://www.cristos-vournas.com
I hate to be a bearer of bad news, but your theory is junk science. You have to come up with a permanent energy source that varies with spin. It’s not the sun, I already showed why it can’t be.
Conclusions based on an equation based on junk science are worthless.
JJBraccili, it was you who in several priviest yours comments already expressed the right view that a planet surface different temperature distribution (due to the different rotational spin) leads to the changes in the planet surface mean temperature.
I think you agreed that a faster rotating planet (everything else equals) has a higher planet mean surface temperature.
Now you write:
“Conclusions based on an equation based on junk science are worthless.”
Please, explain.
https://www.cristos-vournas.com
I said it’s possible that a rotating planet could absorb more solar energy than a stationary planet. Then I went about trying to prove that true. My first calculation indicated a rotating planet had a small effect, but I screwed-up and the calculation was wrong.
For a planet’s temperature to change, it must move to a high energy state. The only way a planet can can absorb and retain energy is as it moves from one steady-state to another. At steady-state a planet cannot change its energy state.
For my second calculation I started with a non-rotating planet at steady state. In what follows all T’s are raised to the fourth power. Ts is the hot source temperature. Th is the planet hot side temperature. Tc is the planet cold side temperature.
The energy absorbed by the planet is k(Ts – Th).
The energy emitted by the planet is kTc.
At steady-state, k(Ts – Th) = kTc then, Tc = Ts – Th.
Next, put the planet into an unsteady-state by rotating the planet 180 degrees. The cold side now faces the sun and the hot side now faces space.
The energy absorbed by the planet is k(Ts – Tc)
Since Tc = Ts – Th, substitute and the energy absorbed becomes kTh
The energy emitted by the planet is kTh
Since the energy absorbed by the planet is equal to the energy emitted, the planet remains in steady-state and the planet rotation theory is disproven.
Unless you have another source of energy that varies with spin, you theory is nothing more than junk science.
This is a very simple problem that both those guys botch.
‘Visible light from the Sun carries energy to the planets in our solar system. That sunlight is absorbed by the planet’s surface, heating the ground. Any object with a temperature above absolute zero emits electromagnetic radiation. For planets, that outgoing EM radiation takes the form of infrared “light”. The planet will continue to warm until the outgoing infrared energy exactly balances the incoming energy from sunlight.
Scientists call this balance “thermal equilibrium”.’ https://scied.ucar.edu/earth-system/planetary-energy-balance-temperature-calculate
“This is a very simple problem that both those guys botch.”
They didn’t “botch” anything, but somebody has no idea what they are talking about.
What they are saying is that over the last 20 years the albedo (solar radiation reflection) has been falling due to less cloud cover. The data is not adequate to evaluate that assertion.
Well, at least you got what you said right. That a step forward — baby steps. Oh! I just noticed, it’s cut and paste. Maybe, not.
Robert
“The planet will continue to warm until the outgoing infrared energy exactly balances the incoming energy from sunlight.”
Planets in our solar system had been “warmed” 4,5 billions years ago, they do not continue to warm, planets gradually cool since.
It is the planet surface average temperature that varies in time…
https://www.cristos-vournas.com
“Planets in our solar system had been “warmed” 4,5 billions years ago, they do not continue to warm, planets gradually cool since.
It is the planet surface average temperature that varies in time…”
That says it all.
If the average surface temperature is higher than the temperature of the planet, heat is transferred from the surface to the planet.
If a planet was cooling for 4.5 billion years, I think it is safe to assume it would be near absolute zero.
The high school maths and physics from UCAR is not JJ’s. Christos resolutely resists the idea of thermal equilibrium.
You gave an answer that had nothing to do with the problem. Then you questioned the competency of the authors.
I guess in your fantasy world, it all make sense.
The answer I gave was that the planet warms to a temperature at which there is thermal equilibrium. Regardless of spin. It remains an elementary problem.
You’re losing it!
The post you replied to was about a decreasing albedo effect with increasing
atmospheric temperature. Your reply never addressed it.
JJ has never had it. My comment at the top of this thread was not about cloud. But about the longwinded and very tedious discussion between JJ and Christos on the planetary rotisserie effect. Both of whom get elementary physics wrong. We can find much better maths an physics on the UCAR K12 page I linked to.
But the CERES and Argo data are pretty convincing. Let’s see what JJ makes of this.
https://agupubs.onlinelibrary.wiley.com/cms/asset/55b43d02-c826-491b-9473-db94fd9b4d8f/grl62546-fig-0001-m.png
https://agupubs.onlinelibrary.wiley.com/doi/10.1029/2021GL093047
Then you replied to the wrong post. Your post was to the paper that was the base of this thread.
The only thing your graph proves is that there is an energy imbalance at TOA. Something is causing that imbalance, but it doesn’t say what is causing it. It could be planetary rotation, greenhouse gases, or little green men firing an energy ray at the earth. Maybe, your superior intellect can see through fog of complexity and divine the true source. Nah, that’s not it.
I thought that discussion we had about greenhouse gases and radiation at TOA would have taught you something. I guess your not bright enough to understand the point I was making.
My comment to which JJ responds was a stand alone comment. But I certainly have commented on CERES data. The Loeb et al paper linked under the graph taken from it discusses causes. That JJ doesn’t get it – doesn’t even read it – was expected.
He gets K12 physics wrong and imagines he is worth learning from.
A standalone comment? Then why are you replying to me? Standalone comments either go in a separate thread or you reply to the first post.
If you replied to the first post, you are still wrong with a comment that had nothing to do with the first post. If you were replying to my debate with CV, you are still wrong with a comment that had nothing to do with our debate. If you weren’t replying to either, congratulations, you can cut and paste. You learned that in kindergarten and its been downhill ever since.
Nobody can be this dumb. You are the exception.
I started a new thread commenting on how they botched a simple K12 level physics problem. The UCAR link provided the correct maths and physics. I have not a clue what this twit is now on about and less interest.
JJBraccili,
What changes with the faster rotation is the planet surface sunlit hemisphere IR emission ratio
“A planet from rotating faster is getting energy from nowhere.”
Yes, the faster rotation does not provide any additional incident SW radiative solar energy. No matter how slow or fast a planet rotates the incident on the planet’s surface solar energy is always the same.
What changes with the faster rotation is the planet surface sunlit hemisphere IR emission ratio.
There is the Planet Surface Rotational Warming Phenomenon.
Lets consider two identical planets F and S at the same distance from the sun. Let’s assume the planet F spins on its axis Faster, and the planet S spins on its axis Slower. Both planets F and S get the same intensity solar flux on their sunlit hemispheres. Consequently both planets receive the same exactly amount of solar radiative energy.
The slower rotating planet’s S sunlit hemisphere surface gets warmed at higher temperatures than the faster rotating planet’s F sunlit hemisphere.
The surfaces emit at σT⁴ intensity.
Thus at every given moment the planet S sunlit surface emits IR outgoing radiative energy more intensively from the sunlit side than the planet F.
So there is more energy every given moment left for the planet F to accumulate for the night then. That is what makes the faster rotating planet F on the average a warmer planet. That is how the Planet Surface Rotational Warming Phenomenon occurs.
https://www.cristos-vournas.com
You forgot something. A rotating planet will absorb more energy on the sunlit side that a non-rotating planet. It will also emit more energy on the non-sunlit side.
Look at my calculation. When I rotated the planet, it absorbed more energy on the sunlit side and emitted more energy on the non-sunlit side. The amount of energy absorbed and emitted was identical. That was because of the relationship between the hot side and cold side temperatures due to energy balance.
I think I’ll call what I just said the Non-Sunlit Hemisphere IR Emission Ratio. Catchy, don’t you think?
Your explanation explains NOTHING! Your “theory” doesn’t work.
JJBraccili
“Look at my calculation. When I rotated the planet, it absorbed more energy on the sunlit side and emitted more energy on the non-sunlit side. The amount of energy absorbed and emitted was identical. That was because of the relationship between the hot side and cold side temperatures due to energy balance.”
You say: “When I rotated the planet, it absorbed more energy on the sunlit side and emitted more energy on the non-sunlit side.”
JJBraccili, planet rotates all the time. What we do is to compare identical planets rotating with different rotational spin.
https://www.cristos-vournas.com
“JJBraccili, planet rotates all the time. What we do is to compare identical planets rotating with different rotational spin.”
Just STOP! You have no answer for what I said.
How are you going to compare identical planets rotating with different rotational spin? With your equation of course, which is based on your theory, which is wrong. Of course, if your equation doesn’t work, you’ll find an excuse why. Planet rotation has ZERO impact on planetary temperature.
Your theory was never going to refute the greenhouse gas theory. Climate scientists have 40 years of data that they used statistical analysis, regression analysis, etc. on, that tells them what is causing climate change. Here you come with a theory and equation that I can’t figure out where it came from, with constants that you can’t explain, that you claim fits the temperature of several planets, and now you think you’ve disproven climate science? That’s fantasy — not reality.
JJBraccili, it is getting late in Athens, Greece where I am.
Shall we continue tomorrow.
Also I have posted earlier today
https://judithcurry.com/2021/10/22/challenges-of-the-clean-energy-transition/#comment-963034
JJBraccili
“How are you going to compare identical planets rotating with different rotational spin? With your equation of course, which is based on your theory, which is wrong. Of course, if your equation doesn’t work, you’ll find an excuse why. Planet rotation has ZERO impact on planetary temperature.”
JJBraccili, I will continue with two identical planets rotating with different rotational spin.
Very interesting !
Mars and Moon satellite measured mean surface temperatures comparison:
210 K and 220 K
Let’s see what we have here:
Planet or…….Tsat.mean
moon………… measured
Mercury…………340 K
Earth……………..288 K
Moon…………….220 Κ
Mars……………..210 K
Mars and Moon have two major differences which equate each other:
The first major difference is the distance from the sun both Mars and Moon have.
Moon is at R = 1 AU distance from the sun and the solar flux on the top is So = 1.361 W/m² ( it is called the Solar constant).
Mars is at 1,524 AU distance from the sun and the solar flux on the top is S = So*(1/R²) = So*(1/1,524²) = So*1/2,32 .
(1/R²) = (1/1,524²) = 1/2,32
Mars has 2,32 times less solar irradiation intensity than Earth and Moon have.
Consequently the solar flux on the Mar’s top is 2,32 times weaker than that on the Moon.
The second major difference is the sidereal rotation period both Mars and Moon have.
Moon performs 1 rotation every 29,531 earth days (the lunar diurnal cycle period)
Mars performs 1 rotation every 24,622 hours or 0,9747 rot /day.
Consequently Mars rotates 29,531 *0,9747 = 28,783 times faster than Moon.
So Mars is irradiated 2,32 times weaker, but Mars rotates 28,783 times faster.
And… for the same albedo, Mars and Moon would have the same satellite measured mean temperatures.
Let’s make simple calculations:
The rotation difference’s fourth root is
(28,783)¹∕ ⁴ = 2,3162
And the irradiating /rotating comparison
2,32 /(28,783)¹∕ ⁴ = 2,32 /2,3162 = 1,001625
It differs only 0,1625%
It is obvious now, the Mars’ 28,783 times faster rotation equates the Moon’s 2,32 times higher solar irradiation.
That is why the 28,783 times faster rotating Mars has almost the same satellite measured mean surface temperature as the 2,32 times stronger solar irradiated Moon.
Thus we are coming here again to the same conclusion:
THE FASTER A PLANET ROTATES, THE HIGHER IS THE PLANET’S MEAN SURFACE TEMPERATURE
If Moon and Mars were the same distance from the sun, the faster rotating Mars would have been a warmer planet.
Earth and Moon are at the same distance from the sun. The faster rotating Earth is warmer than Moon.
This very important conclusion is based on satellite measured planets mean surface temperatures. It is based on the very reliable observations.
And it is the confirmation that the planet axial spin (rotations per day) “N” should be considered in the fourth root in the ( Tmean ) planet mean surface temperature equation:
Tmean.planet = [ Φ (1-a) So (1/R²) (β*N*cp)¹∕ ⁴ /4σ ]¹∕ ⁴.
https://www.cristos-vournas.com
“THE FASTER A PLANET ROTATES, THE HIGHER IS THE PLANET’S MEAN SURFACE TEMPERATURE”
The average surface temperature doesn’t change with rotational speed. It’s equal to the planet average radiating temperature. It’s also equal to the planetary temperature at steady-state. As the planet rotates faster and faster, the surface temperature becomes uniform as solar radiation is spread more evenly, and approaches the radiating temperature.
You keep trying to sell that the energy absorbed by a planet is a function of its rotational speed. It isn’t. I already proved that. There is no energy to drive planetary temperatures higher. The planetary spin theory is junk science.
Why did you raise the rotation to the 1/4 power? You gave no reason.
Mars has a CO2 atmosphere. The greenhouse effect raises the temperature of Mars by 5-8 C.
There is no agreed upon average temperature of the moon. I looked and it’s all over the place. If you calculate it the way we usually do, the temperature would be the same as the earth without an atmosphere — 255 K.
was only vaguely following your discussion. Do you have an explanation on why temperature is constant at 240K from below 0.3m of Moon’s surface at equator?
Solar input and lunar day/night variations can explain temperature dynamics at the surface. E.g. heat storage in thermal mass of regolith during the day and heat loss during the night. However all tis cannot explain the base 240K below the surface.
Can it be the residual heat from the time Moon was formed? Or is it similar to gravitational stress, similar to stress on Io (Jupiter’s moon), which can reach 1200C inside?
Hi Dmitry.
The constant at 240K from below 0.3m of Moon’s surface at equator is an observation. It confirms on of the thesis’ of “Planet Rotational Warming Phenomenon’s” theoretical approach.
It states that solar EM energy, when interacting with planet surface does the following:
1). Gets partially reflected (specularly and diffusely).
2). Gets on the very instant transformed into IR outgoing EM emission energy.
3). Only a very small portion of the incident solar flux’s EM energy is entering the surface’s inner layers in form of heat.
During the Moon’s long diurnal cycle’s 29,53 earthen days, solar energy, nevertheless, “penetrates” with cyclical temperature variation only a small 0.3 m of Moon’s surface at the equator.
https://www.cristos-vournas.com
Moon regolith has an extremely low thermal conductivity few mW/mK. So both heat from the Sun during the lunar day and radiant cooling during lunar night will not affect the layer below 0.3m. So heat that is present at lower depths has to come from another source. At least, this is what I see using order of magnitude estimations
Similar to the earth, the moon has a molten core. Temperature is around 1500 C. Maybe, that helps explain it.
One more thing.
I’ve never seen it mentioned anywhere, but I see no reason why there wouldn’t be decaying radioactive material on the moon. That’s means geothermal energy.
“One more thing.
I’ve never seen it mentioned anywhere, but I see no reason why there wouldn’t be decaying radioactive material on the moon. That’s means geothermal energy.”
That means that you missed my heated debate with David Appell ;))). I was suggesting radiative decay as a possible source.
https://judithcurry.com/2021/10/22/challenges-of-the-clean-energy-transition/#comment-962567
But I really start to think that gravity from Earth should have similar effect as gravity from Jupiter of Io. Just smaller magnitude, that is why it is only 240K and not 1200C. There is really no reason of why similar phenomenon would not take place.
“Moon regolith has an extremely low thermal conductivity few mW/mK. ”
Maybe this explains it. Maybe the heat was “always” there. The “solar irradiation/ lunar surface” interaction has stopped the lunar surface cooling on equator at 0.3 m and at some certain temperature, 240K.
https://www.cristos-vournas.com
JJBraccili
“Here you come with a theory and equation that I can’t figure out where it came from, with constants that you can’t explain, that you claim fits the temperature of several planets, and now you think you’ve disproven climate science? That’s fantasy — not reality.”
I agree, at first it looks like a fantasy… It is so much different and unheard of.
JJBraccili, what I use as method I call “the Planets Surface Temperatures Comparison Method”. I have spotted not one, but two New (previously not known) phenomena.
1). The smooth planet surface specular reflection. Thus the “Φ = 0,47” factor in the New equation.
2). The “Planet Rotational Warming Phenomenon”. It is where the “β = 150 ” Universal constant comes from.
https://www.cristos-vournas.com
It seems like fantasy because it is fantasy.
I was wondering why you took SB equation and took the 1/4 root. It had to do with the moon, didn’t it? The moon is an odd duck. It rotates very slowly.
Then you add a couple of constants that you can’t explain, and give them a name making it appear they are legitimate. By adjusting the constants in ways you can’t explain, you have a theory that fits the data of several planets and accounts for the earth’s 33 K temperature discrepancy. You can’t account for the energy required to cause this change, and you can’t account for the earth’s current temperature rise. You make up stuff as you go along. This isn’t even good science fiction.
Good
At this point, you can’t tell if the effect of temperature rise lowers the albedo. The data isn’t good enough. Hard to believe that putting more water vapor in the atmosphere causes less clouds, but I’m sure someone will come up with some place in the world were cloud cover has receded over the past few years. That’s not proof — that’s an anomaly.
I’ve been answering your posts, but for some reason not all get distributed. BTW your “theory” is still junk science. At this point, you’re grasping for straws.
JJBraccili
“I was wondering why you took SB equation and took the 1/4 root. It had to do with the moon, didn’t it? The moon is an odd duck. It rotates very slowly.
Then you add a couple of constants that you can’t explain, and give them a name making it appear they are legitimate. By adjusting the constants in ways you can’t explain, you have a theory that fits the data of several planets and accounts for the earth’s 33 K temperature discrepancy.”
JJBraccili, Ok
Let’s see what you mean:
Here is the classical planet effective temperature eqn.
Te = [ (1-a) S /4σ ]¹∕ ⁴ (K)
And here is the New eqn.
Tmean.planet = [ Φ (1-a) S (β*N*cp)¹∕ ⁴ /4σ ]¹∕ ⁴ (K)
it can be rewritten as:
Tmean.planet = [ Φ*(β*N*cp)¹∕ ⁴]¹∕ ⁴ [ (1-a) S /4σ ]¹∕ ⁴ (K)
or
Tmean.planet = Te * Φ¹∕ ⁴(β*N*cp)^1/16 (K)
*******
Let’s follow your logic now. You think I took the satellite measured Tsat the planets’ mean surface temperatures and then I “constructed” a New eqn.
Tsat = Te * Φ¹∕ ⁴(β*N*cp)^1/16 (K) = Tmean.planet
Ok, but how? How it is possible to fit the parameters for all planets and moons without-atmosphere in solar system? Unless there are some observed relations?
We know for planets and moons the: S, a, Tsat, Te, N, cp.
How one can fit for all planets and moons
the Tsat with Te , having for every planet and moon a different N and a different cp ?
Now that the New equation is present (and working) it seems to you easy…
But please, what would be your steps to fit Tsat with Te for 14 different celestial bodies?
Here is the classical planet effective temperature eqn.
Te = [ (1-a) S /4σ ]¹∕ ⁴ (K)
Now, JJBraccili, start fitting…
Maybe you will find a different equation, maybe a better fitting one?
https://www.cristos-vournas.com
The “classical” equation was derived from Planck’s equation which was developed to explain blackbody radiation. Your equation fell off a turnip truck for all I know.
What you did is force a relationship where there isn’t one.
Look at the “cloud” theory. That’s based on some data that shows reflected SW radiation declining over time. Where those numbers “cherry-picked”? Where did the cloud data come from? Since water vapor increases with temperature, it seems unlikely that cloud cover decreases with temperature. One of the authors of that article has been involved in climate denial junk science before. It’s likely the theory is junk science.
Then there is the small problem of 40 years of data taken and evaluated by experts in the field that point to greenhouse gases as the source of the warming. You want to tell me it’s all a hoax? That thousands of scientists around the world of different generations, political systems, and cultures somehow came to together to perpetrate the greatest con ever? To what end? Please!
JJBraccili,
“What you did is force a relationship where there isn’t one.”
How? But how can one force a relationship where there isn’t one?
https://www.cristos-vournas.com
Actually, it’s quite easy. Let’s say you had some data that indicated, corrected for solar insolation, planet temperature varied with planet size. You make the assumption that there is a relationship between planet size and planet temperature. Now it’s just a matter of coming up with an equation with enough variables and constants that fits the data. Solar insolation and size have to be in the equation. Everything else is up to your imagination. Any thing that doesn’t fit the “equation”, you find a way to explain away.
The problem is the assumption that planet temperature varies with planet size. Exactly like your assumption that planet temperature varies with planet rotation. You have no actual data the confirms your assumption. By that I mean an experiment with a rotating sphere in a vacuum exposed to sunlight or some other SW source where you measure the sphere’s temperature as its rotation rate is varied.
Do you understand the problem with what you did?
Braccili
“like your assumption that planet temperature varies with planet rotation. You have no actual data the confirms your assumption. By that I mean an experiment with a rotating sphere in a vacuum exposed to sunlight or some other SW source where you measure the sphere’s temperature as its rotation rate is varied.
Do you understand the problem with what you did?”
Braccili, the planet temperature varies with planet rotation. It is an observation.
There is no need in an experiment with a rotating sphere in a vacuum exposed to sunlight…
Here is the clear example:
Mars is irradiated 2,32times weaker than Moon, but Mars rotates 28,783 times faster.
And… for the same albedo, Mars and Moon would have the same satellite measured mean temperatures.
For Moon Tmean = 220K Moon’s Albedo a=0,11
For Mars Tmean= 210K Mars’ Albedo a=0,25
Let’s do a simple calculation:
The rotation difference’s fourth root is
(28,783)¹∕ ⁴ = 2,3162
Now, please compare these two numbers:
2,32 and 2,3162
They are very-very much close, they are almost identical!
That is why no experiment is needed. We have the Planet Surface Rotational Warming Phenomenon observed.
https://www.cristos-vournas.com
“the planet temperature varies with planet rotation. It is an observation.
There is no need in an experiment with a rotating sphere in a vacuum exposed to sunlight…”
Planet temperature varying with rotation is an OBSERVATION. That is why scientists would devise an experiment isolating rotation from all other factors that could affect planet temperature and determine if there IS a relationship between rotation and temperature. Did you do that? I’m pretty sure the answer is NO.
In your example you ASSUME there is a 1/4 power relationship between solar absorption and rotational speed. Where did that come from? Do you have a theoretical or experimental basis for that correction? Is it because it fits the data? Probably the latter. That proves NOTHING!
Braccili
“In your example you ASSUME there is a 1/4 power relationship between solar absorption and rotational speed.”
I never assumed that.
What I demonstrated above is that there is relationship planet rotational spin 1/16 power with Planet Mean Surface Temperature.
here is the New equation
Tmean.planet = [ Φ (1-a) S (β*N*cp)¹∕ ⁴ /4σ ]¹∕ ⁴ (K)
it can be rewritten as:
Tmean.planet = [ Φ*(β*N*cp)¹∕ ⁴]¹∕ ⁴ [ (1-a) S /4σ ]¹∕ ⁴ (K)
or
Tmean.planet = Te * Φ¹∕ ⁴(β*N*cp)^1/16 (K)
https://www.cristos-vournas.com
You used your equation which comes from your belief that planet rotation impacts planet temperature. Your equation is just a concoction that fits a limited data set.
You have a constant in your equation that you have explained 3 different ways. The last one equated to a drag coefficient. I have no idea what drag has to do with a planet without an atmosphere rotating in a vacuum.
On your website, you state that the constant has something to do with rough or smooth planets. What constitutes a rough or smooth planet? You don’t say. I guess this ties in with the drag coefficient? In your world, this all makes perfect sense. In the real world, where I live, not so much.
Here’s a kindred spirit:
“https://www.drroyspencer.com/2016/09/the-faster-a-planet-rotates-the-warmer-its-average-temperature/”
I wouldn’t get too excited. He made the same mistake you did. He thinks by averaging hot and cold temperatures and getting a difference with rotation means the temperature of the planet changes. He never looked at heat transfer or an energy balance. I posted to his site yesterday pointing out why he is wrong. I haven’t heard back.
Roy Spencer is a long time peddler of climate denial junk science. He’s actually done some good scientific work, but not in climate change. He and John Christy have published papers in respectable journals that cast doubt on climate science. Those papers have been revised too many times to mention. John Christy now claims CO2 is warming the planet, but only slightly.
Roy Spencer calls evolution junk science and believes the world is 6000 years old. Just saying.
JJBraccili,
Here is the classical planet effective temperature eqn.
Te = [ (1-a) S /4σ ]¹∕ ⁴ (K)
It calculates Earth’s Te = 255K
The measured Earth’s Tmean = 288K
Also it calculates Moon’s Te = 270 K
The measured Moon’s Tmean = 220K
Moon is lesser in size than Earth…
YOU:
“Actually, it’s quite easy. Let’s say you had some data that indicated, corrected for solar insolation, planet temperature varied with planet size. You make the assumption that there is a relationship between planet size and planet temperature. Now it’s just a matter of coming up with an equation with enough variables and constants that fits the data. Solar insolation and size have to be in the equation. Everything else is up to your imagination. Any thing that doesn’t fit the “equation”, you find a way to explain away.”
Please, continue, you made the assumption ” planet temperature varied with planet size.”
YOU: “Now it’s just a matter of coming up with an equation with enough variables and constants that fits the data. Solar insolation and size have to be in the equation. Everything else is up to your imagination. Any thing that doesn’t fit the “equation”, you find a way to explain away.”
Please, continue… Use your imagination.
https://www.cristos-vournas
I wasn’t claiming that size correlated to planet temperature. I’m pretty sure if I searched throughout the universe I could come up with an example where planets of different sizes had different temperatures that changed in a direction that appeared to correlate with size. Either increasing with temperature or decreasing with temperature. From there it wouldn’t be hard to come up with an equation that’s in line with my theory. That’s exactly what you did. That’s not proof of the theory.
If you really believe in this theory, then reach into your pocket and have some experiments done. If you don’t want to spend the money, find someone to fund it. Try one of the Koch Brothers’ organizations. Tell them you think you can prove Roy Spencer’s theory on planet rotation.
Until that happens, you have nothing. I’m certain, even after you ran the experiment, you’d find out that rotation has no impact on temperature, but, hey, go knock yourself out.
JJBraccili
“I posted to his site yesterday pointing out why he is wrong. I haven’t heard back.”
You posted in the 2016 page. It is natural you never heard back,,,
Try post in the latest page instead:
https://www.drroyspencer.com/2021/11/uah-global-temperature-update-for-october-20210-37-deg-c/
That’s a different topic. I’ll wait a few days and see what happens. If I don’t get a reply, I may try it.
If you scroll up there (2016) a little, you will find the previous my post there from Feb.1, 2021.
Still never heard back…
https://www.cristos-vournas.com
JJBraccili, thank you for your comments on my theory. It is a New science, based on known physics, scientists have to make some effort to focus on what I have discovered.
It is difficult to re-teach the well educated people – the old long established and becoming very dogmatic scientific views have been rooted in the collegial scientific thought.
When trying to tell children about my findings, they already know what their teacher told them.
There are very few people who have accepted my findings as a breakthrough in science.
People like you, who took a serious notice of what I am trying to explain are the Hope for the future.
It is very good to know that gradually the “Planet Rotational Warming Phenomenon” will become widely known and widely accepted.
Thank you JJBraccili for your participation in that difficult task.
https://www.cristos-vournas.com
Gaseous Planets Jupiter and Neptune T1bar mean temperatures 165 K, 72 K comparison
Jupiter’s atmosphere composition 89% ± 2,0% H₂, 10% ± 2,0% He, 0,3% ± 0,1% CH₄.
Neptune’s atmosphere composition 80% ± 3,2% H₂, 19% ± 3,2% He, 1,5% ± 0,5% CH₄.
As we can see, Jupiter and Neptune have close atmospheric compositions.
All data are satellites measurements.
R – semi-major axis in AU (Astronomical Units)
a – planet’s average albedo
N – rotations /day – planet’s spin
T1bar – planet atmosphere at 1 bar average temperature in Kelvin
Planet.…Jupiter….Neptune
R………….5,2044….30,33
1/R²…….0,0369……0,001087
a……………0,503….0,290
1-a………..0,497……0,710
N………….2,4181….1,4896 (rotations/day)
T 1 bar……165 K……72 K
Coeff…0,388880……0,170881
Comparison coefficient calculation
[ (1-a) (1/R²) (N)¹∕ ⁴ ]¹∕ ⁴
Jupiter
[ (1-a) (1/R²) (N)¹∕ ⁴ ]¹∕ ⁴ =
= [ 0,497*0,0369*(2,4181)¹∕ ⁴ ]¹∕ ⁴ =
= ( 0,497*0,0369*1,2470 ]¹∕ ⁴ = ( 0,0228691 )¹∕ ⁴ =
= 0,388880
Neptune
[ (1-a) (1/R²) (N)¹∕ ⁴ ]¹∕ ⁴ =
= [ 0,710*0,001087*(1,4896)¹∕ ⁴ ]¹∕ ⁴ =
= ( 0,710*0,001087*1,1048 )¹∕ ⁴ = ( 0,000852651 )¹∕ ⁴ =
= 0,170881
Let’s compare
Jupiter coeff. / Neptune coeff. =
= 0,388880 /0,170881 = 2,2757
T1bar.jupiter /T1bar.neptune = 165 /72 = 2,2917
Conclusion:
Gaseous Giants Jupiter and Neptune average T1bar temperatures relate (everything else equals) as their rotational spins (N) sixteenth root.
It is at 1bar layer the satellite measured average temperatures comparison.
The cp term for Gasses Giants is absent, because we do the comparison not for planets’ solid surfaces temperature, but for the layers with a close atmospheric composition at the same 1bar pressure.
Nevertheless the “Planet Rotational Warming Phenomenon” is present and observed…
https://www.cristos-vournas.com
Is that suppose to prove something?
You still have to answer some unresolved problems
1. Why did you use Cp in your equation. You last answer, to put it mildly, was less than satisfactory.
2. You didn’t handle water correctly which, I think, leads to a much lower temperature of the earth than your “equation” predicts.
3. Here’s another log you can throw on the fire. We all agree that the earth is absorbing and radiating 240 W/m2. From the S-B equation that corresponds to a 255 K temperature. You claim that planet rotation causes the earth’s temperature to be 288 K. That can’t be supported with a 240 W/m2 absorption-emission rate. Where does the extra energy come from? For greenhouse gases, that energy comes from back radiation.
JJBraccili
” We all agree that the earth is absorbing and radiating 240 W/m2.”
I never said I agree with that!
IT IS VERY MUCH WRONG!
https://www.cristos-vournas.com
Really?
I took this from the home page of your website:
S = 1361 W/m2
a = 0.306
Your “equation” corrects solar flux at TOA for albedo and the spherical shape of the earth that correction is
(1-a) S / 4
Plug the number in and you get 236 W/m2
You’re right! You didn’t say 240 W/m2. You said 236 W/m2. I stand corrected.
That means you have find even more energy to get the planet to 288 K than I originally thought. Good luck with that!
Try again!
JJBraccili
“…heat absorbed on the hot side = heat emitted on the cold side. The planet remains in energy balance and the temperature of the planet can not change.
As you rotate the planet, and an increment of cold side faces the sun, the same amount of hot side faces outer space. The planet remains in energy balance and no matter how fast you rotate the planet, its temperature will not change.”
“…and no matter how fast you rotate the planet, its temperature will not change.”
This part you wrong!
https://www.cristos-vournas.com
PROVE ME WRONG! Don’t even think about using your “equation”. It’s worthless.
JJBraccili
“Your “equation” corrects solar flux at TOA for albedo and the spherical shape of the earth that correction is
(1-a) S / 4”
No, it is not!
You are wrong! It is not the correction!
https://www.cristos-vournas.com
Here’s your “equation””
Tmean.planet = [ Φ (1-a) S (β*N*cp)¹∕ ⁴ /4σ ]¹∕ ⁴
Since you don’t seem to understand it, let me rearrange if it for you:
Tmean.planet = [ (Φ/σ)(β*N*cp)¹∕ ⁴ ((1-a) S/4) ]¹∕ ⁴
See?
Let’s go a little further to show how bad this equation is:
Tb = ((1-a) S/(4σ))¹∕ ⁴ where Tb is the blackbody temperature
Now replace the terms in your equation that calculate the blackbody temperature and your equation becomes:
Tmean.planet = [ ((Φ)(β*N*cp)¹∕ ⁴)]¹∕ ⁴Tb
What wrong with this picture? When the planet isn’t spinning the planet temperature is 0 — not Tb. You claim this equation works in all cases, but it doesn’t work when the planet isn’t spinning.
The form of the equation should be something like:
Tmean.planet = (1 + ((Φ)(β*N*cp)¹∕ ⁴)]¹∕ ⁴) Tb
It won’t be that, but it should look something like that. That way when spin is zero the planet temperature is Tb. What you have is not a theory but a limited curve fit.
The more I look at your “theory” and “equation” the worse it gets. You need to take this back to the drawing board or scrap it. I wouldn’t attach my name to it.
JJBraccili
“What you have is not a theory but a limited curve fit.”
JJBraccili,
Now you do the equation fitting…
“Tmean.planet = (1 + ((Φ)(β*N*cp)¹∕ ⁴)]¹∕ ⁴) Tb”
Maybe it would fit you better like this:
Tmean.planet = [(Φ)(β*(N+0,000001)*cp)¹∕ ⁴)]¹∕ ⁴Tb ?
Now when spin is zero the planet temperature is Tmean.
Would you, please, consider to attach your name to it now?
https://www.cristos-vournas.com
When the planet rotation is 0, Tmean has to equal Tb. You’re new “correction” still doesn’t do that. All it does is say Tmean is some fraction or multiple of Tb depending on the size of the other constants. You could mess with those, but that would mean your “universal constants” weren’t actually determinable constants — just fudge factors that you use to get the results you want. Maybe, you could come up with a new fudge factor that varies with spin so it cancel out the other constants at low speeds. You can call it the “This is a Joke Correction Factor.”
This is your theory. I think it’s complete BS. It your job to make sure your equation works — not mine. I’m not fitting anything to anything.
I wouldn’t attach my name to this hot mess — ever.
JJBraccili
“…and no matter how fast you rotate the planet, its temperature will not change.”
This part you wrong!
YOU:
“PROVE ME WRONG! Don’t even think about using your “equation”. It’s worthless.”
Let’s consider a rotating planet with spin n1 (it is a thought experiment, all right).
Tsolar1 = 200K and Tdark2 = 100K spin n1
Let’s rotate faster, n2>n1
The Tsolar2 = 199K,
What will be the Tdark2 = ?
https://www.cristos-vournas.com
Your problem is that you don’t listen. You want your “theory” to be true so bad, you make the same points over and over even though I have already discussed them.
You, once again, have presented an example problem I discussed previously as proof. I believe the answer to your question is Tdark2 =107. Next, you’ll make the argument that the “average” of the temperatures is higher than the planetary temperature; therefore, the temperature of the planet must be higher. As I explained before, you are being fooled by the non-linearity of the SB equation.
It’s irrelevant what surface temperatures do. The ONLY way a planet’s temperature rises is if it absorbs energy. The only way that happens is if there is an energy imbalance. My example shows that energy is always in balance as you change rotation rate. When the surface temperatures cause a planet to absorb more, it also emits more so that the planet remains in energy balance. Surface temperatures change, energy absorbed changes, and energy emitted changes, but the energy in always equals energy out. Therefore, no change in planetary temperature.
JJBraccili
” I believe the answer to your question is Tdark2 =107.”
So for n1 the Tmean = (200K +100K) /2 = 150K
And for n2>n1 the Tmean = (199+107) /2 = 153K
Doesn’t that clearly demonstrate the faster rotating planet (everything else equals) is on average warmer?
https://www.cristos-vournas.com
See also On Planet’s surface the energy Emission /Accumulation ratio:
https://www,cristos-vournas.com/446447956
I am sorry the Link in my website I provided doesn’t open.
You still can find and visit that subpage
“Jemit/Jabsorb ratio”
in my website starting from the “ROTATIONAL WARMING” page.
https://www.cristos-vournas.com
On your website, on the web page you recommended, this caught my eye:
“Consequently when rotating slower and having a lower cp the planet’s surface gets hotter and the planet’s surface emits more and accumulates less.”
Cp has no impact on surface temperature on a planet with a solid surface. Thermal conductivity does. A planet with a liquid surface, like the earth, is an entirely different animal.
No, it doesn’t. All that proves is that you get a non-linear temperature response from the S-B equation. The energy balance is not a function of rotation, and it stays in balance during any change in rotation. That’s what my example proved.
Obviously, you don’t understand that. Let me take another tack. You claim that planet rotation is responsible for the earth’s 33 C temperature rise, and the planet should be at 255 K, but it’s actually at 288 K.
The earth is currently absorbing and emitting about 240 W/m2 of radiant energy at TOA. According to S-B, the earth’s temperature should be 255 K. If the earth’s temperature is 288 K by the S-B equation, the absorption-emittance of radiant energy must be higher to support the higher temperature. Let’s say that number is 340 W/m2. Greenhouse gases get to that higher number by back radiation. The back radiation must be 100 W/m2. So the earth absorbs 240W/m2 from the sun + 100 W/m2 back radiation for 340 W/m2. At steady-state, the earth emits 340 W/m2, and the planet’s temperature is 288 K. The earth’s 340 W/m2 of radiant energy hit’s the atmosphere where the 100 W/m2 of back radiation is subtracted. At TOA, it’s 240 W/m2 in and 240 W/m2 out. Everything is in balance, and the S-B equation is satisfied.
According to your “theory,” there is no greenhouse effect because the atmosphere is too “thin.” That means no back radiation. That means the earth must absorb and emit 340 W/m2 to have a 288 K temperature caused by planet rotation. That means at TOA it must be 340 W/m2 absorbed by the earth from the sun and the same amount emitted by the planet as IR. The ONLY way that happens is when the earth is not rotating, it absorbs and emits 240 K W/m2 due to the higher temperatures on the hot side. The planet’s temperature would be 255 K. As the earth begins to rotate, it absorbs and emits more energy until at TOA, it absorbs 340 W/m2 from the sun and emits 340 W/m2 of IR. It’s not doing that — your theory doesn’t work.
Unless you have a different source of energy due to planet rotation, your theory doesn’t work, and that’s besides all the other things wrong with it.
JJBraccili
“You claim that planet rotation is responsible for the earth’s 33 C temperature rise, and the planet should be at 255 K, but it’s actually at 288 K.”
I never claimed that!
What I have discovered is a Planet mean surface temperature equation:
Tmean.planet = [ Φ (1-a) S (β*N*cp)¹∕ ⁴ /4σ ]¹∕ ⁴
The equation precisely calculates all planets and moons without-atmosphere in solar system the average (mean) surface temperatures.
For planet Earth without-atmosphere the calculated mean surface temperature is
Tmean.earth=288K
The planet blackbody equation (effective temperature):
Te = [ (1-a) S /4σ ]¹∕ ⁴
is a mathematical abstraction.
The number it calculates for earth’s effective temperature
Te=255K
is meaningless. The Te=255K cannot be compared with Earth’s actual mean surface temperature, because one cannot compare two different terms – a planet actual mean surface temperature Tmean.earth=288K with a mathematical abstraction Te=255K.
What I claim is that there is not +33oC greenhouse effect on Earth’s surface.
The difference of +33oC does not exist in the real world.
The Planet mean surface temperature equation:
Tmean.planet = [ Φ (1-a) S (β*N*cp)¹∕ ⁴ /4σ ]¹∕ ⁴
is based on the Stefan-Boltzmann emission law, but it is also based on the Planet Surface Rotational Warming Phenomenon.
Earth’s surface on average is much warmer than Moon’s. Yes, it is true. And the difference is due to Earth’s 29,53 higher rotational than Moon’s spin. Also Earth is covered with water, and where it is not covered with water it is wet (forests, glaciers, fields with crops, lands after rain, and vast snow covered areas).
Thus Earth’s cp =1 cal/gr.oC
Moon’s surface is dry regolith. Thus Moon’s cp =0,19cal/gr.oC.
Earth’s cp is five (5) times higher.
That is why earth’s mean surface temperature is Tmean.earth=288K
And Moon’s is
Tmean.moon=220K.
The difference 288K-220K=68oC is due to “Planet Surface Rotational Warming Phenomenon”.
It states:
Planets’ mean surface temperatures relate (everything else equals) as their (N*cp) products’ sixteenth root.
https://www.cristos-vournas.com
Let me get this straight. What you are now saying is that:
“The planet blackbody equation (effective temperature):
Te = [ (1-a) S /4σ ]¹∕ ⁴
is a mathematical abstraction.
The number it calculates for earth’s effective temperature
Te=255K
is meaningless.”
The S-B equation has been around for over 100 years and has been used whenever radiant energy is involved. It has been experimentally verified. It has been used to design countless of fired heaters around the world.
Your equation is based on a curve fit. It has NEVER been experimentally verified. Your equation predicts if a planet isn’t rotating it’s at 0 K or absolute zero — even if the planet is 1 meter from a star.
Is what you are claiming is that because the earth is rotating and is absorbing and radiating 240 W/m2, it’s at 288 K — not 255 K?
Unless you want to claim that the S-B equation doesn’t work for non-rotating planets — Actually, you do. You claim that a non-rotating planet is at 0 K — let’s see what the S-B equation has to say about a non-rotating planet.
I’m going to assume that the earth is absorbing and emitting 240 W/m2 rotating or not. For a non-rotating earth that works out to a blackbody temperature of 255 K. The amount of energy that must be absorbed and emitted for a temperature of 288 K is:
240(288/255)**4 = 390 W/m2
Rotating or not a planet radiates energy the same way — by conversion of molecular kinetic energy to radiant energy. That’s governed by Planck’s equation from which the S-B equation is derived. Rotating or not a planet must radiate 390 W/m2 to have a temperature of 288 K. Rotating or not the earth is only capable of absorbing 240 W/m2 maximum at current solar insolation. How does rotating a planet magically produce 150 W/m2?
JJBraccili
” I believe the answer to your question is Tdark2 =107.”
ME:
“So for n1 the Tmean = (200K +100K) /2 = 150K
And for n2>n1 the Tmean = (199+107) /2 = 153K
Doesn’t that clearly demonstrate the faster rotating planet (everything else equals) is on average warmer?”
YOU:
“All that proves is that you get a non-linear temperature response from the S-B equation. The energy balance is not a function of rotation, and it stays in balance during any change in rotation. That’s what my example proved.”
Yes, the energy balance is not a function of rotation, and it stays in balance during any change in rotation. I never said otherwise.
When planet surface is solar irradiated the EM energy interacts with matter. On that very instant the followings happen:
REFLECTION AND EMISSION !!!
1). The reflected portion of the incident solar flux’s SW EM energy (specularly and diffusely) goes out on the same very instant solar flux hits the surface.
2), Transformation into IR EM emission energy.
The transformed portion of the incident solar flux’s SW EM energy also goes out on the same instant instant solar flux hits the surface.
3). Only a very small fraction of the incident solar flux’s SW EM energy gets accumulated in the inner layers on the same very instant solar flux hits the surface.
When rotating faster the amount of energy accumulated in inner layers is still a very small fraction of the incident solar flux’s SW EM energy, but it is larger, than for the slower rotation.
It should be noticed, we observe a different kind of emitting behavior from the solar lit side compared to the dark side.
1). From the solar lit side the outgoing IR emission occurs because of solar flux’s not reflected portion, when interacted with surface’s matter, the on the same very instant partial transformation from SW into IR outgoing EM energy.
2).From the dark side the outgoing IR emission occurs according to the blackbody emission σT^4 Stefan-Boltzmann emission law.
There is no any other source of energy… When rotating faster, planet is warmer, because there is a different IR outgoing EM energy distribution.
https://www.cristos-vournas.com
“Yes, the energy balance is not a function of rotation, and it stays in balance during any change in rotation. I never said otherwise.”
Finally!!!! GAME OVER!!!!!
In thermodynamic terms, a planet is a closed system. A temperature change is a state change. That means for a planet to go from one temperature to another, it’s internal energy has to change. By the first law of thermodynamics, for the internal energy to change the energy absorbed by a planet cannot be equal to the energy emitted.
Now what? You want to claim that your “equation” disproves the first law of thermodynamics?
The rest of it is psychobabble.
Yes, the incoming radiation is short wave radiation and the outgoing radiation is long radiation, but the quantity of energy absorbed and emitted is the same. Your argument is the same as saying if energy moves from the equator to the north pole the temperature of the planet drops . At the equator, the temperature is lower, at the north pole the temperature is the same but ice melted. If you average the temperature change at the north pole and the equator, you have a lower average temperature. Did the temperature of the planet drop? NO!!!!!!!!!! Why? Because at sometime the process will reverse and ice will melt and the temperature of the equator will increase. Climate change is long term, short term aberrations do not impact it.
JJBraccili
” if energy moves from the equator to the north pole the temperature of the planet drops.”
It is not like this. Exactly the opposite happens. When energy moves from Equator to Poles the planet mean surface temperature rises. In this case, again, the non-linearity of Stefan-Boltzmann emission law is what determines the planet surface temperature distribution profile.
https://www.cristos-vournas.com
Don’t embarrass yourself.
The point was moving energy around does not create energy and does not change the temperature of the planet. Just because you see a temperature change on one part of the planet and not a response somewhere else does not mean the planet has warmed or cooled. Nonlinear responses occur all the time.
You took a nonlinear response in temperature and thought it meant a planet’s temperature changed. It does not.
“When energy moves from Equator to Poles the planet mean surface temperature rises. In this case, again, the non-linearity of Stefan-Boltzmann emission law is what determines the planet surface temperature distribution profile.”
What does that matter? The surface radiates more energy. Temporarily, the temperature of the planet drops. It starts to radiate less energy. It is now out of energy balance with input energy. The planet temperature rises to exactly the same temperature it was before. You think that’s significant?
Here is a clear example:
Mars is irradiated 2,32times weaker than Moon, but Mars rotates 28,783 times faster.
And… for the same albedo, Mars and Moon would have the same satellite measured mean temperatures.
For Moon Tmean = 220K Moon’s Albedo a=0,11
For Mars Tmean= 210K Mars’ Albedo a=0,25
Moon is at R = 1 AU distance from the sun and the solar flux on the top is So = 1.361 W/m² ( it is called the Solar constant).
Mars is at 1,524 AU distance from the sun and the solar flux on the top is S = So*(1/R²) = So*(1/1,524²) = So*1/2,32 .
S = 1.361 W/m² /2,32 = 587 W/m².
It is very much obvious the Mars’ fast rotation makes Mars’ average surface (mean) temperature almost the same as Moon’s.
On Moon solar flux is 1.361 W/m²
On Mars solar flux is 587 W/m²
Nevertheless
Tmean.moon = 220K
Tmean.mars = 210 K
https://www.cristos-vournas.com
No, it doesn’t. I’ve read that CO2 in the Martian atmosphere increases the temperature of Mars by 5 – 8 degree C. There could be other factors involved. I’m not going to spend any time sorting it out.
Every time you can’t explain why your theory isn’t BS, you change the subject with another meaningless calculation.
The method I use is the Planet Temperatures Comparison.
The mathematic abstraction formula
(1-a)S /4
gives for Earth average=240 W/m²
for Moon average
(1-0,11)1.361 /4 = 303 W/m² (it is almost 3 times higher than for Mars)
for Mars average
(1-0,25)587 /4 = 110 W/m²
On Mars: “The resulting mean surface pressure is only 0.6% of that of Earth 101.3 kPa (14.69 psi).” (From Wikipedia)
What I think, is that Mars’ less than 1% of Earth’s atmosphere is not capable to absorb and then back to surface radiate almost twice the amount of solar flux hitting Mars’ surface.
It is the Planet Surface Rotational Warming Phenomenon which does the work.
Like-wise it happens on Earth too. Only Venus has strong greenhouse effect. Earth, compared to Venus has a very thin atmosphere…
https://www.cristos-vournas.com
You also think that there is no greenhouse effect in the earth’s atmosphere. I have evidence that says otherwise.
You also claimed that Mars had more CO2 molecules in its atmosphere than the earth. If that’s so, then it’s reasonable to believe that if CO2 molecules have an impact in earth’s atmosphere, they have an impact in Mars’ atmosphere. I have spectrographic evidence that they do.
Let’s get this straight. All you have is a theory and equation with no experimental data to back it up. You fit up some data to the “equation” and now you claim you have created a whole new science. How idiotic does that sound?
I will thank you for an important and interesting paper. The energy imbalance of the earth is the most central issue of global climate change.
But there are some numbers that I have some trouble in understanding. It is about longwave radiation at TOA. You say that there is a growing chilling LW TOA (out) of 1,1 W/m2. And in the TOA radiation energy bridge-chart (figure 14) this is shown as LW clear sky increase of 0,46 W/m2 and LW cloudy areas increase of 0,64 W/m2. As I understand it, it is for the period 2001 to 2020.
But when the CERES data is presented, it has different numbers. In figure 6 you show the Outgoing longwave flux (TOA) over “Clear Sky” and “Cloudy Areas”. Here the numbers are LW increase over clear sky of about 0,1 W/m2 and LW increase over cloudy areas is about 0,7 W/m2 over the same period. In figure 2 you show the increasing trend of the LW flux, and say «the average effect is +0.6 ± 0.2 W/m2 for two decades.»
I wonder what I have missed from your paper. I want to present the CERES data and your work, but i find it difficult to interpret.
NK: I haven’t fully understood this data and tried to incorporate it into a larger understanding, either here or at SOD. The first thing to remember is that Verhenholt and Dubal think unforced/internal variability likely plays and important role in the past 20 years they have studied. In other words, they don’t think this is what would be observed during the average climate model realization for the last 20 years. In other words, their work may not have big implications for global warming.
I just wrote a comment below that mentioned DeWitt and Clerbaux, 2018. If you look closely at that data, it appears as if the increase in OLR with surface temperature is higher in the first half of the period than the second half. During this period, we’ve seen a major volcano, two massive El Ninos and a 13 year Pause in warming. IMO, FWIW, 20 years is too short a period to determine anything important about global warming.
Above Edimbukvarevic cited data in a post from AndNowThereIsPhysics showing OLR increasing with increasing surface temperature.
https://andthentheresphysics.wordpress.com/2020/04/30/outgoing-longwave-radiation/
https://andthentheresphysics.files.wordpress.com/2020/04/remotesensing-10-01539-g004.png
The interesting question is: How fast OLR has been increasing with warming? Eyeballing the data gives an increase of 2.0 W/m2 in 3.5 decades or 0.6 W/m2/decade. Most records of surface warming show SURFACE warming of about 0.18 K/decade. (Feedbacks are calculated in reference to surface warming.) That gives an overall LWR feedback of -3.2 W/m2. This would imply that WV and LR feedbacks are near zero, which is improbable.
During seasonal warming each year, OLR increases about 2.2 W/m2/K through both clear and cloudy skies, a value that is known fairly precisely after 35 years of observations from space. If the same increase had been observed in response to global warming over the past 35 years, the increase in LWR would need to have increased by only 1.4 W/m2 over 35 years or 0.4 W/m2/decade. While lower, this slope is not ruled out by the noisy data.
According to AR6 (Table 7.10) Planck + WV + LR feedbacks total -3.22 + 1.25 = -1.97 W/m2/K and cloud feedback is +0.49 W/m2/K with perhaps half in the LWR channel, giving -1.72 W/m2/K of LWR feedback. That would imply that LWR should have increased only 1.1 W/m2 over the past 3.5 decades. This value looks to be on the low side (but perhaps not impossible given that most of the change in OLR was in the first half of the period.
After working this out, I checked on the AndNowThereIsPhysics’s primary source (DeWitt and Clerbaux, 2018). Their value for the slope is 2.93 +/- 0.3 W/m2/K, so my eyeball isn’t too bad. They don’t discuss how they calculated their confidence interval, but I suspect they didn’t take autocorrelation into account. In either case, observed LWR feedback is likely somewhat more negative than predicted by the IPCC from AOGCM.
https://www.mdpi.com/2072-4292/10/10/1539/htm
The fact that the LWR feedback in models isn’t negative enough is most clearly seen when climate models reproduce seasonal warming (which is 3.5 K before anomalies are calculated). This large temperature change makes calculating LWR feedback to seasonal warming more precise and model error unambiguous. Unfortunately, seasonal warming involves warming in the NH (50:50 land:ocean) and cooling in the SH (10:90 land:ocean) and much more warming in polar regions compared with tropical regions compared with the expectations of global warming.
Thank you for your answer and references Franktoo.
But there is much confusing stuff. Dubal and Vahrenholt have a Figure 9 with cloud data and OLR for about 40 years. It is HIRS and CERES data. They say they have the data from WMO Homepage. It looks very questionable, as the OLR data look very different from other OLR data. OLR is increasing over 1 W/m2 per decade. Dewitte and Clerbaux have different numbers and a slope of about 0,5 W/m2 per decade, for much of the same period.
JH said recently
“Some of this stuff is certainly counter intuitive, but (IMHO!) I don’t think you’ve quite got things straight yet.”
True.
Probably a good thing.
Looking at other people and trying to understand their points of view and arguments should lead to greater understanding of one’s own views.
In the case of CERES and TOA I am trying to raise awareness that heat storage as described may have some flaws.
This is not a denial of GHG effects or back radiation which both have substantial science.
It may be as simple as the difference between energy of and energy [heat] stored in a body.
Interchangeable at any one specific moment of time.
Yet one is a permanent feature of all matter stored and unusable.
The other is transient and dependent on an inflow source and an outflow event which physics says has to balance.
Hence objects can get warmer and cool down with more or less energy running through them and yet never actually be a store of that energy in the way that it is a store of it’s own innate unusable energy.
This subtle difference does not mean that the earth does not warm up and cool down with energy changes. Just that using the word imbalance is wrong and justifies a concept of ongoing storage of energy until said imbalance is corrected.
Instead of just calculating the change in energy and saying this results in this distribution of the energy and heat and temperature profile at this time, a concept of a build up in energy over and above what is being put in is used.
Which is flawed reasoning.
angech
“Looking at other people and trying to understand their points of view and arguments should lead to greater understanding of one’s own views.”
Yes, I feel exactly the same!
angech
“Hence objects can get warmer and cool down with more or less energy running through them and yet never actually be a store of that energy in the way that it is a store of it’s own innate unusable energy.”
angech, I think we are on the same page here.
When I compare two identical planets with different rotational spin, the Planet Surface Rotational Warming Phenomenon I describe is based exactly on the above “not storage” principle.
A faster rotating planet “deals” we the same as the slower rotating planet amount of “energy running through them”.
A faster rotating planet is necessarily on average warmer planet, because it is the only way to get rid of the not reflected solar energy (when planet happens to rotate faster) the only way to get the entire not reflected “energy running through them”!
https://www.cristos-vournas.com
Nonsense! You should know better.
Your planet rotation theory is junk science. No amount of “spin” is going to change that.
Give it a rest!
I don’t understand what you are saying. Are you are now saying energy can be stored? That’s a start.
Energy can pass through a body without increasing the energy stored in the body. That occurs if energy being absorbed by a body is equal to what it emits. It is not true that energy in always equals energy out. That means that a body has no inertia to temperature change. We usually express the inertia to temperature in an equation similar to this one.
mCp dT/dt = energy flow in – energy flow out
m – mass of a body
Cp – specific heat of a body
T – Temperature
t – time
energy out is a function of T (think Stefan-Boltzmann equation)
mCp is a measure of a body’s inertia to temperature change.
If there is a change in energy in (solar radiation), the only way that energy out immediately changes is if mCp = 0. That is ridiculous. There would be no change in the temperature of a body no matter how much energy flow in is increased.
JJBraccili
“Your planet rotation theory is junk science. No amount of “spin” is going to change that.”
JJBraccili, when in a radiative equilibrium, a faster rotating planet (everything else equals) should necessarily be a warmer planet!
https://www.cristos-vournas.com
“JJBraccili, when in a radiative equilibrium, a faster rotating planet (everything else equals) should necessarily be a warmer planet!”
Says who? You? You have no evidence of that except for your “theory”. I have already shown that a planet maintains it’s energy balance as it moves from one rotational speed to another. That means the average temperature of the planet remains constant. The local surface temperatures fluctuate, but the average temperature remains constant. All that happens, as you rotate a planet faster and faster, is the local surface temperatures approach the average temperature of the planet, which is the same whether the planet is rotating or not.
JJBraccili | November 19, 2021 at 7:25 pm
“I have already shown that a planet maintains it’s energy balance as it moves from one rotational speed to another. That means the average temperature of the planet remains constant.”
CV
“a faster rotating planet (everything else equals) should necessarily be a warmer planet!”
–
Says who?
Try Effective temperature Wikipedia
It explains how and why an average surface temperature is lower for a stationary planet and increases with rotation so that the average temperature approaches the effective temperature.
The problem is that you are both right on different meanings of average surface temperature and so are talking right past each other.
The energy balance is maintained at different rotational speeds -yes.
Energy out always equals energy in.
but the average energy of the surface varies by a 4 power difference to the temperature of the surface.
This means that for a lit and an unlit side the lit side is putting all the energy out at a slightly higher average temperature for half the surface than nothing on the other side.
Dividing that temperature by 2 gives a lower temperature than that when the planet is rotating so fast that all of the disc is at a uniform temperature approaching the emission temperature and so warmer than the non rotating body.
Although it is putting out the same total energy.
Christos is wrong in using a formula with roots to the 4th power multiplied twice. Nature and maths does not work like that.
He seems to have a variant on the Nikolov theory with the addition of x-factors depending on his definitions of surface and albedo. You cannot shake him loose from his conviction and it carries enough correlation to make some others pay attention to it which is impressive. Nonetheless it is another version of fitting to patterns people want to see.
He is always courteous in his comments which makes disagreeing with him a shame for me.
You’re someone else who just doesn’t get it. I’m not wrong about anything I’m saying on this subject.
CV’s planet rotation theory leads him to conclude that the 33 C difference in the earth’s temperature from what it should be is entirely due to the earth’s rotation. Do you believe that as well?
“Try Effective temperature Wikipedia
It explains how and why an average surface temperature is lower for a stationary planet and increases with rotation so that the average temperature approaches the effective temperature.”
That article confused me for a bit. Usually, the correction in luminosity for distance from a star is not included in the equation for temperature. It’s done separately because it’s constant. His final equation should read:
T = ( Aabs/Arad L (1-a) / oe )**0.25 Where L is the corrected luminosity. The equations are equivalent; it’s odd to see it written that way.
“Note the ratio of the two areas. Common assumptions for this ratio are 1/4 for a rapidly rotating body and 1/2 for a slowly rotating body, or a tidally locked body on the sunlit side.”
That says the surface temperature of the planet on the hot side approaches average temperature of the planet for a rapidly rotating planet, which is the same temperature for the planet if it wasn’t rotating. That’s exactly what I said. That’s not what CV is saying.
“The energy balance is maintained at different rotational speeds -yes.”
That is meaningless. What is important is if the energy balance is maintained as a planet transitions from one rotational speed to another. I proved it does. That means the average temperature of a planet is independent of rotational speed.
“Energy out always equals energy in.”
If rotation is the cause of a rise in the planet’s average temperature, that can’t be true while the planet is in transition to a rotational speed. The fact that it is means a planet’s rotation has nothing to do with the planet’s average temperature.
“This means that for a lit and an unlit side the lit side is putting all the energy out at a slightly higher average temperature for half the surface than nothing on the other side.”
That’s NONSENSE! The entire planet radiates energy — cold side and hot side. Does the cold side have a temperature? Then it radiates energy.
“Dividing that temperature by 2 gives a lower temperature than that when the planet is rotating so fast that all of the disc is at a uniform temperature approaching the emission temperature and so warmer than the non rotating body.
Although it is putting out the same total energy.”
That’s a word salad. It is meaningless.
“He is always courteous in his comments which makes disagreeing with him a shame for me.”
Courteous or not, he is peddling junk science. That does a disservice to everyone.
https://www.drroyspencer.com/2016/09/the-faster-a-planet-rotates-the-warmer-its-average-temperature/#comment-964165
JJBraccili says:
November 1, 2021 at 7:00 PM
The temperature of a planet is not a function of rotation. The temperature remains constant no matter how fast it spins.
Let all T’s be the temperature raised to the fourth power. Let Ts be the hot source temperature. Let Th be the planet’s hot side temperature. Let Tc be the planet’s cold side temperature. k is the Stefan-Boltzman constant x emissivity. Start with a non-rotating planet at steady-state. From the Stefan-Boltzman equation”
Heat absorbed on the hot side = k(Ts – Th)
Heat emitted on the cold side = kTc
at steady-state k(Ts – Th) = kTc
Therefore, Tc = Ts – Th
Rotate the planet 180 degrees so the cold side faces the sun and the hot side faces outer space.
heat absorbed on the hotside = k(Ts – Tc), but Tc = Ts – Th
heat absorbed on the hotside = kTh
heat emitted on the cold side = kTh
heat absorbed on the hot side = heat emitted on the cold side. The planet remains in energy balance and the temperature of the planet can not change.
As you rotate the planet, and an increment of cold side faces the sun, the same amount of hot side faces outer space. The planet remains in energy balance and no matter how fast you rotate the planet, its temperature will not change.
So?
JJBraccili
“Let all T’s be the temperature raised to the fourth power. Let Ts be the hot source temperature. Let Th be the planet’s hot side temperature. Let Tc be the planet’s cold side temperature. k is the Stefan-Boltzman constant x emissivity. ”
Please, JJBraccili, would you like to clarify what T is?
Is it T raised to the fourth power, or is it just the surface temperature ?
https://www.cristos-vournas.com
I think it’s pretty clear. Whenever you see T (Ts, Th, Tc) in the equations it is T raised to the fourth power. That should be obvious.
Ok, let’s see now:
“Heat absorbed on the hot side = k(Ts – Th)
Heat emitted on the cold side = kTc
at steady-state k(Ts – Th) = kTc
Therefore, Tc = Ts – Th
Rotate the planet 180 degrees so the cold side faces the sun and the hot side faces outer space.
heat absorbed on the hotside = k(Ts – Tc), but Tc = Ts – Th
heat absorbed on the hotside = kTh
heat emitted on the cold side = kTh”
You say at steady-state:
“Heat emitted on the cold side = kTc”
So, the temperature of the cold side at steady-state should be:
( kTc)¹∕ ⁴ the cold side steady-state temperature
or
(kTs – kTh)¹∕ ⁴
Next, after rotating planet 180 degrees:
“heat emitted on the cold side = kTh”
So, the temperature of the cold side, after rotating planet 180 degrees, should be:
(kTh)¹∕ ⁴
After rotating planet 180 degrees, the cold side temperature rise ΔΤc is:
ΔΤc = (kTh)¹∕ ⁴ – (kTs – kTh)¹∕ ⁴ ≠ 0
I didn’t check your math because it doesn’t matter. The point is the when you rotate the planet 180 degrees, the energy absorbed = the energy emitted. By the First Law of Thermodynamics, the Internal Energy cannot change and the temperature of the planet cannot change. Makes no difference what Tc and Th do.
If rotation affects planetary temperature, energy absorbed cannot equal energy emitted when the planet is in an unsteady state. When I rotated the planet 180 degrees and forced it into an unsteady state energy in still equals energy out, I never said the change in cold side temperature has to be zero. Neither did I say the change in hot side temperature has to be zero. It obviously doesn’t because the hot side temperature is now Tc and the cold side temperature is now Th.
BTW if all I did was rotate the planet 180 degrees, at steady state, the surface temperatures would be identical to the temperatures before I rotated the planet 180 degrees.
JJBraccili | November 20, 2021
“You’re someone else who just doesn’t get it. I’m not wrong about anything I’m saying on this subject.” Of course not.
CV’s planet rotation theory leads him to conclude that the 33 C difference in the earth’s temperature from what it should be is entirely due to the earth’s rotation. Do you believe that as well?”
No
“Try Effective temperature Wikipedia
It explains how and why an average surface temperature is lower for a stationary planet and increases with rotation so that the average temperature approaches the effective temperature.”
“That article confused me for a bit.” As it should.
“Note the ratio of the two areas. Common assumptions for this ratio are 1/4 for a rapidly rotating body and 1/2 for a slowly rotating body, or a tidally locked body on the sunlit side.”
“That says the surface temperature of the planet on the hot side approaches average temperature of the planet for a rapidly rotating planet”
Correct
The average temp of a non spinning world is the temp for all the energy in half the area divided by 2 [none from the other half.]
The average temp of a rapidly spinning world is higher as all the energy is now spread over twice the area.
SB dictates that this is higher.
It radiates the same amount of energy out at a higher average temperature.
The higher temp on the hot side only , decreases towards the average temp of a rapidly rotating planet.
The no temp on the cold side goes up to the average temperature by much more than the warm side falls hence the sum of the two temperatures is much higher than half the single temperature
“which is the same temperature for the planet if it wasn’t rotating.”
Not at all.
“The energy balance is maintained at different rotational speeds”
-yes.
What is important is if the energy balance is maintained as a planet transitions from one rotational speed to another.
yes
I proved it does.
great
“That means the average temperature of a planet is independent of rotational speed.”
No, The average temperature increases towards the emission temperature of a black body [highest] or extremely fast rotating planet [next best] as the planet goes from stationary [lowest average surface temperature].
Energy out always equals energy in
“The entire planet radiates energy — cold side and hot side. Does the cold side have a temperature? Then it radiates energy.”If the cold side does not receive any energy directly , and for a stationary planet this is the actual situation, then the cold side remains cold. zero Kelvin,
All the energy radiates from the hot side.
Not real life, we all know, but that is what we mean when we say half a planet does not receive any direct energy.
None.
We do not specify the make up or conductivity of a planet just the energy flow.in and out in an ideal situation.
“He is always courteous in his comments which makes disagreeing with him a shame for me.”
“Courteous or not, he is peddling junk science. That does a disservice to everyone.”
He is commentating on his ideas of what the science may be. He is most likely wrong in some areas but he is thinking, not parroting. You could be courteous in pointing out where you think he is wrong.
On the effect of rotation compared to non rotation on the average surface temperature of a planet Which most reasonable people would consider the temperature layer we live in and on he is correct, up to the point where average surface temperature equals emissivity to space.
This is really getting boring. Your lack of understanding of thermodynamics has no bound. I’ll make it really simple.
The first law of thermodynamics states:
The change in internal energy = energy in – energy out
If the internal energy of a planet doesn’t change, the temperature of a planet can’t change. That’s about as fundamental as it gets in science.
You claim that energy in always equals energy out. If that’s true, the internal energy of planet can’t change and its temperature can’t change. Yet, you claim somehow it does. That’s about as ridiculous as it gets.
What I proved is that the energy in always equals the energy out when a planet transitions from no rotation to rotation. That means the planet’s temperature can’t change. Rotation has no impact on the average planetary temperature. Local surface temperatures can vary, but not the average planetary temperature. It’s the same whether the planet is rotating or not.
Try and PROVE what I said is wrong. Don’t just state it and talk about hot side cold side temperatures. They are irrelevant what matters is the energy balance.
“If the cold side does not receive any energy directly , and for a stationary planet this is the actual situation, then the cold side remains cold. zero Kelvin,
All the energy radiates from the hot side.
Not real life, we all know, but that is what we mean when we say half a planet does not receive any direct energy.
None.
We do not specify the make up or conductivity of a planet just the energy flow.in and out in an ideal situation.”
That is a lot of tap dancing and complete BS. No matter in the universe is at absolute zero. All matter radiates energy. Planets aren’t even close and I don’t know of anyone, but you, who claims this — ideal case or not.
I propose here an entirely new approach to the planetary surface without-atmosphere temperatures calculation.
What we have till now is the satellite precisely measured planetary mean surface temperatures.
What I have discovered is the “Planet Surface Rotational Warming Phenomenon”.
Based on that Phenomenon I have discovered the Planet Mean Surface Temperature Equation.
The Equation has the wonderful ability to theoretically calculate the solar system planets and moons mean surface temperatures.
The calculated results match almost precisely the satellite measured ones.
1. Earth’s Without-Atmosphere Mean Surface Temperature Calculation:
Tmean.earth
R = 1 AU, is the Earth’s distance from the sun in astronomical units
Earth’s albedo: aearth = 0,306
Earth is a smooth rocky planet, Earth’s surface solar irradiation accepting factor Φearth = 0,47
β = 150 days*gr*oC/rotation*cal – is the Rotating Planet Surface Solar Irradiation INTERACTING-Emitting Universal Law constant
N = 1 rotation /per day, is Earth’s sidereal rotation spin
cp.earth = 1 cal/gr*oC, it is because Earth has a vast ocean. Generally speaking almost the whole Earth’s surface is wet.
We can call Earth a Planet Ocean.
σ = 5,67*10⁻⁸ W/m²K⁴, the Stefan-Boltzmann constant
So = 1.361 W/m² (So is the Solar constant)
Earth’s Without-Atmosphere Mean Surface Temperature Equation Tmean.earth is:
Tmean.earth = [ Φ (1-a) So (β*N*cp)¹∕ ⁴ /4σ ]¹∕ ⁴
Τmean.earth = [ 0,47(1-0,306)1.361 W/m²(150 days*gr*oC/rotation*cal *1rotations/day*1 cal/gr*oC)¹∕ ⁴ /4*5,67*10⁻⁸ W/m²K⁴ ]¹∕ ⁴ =
Τmean.earth = [ 0,47(1-0,306)1.361 W/m²(150*1*1)¹∕ ⁴ /4*5,67*10⁻⁸ W/m²K⁴ ]¹∕ ⁴ =
Τmean.earth = ( 6.854.905.906,50 )¹∕ ⁴ =
Tmean.earth = 287,74 Κ
And we compare it with the
Tsat.mean.earth = 288 Κ, measured by satellites.
These two temperatures, the calculated one, and the measured by satellites are almost identical.
https://www.cristos-vournas.com
Stop posting junk science. There is nothing “wonderful” about it. Wishing something is true doesn’t make it so.
https://judithcurry.com/2021/10/10/radiative-energy-flux-variations-from-2000-2020/#comment-963405
JJBraccili | November 5, 2021 at 10:36 am |
Let me get this straight. What you are now saying is that:
“The planet blackbody equation (effective temperature):
Te = [ (1-a) S /4σ ]¹∕ ⁴
is a mathematical abstraction.
The number it calculates for earth’s effective temperature
Te=255K
is meaningless.”
The S-B equation has been around for over 100 years and has been used whenever radiant energy is involved. It has been experimentally verified. It has been used to design countless of fired heaters around the world. “”
The planet blackbody equation (effective temperature):
Te = [ (1-a) S /4σ ]¹∕ ⁴
is a mathematical abstraction.
It is been around about 40 years only.
And it has not been experimentally verified.
https://www.cristos-vournas.com
“It is been around about 40 years only.
And it has not been experimentally verified
Neither of those statements is true.
https://en.wikipedia.org/wiki/Stefan%E2%80%93Boltzmann_law
I find it ironic that you now want S-B experimentally verified, but the junk science you’ve been peddling does not need experimental verification. It time you give it up and move on to something else. Your theory is going nowhere.
JJBraccili
“Neither of those statements is true.
https://en.wikipedia.org/wiki/Stefan%E2%80%93Boltzmann_law
”
Thank you for a good and informative link. It has not any mention of the planet blackbody equation (effective temperature):
Te = [ (1-a) S /4σ ]¹∕ ⁴
Not a single word referring the equation to Stefan or to Boltzmann themselves!
Here it is what the above link states on the matter:
“Temperature of the Sun
With his law Stefan also determined the temperature of the Sun’s surface.[8] He inferred from the data of Jacques-Louis Soret (1827–1890)[9] that the energy flux density from the Sun is 29 times greater than the energy flux density of a certain warmed metal lamella (a thin plate). A round lamella was placed at such a distance from the measuring device that it would be seen at the same angle as the Sun. Soret estimated the temperature of the lamella to be approximately 1900 °C to 2000 °C. Stefan surmised that ⅓ of the energy flux from the Sun is absorbed by the Earth’s atmosphere, so he took for the correct Sun’s energy flux a value 3/2 times greater than Soret’s value, namely 29 × 3/2 = 43.5.”
https://www.cristos-vournas.com
“Thank you for a good and informative link. It has not any mention of the planet blackbody equation (effective temperature):
Te = [ (1-a) S /4σ ]¹∕ ⁴
Not a single word referring the equation to Stefan or to Boltzmann themselves!”
LOL.
Now you claim it didn’t mention the blackbody equation to calculate planetary temperature then you quote where it says that in the 19th century it was used to calculate the temperature of the sun, when they had no way of measuring what the actual solar irradiance was. By the way Stefan corrected for the albedo and atmospheric absorption.
What’s really ironic is that you use the Stefan-Boltzmann equation in your planet rotation equation. By trying to discredit the Stefan-Boltzmann equation to calculate planetary temperatures, you discredit your own equation. You don’t even realize it.
Either way your theory is still junk science.
JJBraccili
“What’s really ironic is that you use the Stefan-Boltzmann equation in your planet rotation equation. By trying to discredit the Stefan-Boltzmann equation to calculate planetary temperatures, you discredit your own equation. You don’t even realize it.”
https://www.cristos-vournas.com
JJBraccili
“The first law of thermodynamics states:
The change in internal energy = energy in – energy out
If the internal energy of a planet doesn’t change, the temperature of a planet can’t change. That’s about as fundamental as it gets in science.
You claim that energy in always equals energy out. If that’s true, the internal energy of planet can’t change and its temperature can’t change. Yet, you claim somehow it does. That’s about as ridiculous as it gets.”
JJBraccili, what you do here is to confuse solar flux’s W/m² with heat’s cal.
W/m² is not cal/m²…
When we say for Planet Radiative Energy Budget
energy in = energy out
then what we refer to is the radiative energy.
Radiative energy is measured in W/m² unit.
W/m² is radiative energy intensity measure, it is not an amount of heat added to planetary surface, as you might think.
The not reflected portion of the incident on the planet surface radiative energy does not get ENTIRELY absorbed AS HEAT .
What radiative energy does is to INTERACT with the surface’s matter.
The planet average surface specific heat cp and the planet rotational spin N are of the major factors in the “radiative energy – planet surface” INTERACTION PROCESS.
In planetary surface Radiative Equilibrium the entire incident solar radiative energy is re-radiated out.
1). On the spot and on the very instant the partial SW Reflection (specular and diffuse) of the incident radiative flux.
2). On the spot and on the very instant IR emission of a transformed from SW into LW fraction of the not reflected portion.
3). On the very instant and on the spot the rest of the not reflected and not IR emitted solar radiative energy gets accumulated in form of heat in the surface’s inner layers.
The amount of heat accumulated in the surface’s inner layers will later (at the night time hours), it will also be IR emitted as outgoing energy.
The amount of heat accumulated in the surface’s inner layers is what varies for planet’s variations of “the planet average surface specific heat cp and the planet rotational spin N” products.
When INTERACTING with planetary surface the energy is reflected, IR emitted and accumulated at the same time. Only a fraction of EM energy is accumulated in form of HEAT for the later IR emission.
When at nighttime hours surface does not interact with solar flux. At nighttime hours surface emits IR EM radiative energy as the Stefan-Boltzmann emission law requires. Surface’s spots emit at nighttime hours as previously warmed blackbody spots which they are then.
Conclusion:
There is not any violation of The first law of thermodynamics, when a faster rotating planet appears to be on average surface a warmer planet.
https://www.cristos-vournas.com